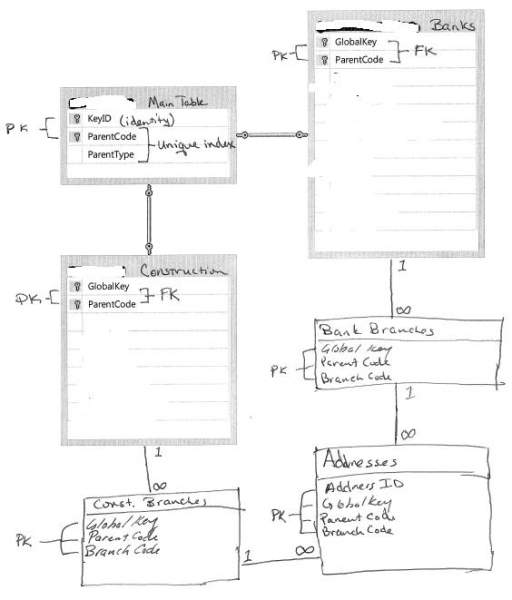
I am in desperate need of some guidance here. Any suggestions or ideas would be very much appreciated!
Is it possible to have a relationship based on two columns? For example:
The table "Parents" has columns:
ParentID (PK)
The table "Children" has columns:
ChildID (PK)
ParentID
The table "Addresses" has columns:
ChildID
ParentID
Address
City
State
Zip
The table "SchoolDistricts" has columns:
ChildID (PK) (Don't let "Child" fool you, it has nothing to do with the Child, it's a "child" of a "Parent" School)
ParentID (there's another table called Schools that is related to this column)
(I know, it's a lame (and probably confusing) example, but the question remains)
Is it possible to create a relationship between the Addresses table and the Children table using BOTH ChildID and ParentID, as well as a relationship between the SchoolDistricts table and the Addresses table using BOTH ChildID and ParentID?
Maybe it's poor design? Is there a better way to do this maybe?
I need to have relationships set up similar to this:
One "Parent" can have many "Children"
One "Child" can have many "Addresses" (amuse me, it happens)
One "School District" can have many "Addresses"
Am I going about this the wrong way? Do I need two tables instead? One to store Children addresses and one to store School District addresses? Seems silly to do that considering they really would have the exact same columns?