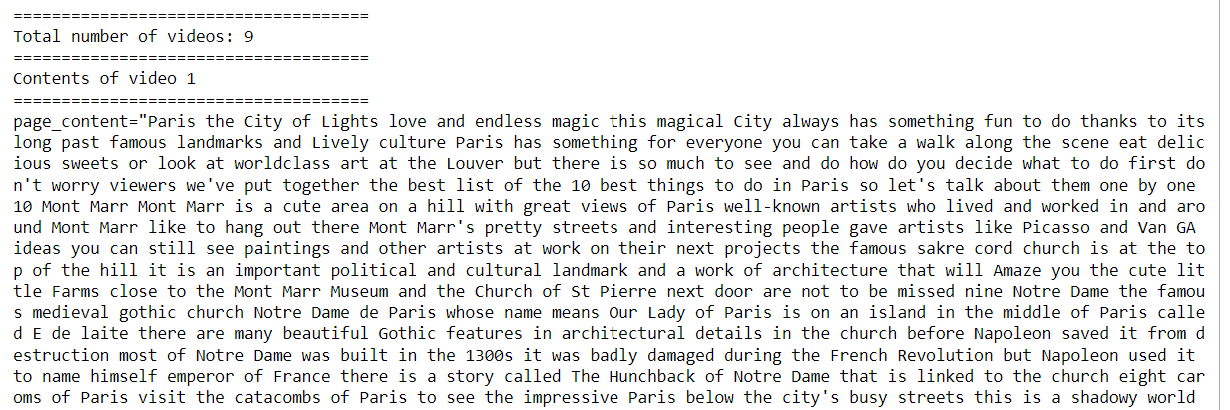
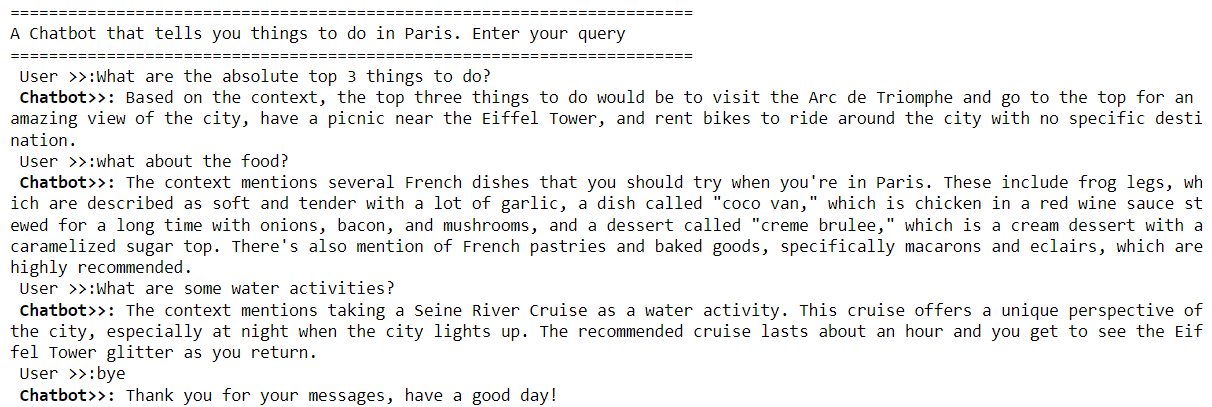
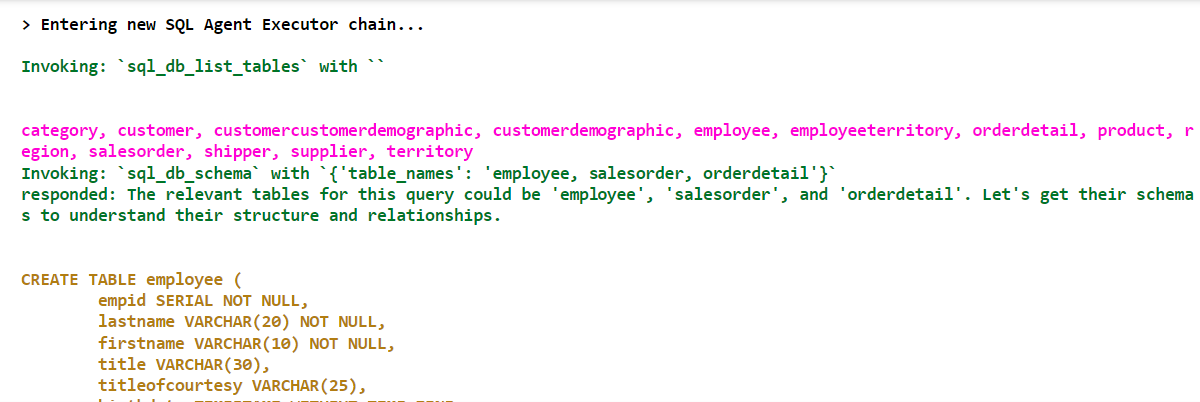
In previous articles, I explained how to use natural language to interact with PDF documents and SQL databases, using the Python LangChain module and OpenAI API.
In this article, you will learn how to use LangChain and OpenAI API to create a question-answering application that allows you to retrieve information from YouTube videos. So, let's begin without ado.
Before diving into the code, let's set up our environment with the necessary libraries.
We will use the Langchain module to access the vector databases and execute queries on large language models to retrieve information about YouTube videos. We will also employ the YouTube Transcript API for fetching video transcripts, the Pytube library for downloading YouTube videos, and the FAISS vector index for efficient similarity search in large datasets.
The following script installs these modules and libraries.
!pip install -qU langchain
!pip install -qU langchain-community
!pip install -qU langchain-openai
!pip install -qU youtube-transcript-api
!pip install -qU pytube
!pip install -qU faiss-cpu
The script below imports the required libraries into our Python application.
from langchain_community.document_loaders import YoutubeLoader
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain_core.documents import Document
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
import os
The first step involves converting …