Introduction
In a previous article, I explained how to fine-tune the vision transformer model for image classification in PyTorch. In this article, I will explain how to fine-tune the pre-trained OpenAI Whisper model for audio classification in PyTorch.
Audio classification is an important task that can be applied in various scenarios, such as speech dialogue detection, sentiment analysis, music genre recognition, environmental sound identification, etc.
OpenAI Whisper is an excellent model for audio classification that achieved state-of-the-art results on several benchmarks. It is based on the transformer architecture and uses self-attention to process audio inputs. OpenAI Whisper can recognize speech and audio from different languages, accents, and domains with high accuracy and robustness.
In this article, you will see how to classify various sounds by fine-tuning the OpenAI Whisper model from Hugging Face in the PyTorch deep learning library. You will learn how to load the pre-trained model, prepare a custom audio dataset, train the model on the dataset, and evaluate the model performance. Let’s get started!
Note: All the scripts in this article are executed in a Google Colab notebook.
Importing Required Libraries
To execute the scripts in this article, you must install the Hugging Face Transformers library.
! pip install accelerate -U
! pip install datasets transformers[sentencepiece]
The following script imports the necessary Python libraries and modules you need to execute the Python codes in this article.
import datasets
from datasets import load_dataset, DatasetDict, Audio
import pandas as pd
import os
import glob
import librosa
import io
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, classification_report, accuracy_score
from transformers import WhisperModel, WhisperFeatureExtractor, AdamW
import torch
import torch.nn as nn
import torch.utils.data
from torch.utils.data import Dataset, DataLoader
from datasets import load_dataset
from sklearn.metrics import f1_score, classification_report, accuracy_scoreImporting the datasets
This article will use the UrbanSound8K dataset from Kaggle. The dataset consists of audio files containing ten different sound categories. The audio files are located in 10 different folders. It is important to note that each folder may contain audio files belonging to all the categories. A CSV file is also downloaded with the dataset, containing details of each audio file.
The following script imports the CSV file into a Pandas DataFrame. The original dataset contains more than 8 thousand records. However, for the sake of experiments in this article, I randomly selected 2000 records.
audio_df = pd.read_csv(r"/content/urbansound8k/UrbanSound8K.csv")
audio_df = audio_df.sample(n=2000, random_state=42)
audio_df.head()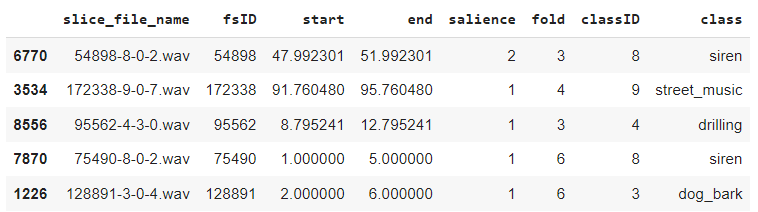
The slice_file_name column in the above DataFrame contains the audio file name. The classID and class columns contain corresponding class IDs and names.
Let's print the class distribution.
audio_df["class"].value_counts()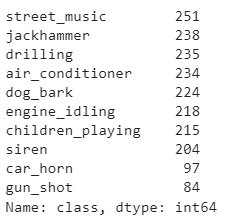
You can see different sound categories in the dataset, e.g., street music, dog bark, siren, etc.
Next, we will create a column in the Pandas DataFrame containing the audio files' full path. To do so, we will first write a method that creates a dictionary mapping the audio file names to their corresponding full paths. Using this method, we will populate the full_path column in the audio_df DataFrame with the full paths of the audio files.
The get_all_full_paths() method in the following script returns a dictionary that maps the audio file names to their corresponding full paths.
def get_all_full_paths(parent_directory):
# List to store file paths
audio_file_paths = []
# Iterate through audio folders (assuming they are named fold1, fold2, ..., fold10)
for folder_name in range(1, 11):
folder_path = os.path.join(parent_directory, 'fold{}'.format(folder_name))
# Iterate through files in the current folder and add their paths to the list
for filename in os.listdir(folder_path):
if filename.endswith('.wav'): # Assuming your audio files have .wav extension
file_path = os.path.join(folder_path, filename)
audio_file_paths.append(file_path)
# Create a dictionary to map base name to full_path
file_path_dict = {os.path.basename(path): path for path in audio_file_paths}
return file_path_dict
audio_files_directory = '/content/urbansound8k'
file_path_dict = get_all_full_paths(audio_files_directory)
Next, we will define the get_single_full_path() method, which accepts the file name as a parameter and returns the corresponding full path from the dictionary returned by the get_all_full_paths() method. Subsequently, we will create a new column full_path in the audio_df DataFrame and use it's apply() method to store full paths in the full_path column.
def get_single_full_path(slice_file_name):
return file_path_dict.get(slice_file_name)
# Add 'full_path' column to the DataFrame
audio_df['full_path'] = audio_df['slice_file_name'].apply(get_single_full_path)
audio_df.head()
Finally, we will split our dataset into training (70%), validation (15%), and test (15%) sets.
train_df, temp_df = train_test_split(audio_df, test_size=0.3, random_state=42)
val_df, test_df = train_test_split(audio_df, test_size=0.5, random_state=42)Creating a PyTorch Dataset
The next step involves creating a PyTorch dataset. However, before that, we will create Hugging Face datasets using our audio files and labels.
This process converts the audio files into numeric arrays that you can pass to Hugging Face transformer models. You can create a Hugging Face dataset using the datasets.Dataset.from_dict() method. Pass the full path of the audio files to the audio key and cast the audios to a sampling rate of 16khz, the default sampling rate for the Hugging Face Whisper model. In addition, we will create a key for our target labels as well.
The following script creates Hugging Face datasets for train, test, and validation splits in our dataset.
train_audio_dataset = datasets.Dataset.from_dict({"audio": train_df["full_path"].tolist(),
"labels": train_df["classID"].tolist() }
).cast_column("audio", Audio(sampling_rate=16_000))
test_audio_dataset = datasets.Dataset.from_dict({"audio": test_df["full_path"].tolist(),
"labels": test_df["classID"].tolist() }
).cast_column("audio", Audio(sampling_rate=16_000))
val_audio_dataset = datasets.Dataset.from_dict({"audio": val_df["full_path"].tolist(),
"labels": val_df["classID"].tolist() }
).cast_column("audio", Audio(sampling_rate=16_000))You can use the dataset above for training with the Hugging Face trainer. However, we need to create a PyTorch dataset since we want to fine-tune the Whisper model in PyTorch.
You must extract audio features from your audio files to train a Whisper model. The WhisperFeatureExtractor object accomplishes this job.
The script below creates a Hugging Face Whisper model object and a WhisperFeatureExtractor object from the openai/whisper-base checkpoint. You can choose any other Whisper model checkpoint from Hugging Face if desired.
The code is configured to utilize the GPU if CUDA is available. Otherwise, it defaults to running on the CPU.
model_checkpoint = "openai/whisper-base"
feature_extractor = WhisperFeatureExtractor.from_pretrained(model_checkpoint)
encoder = WhisperModel.from_pretrained(model_checkpoint)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
To create a PyTorch dataset for our problem, will define the SpeechClassificationDataset class that inherits the torch.utils.data.Dataset class. The SpeechClassificationDataset class returns the input features and decoder inputs for the Whisper model, along with the target labels.
class SpeechClassificationDataset(torch.utils.data.Dataset):
def __init__(self, audio_data, text_processor):
self.audio_data = audio_data
self.text_processor = text_processor
def __len__(self):
return len(self.audio_data)
def __getitem__(self, index):
inputs = self.text_processor(self.audio_data[index]["audio"]["array"],
return_tensors="pt",
sampling_rate=self.audio_data[index]["audio"]["sampling_rate"])
input_features = inputs.input_features
decoder_input_ids = torch.tensor([[1, 1]]) * encoder.config.decoder_start_token_id
labels = np.array(self.audio_data[index]['labels'])
return input_features, decoder_input_ids, torch.tensor(labels)
Using the below script, we can transform our train_audio_dataset, test_audio_dataset, and val_audio_dataset Hugging Face datasets into PyTorch datasets. To process the datasets in batches, we create corresponding DataLoader objects with a batch size of 8.
train_dataset = SpeechClassificationDataset(train_audio_dataset, feature_extractor)
test_dataset = SpeechClassificationDataset(test_audio_dataset, feature_extractor)
val_dataset = SpeechClassificationDataset(val_audio_dataset, feature_extractor)
batch_size = 8
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)Fine Tuning Hugging Face Whisper Model
We are now prepared to fine-tune the Hugging Face Whisper model on our PyTorch dataset. To achieve this, we will design a model class that takes the Whisper model encoder as a parameter and passes the encoder's output through five dense layers (4096, 2048, 1024, and 512 neurons). The final dense layer will have ten labels, reflecting our ten target classes.
class SpeechClassifier(nn.Module):
def __init__(self, num_labels, encoder):
super(SpeechClassifier, self).__init__()
self.encoder = encoder
self.classifier = nn.Sequential(
nn.Linear(self.encoder.config.hidden_size, 4096),
nn.ReLU(),
nn.Linear(4096, 2048),
nn.ReLU(),
nn.Linear(2048, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, num_labels)
)
def forward(self, input_features, decoder_input_ids):
outputs = self.encoder(input_features, decoder_input_ids=decoder_input_ids)
pooled_output = outputs['last_hidden_state'][:, 0, :]
logits = self.classifier(pooled_output)
return logits
In the following script, we will instantiate an object of the SpeechClassifier class, specifying the number of labels (10 in our case), along with the loss function and optimizer.
num_labels = 10
model = SpeechClassifier(num_labels, encoder).to(device)
optimizer = AdamW(model.parameters(), lr=2e-5, betas=(0.9, 0.999), eps=1e-08)
criterion = nn.CrossEntropyLoss()Training the Model
To train the model, we define the train() method and pass it the model, train and validation data loaders, optimizer, criterion (loss function), device, and the number of epochs as parameters. The train() method executes the training loop and prints the loss for each batch.
# Define the training function
def train(model, train_loader, val_loader, optimizer, criterion, device, num_epochs):
best_accuracy = 0.0
for epoch in range(num_epochs):
model.train()
for i, batch in enumerate(train_loader):
input_features, decoder_input_ids, labels = batch
input_features = input_features.squeeze()
input_features = input_features.to(device)
decoder_input_ids = decoder_input_ids.squeeze()
decoder_input_ids = decoder_input_ids.to(device)
labels = labels.view(-1)
labels = labels.to(device)
optimizer.zero_grad()
logits = model(input_features, decoder_input_ids)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
if (i+1) % 8 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {i+1}/{len(train_loader)}, Train Loss: {loss.item() :.4f}')
train_loss = 0.0
val_loss, val_accuracy, val_f1, _ , _ = evaluate(model, val_loader, device)
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
torch.save(model.state_dict(), 'best_model.pt')
print("========================================================================================")
print(f'Epoch {epoch+1}/{num_epochs}, Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}, Val F1: {val_f1:.4f}, Best Accuracy: {best_accuracy:.4f}')
print("========================================================================================")
After every epoch, the train() method displays the loss, accuracy, and F-1 score on the validation set using the evaluate() method, defined in the subsequent script. Finally, the train() method saves the model with the highest accuracy on the validation set.
def evaluate(model, data_loader, device):
all_labels = []
all_preds = []
total_loss = 0.0
with torch.no_grad():
for i, batch in enumerate(data_loader):
input_features, decoder_input_ids, labels = batch
input_features = input_features.squeeze()
input_features = input_features.to(device)
decoder_input_ids = decoder_input_ids.squeeze()
decoder_input_ids = decoder_input_ids.to(device)
labels = labels.view(-1)
labels = labels.to(device)
optimizer.zero_grad()
logits = model(input_features, decoder_input_ids)
loss = criterion(logits, labels)
total_loss += loss.item()
_, preds = torch.max(logits, 1)
all_labels.append(labels.cpu().numpy())
all_preds.append(preds.cpu().numpy())
all_labels = np.concatenate(all_labels, axis=0)
all_preds = np.concatenate(all_preds, axis=0)
loss = total_loss / len(data_loader)
accuracy = accuracy_score(all_labels, all_preds)
f1 = f1_score(all_labels, all_preds, average='macro')
return loss, accuracy, f1, all_labels, all_preds
You can train the model by invoking the train() method. In the following script, I trained the model for 5 epochs. Feel free to adjust the number of epochs based on your requirements.
num_epochs = 5
train(model, train_loader, val_loader, optimizer, criterion, device, num_epochs)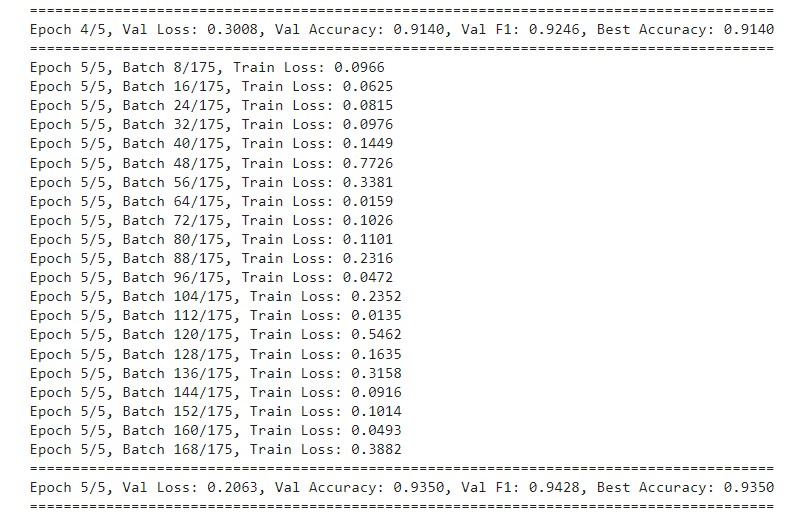
After five epochs, I got the best-case accuracy of 93.50%.
Evaluating the Model
As a last step, we will test our trained model on an unseen test set. To achieve this, import the model with the best accuracy, which was saved during training, and pass it to the evaluate() method, along with the test dataset.
state_dict = torch.load('best_model.pt')
# Create a new instance of the model and load the state dictionary
num_labels = 10
model = SpeechClassifier(num_labels, encoder).to(device)
model.load_state_dict(state_dict)
_, _, _, all_labels, all_preds = evaluate(model, test_loader, device)
print(classification_report(all_labels, all_preds))
print(accuracy_score(all_labels, all_preds))
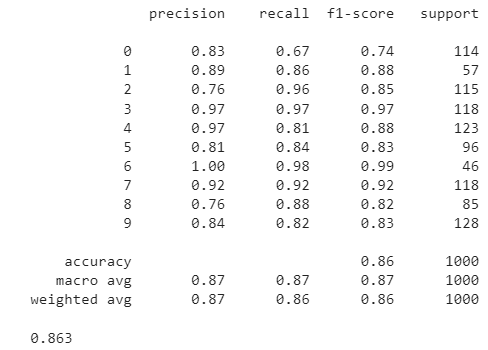
We achieved an accuracy of 86.30% on the test set. Feel free to experiment by adding or removing dense and dropout layers and adjusting the learning rate to explore potential improvements.
I hope you found this tutorial helpful. You should now be able to fine-tune the OpenAI Whisper model from Hugging Face in your PyTorch scripts. If you have any questions or feedback, please feel free to leave them in the comments, and I will do my best to respond promptly.
