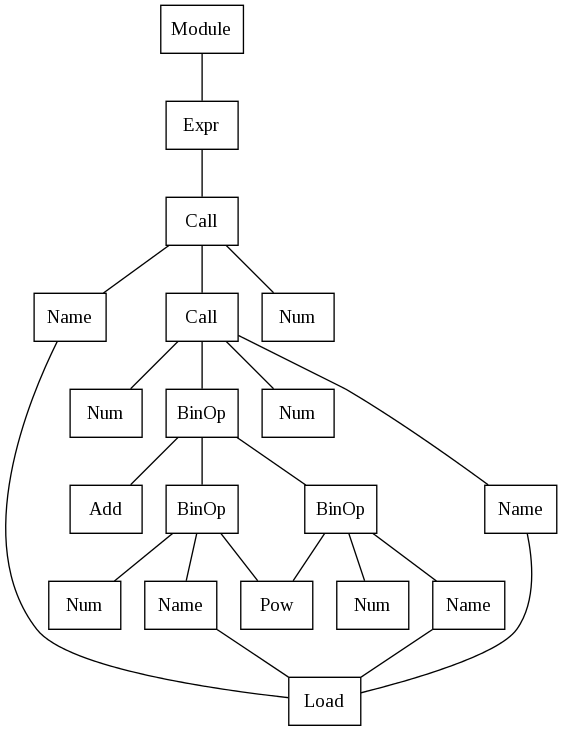
I could not parse it with csv, but if your string looks like python code, you can use python's own tokenizer:
# python 2 and 3
import sys
if sys.version_info < (3,):
from cStringIO import StringIO
else:
from io import StringIO
xrange = range
from tokenize import generate_tokens
a = 'par1=val1,par2=val2,par3="some text1, again some text2, again some text3",par4="some text",par5=val5'
def parts(a):
"""Split a python-tokenizable expression on comma operators"""
compos = [-1] # compos stores the positions of the relevant commas in the argument string
compos.extend(t[2][1] for t in generate_tokens(StringIO(a).readline) if t[1] == ',')
compos.append(len(a))
return [ a[compos[i]+1:compos[i+1]] for i in xrange(len(compos)-1)]
print(parts(a))
""" my output -->
['par1=val1', 'par2=val2', 'par3="some text1, again some text2, again some text3"', 'par4="some text"', 'par5=val5']
"""The other alternative is to use regular expressions.