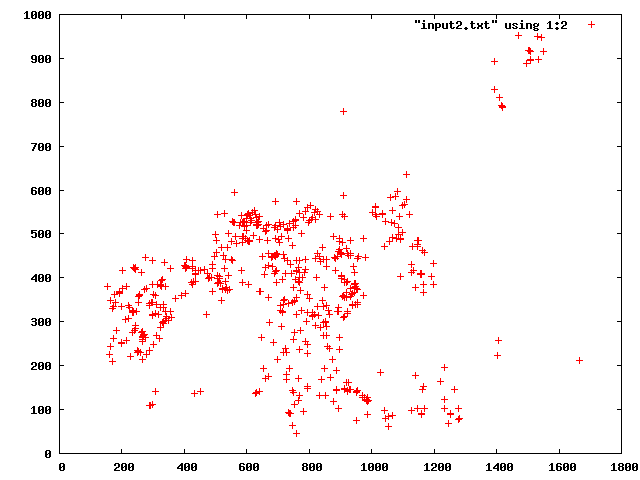
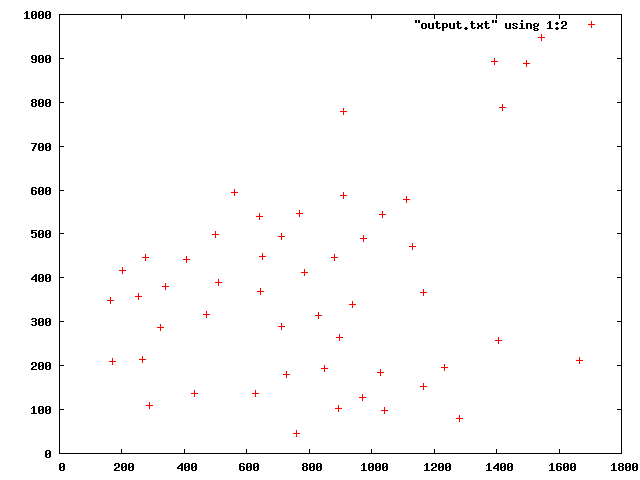
Hi guys,
I have a difficult problem to solve.
I have a list with 4 columns of values as follow
750.633 379.039 652.524 1112.63
930.491 452.16 842.753 1191.78
882.063 446.411 787.56 1183.43
434.362 410.174 325.863 1145.34
954.426 445.297 865.449 1183.74
1233.67 194.909 1155.27 908.305
1505.97 917.95 1441.07 1698.01
852.882 133.219 754.444 845.786
429.308 392.396 324.916 1127.72
358.381 310.049 241.12 1037.81
It can be from 10 to 700 raw entries and they are stored in a text file.
For the time being I will just focus on the first 2 columns (i just need to keep the other 2 as they are).
Now consider the first 2 columns as the x and y coordinates.
What I want to do is to select a certain amount of raws(let's say less than 100, if they are more) to be well distributed in space.
How can I do that?
Thanks a lot in advance :)
G.