Introduction
partitioningBy() collects a Stream into a Map. In this tutorial, we will compare the two different partitioningBy methods and learn how to use them.
Goals
At the end of this tutorial, you would have learned:
- What
Collectors.partitioningBydoes and how to use it.
Prerequisite Knowledge
- Basic Java.
- Java Streams (
java.util.stream, not IO streams). - Functional Interfaces (
java.util.function). - Lambdas/Method References.
Tools Required
- A Java IDE with support for at least JDK 16 (optionally for Record). If you do not want to use the Record class in the example, JDK 8 is enough.
partitioningBy Concept Overview
When operated on a stream, partitioningBy() returns a Map where the keys are always of Boolean type. This is a great Collector to use when you want the returned Map to contain 2 “partitions”, one for True and one for False.
Let us use an example to clarify the concept here.
You are given 2 students with different names, John and Mary, in a stream. partitioningBy() can help us to create a table with 2 columns, with the first column containing only students that match a specific Predicate(java.util.function.Predicate), while the other column containing students that do not match that same Predicate. If our Predicate matches only students with names starting with the letter “J”, then the scenario is depicted below.
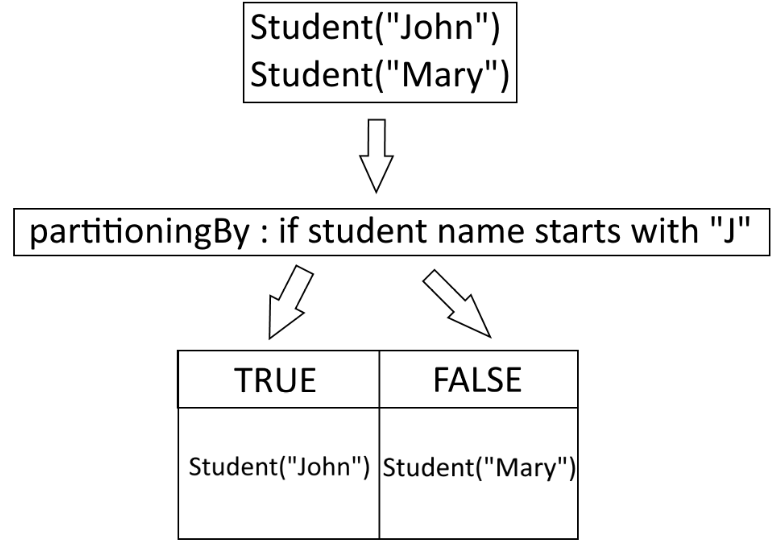
As you can see, the partitioningBy``Collector along with a Predicate helped us divide our data set into two “partitions”.
partitioningBy In Action
It is time to write some code to see how partitioningBy() works. We will start with creating the boilerplate code.
-
Create a new Java project.
-
Create a new package
com.example.collectors. -
Create a Java class called
Entry. This is where your main method will be. -
Copy the code below into
Entry.java.package com.example.collectors; import java.util.List; public class Entry { public static void main(String[] args){ List<Student> students = List.of( new Student("John", 22, Gender.MALE), new Student("Bob", 21, Gender.MALE), new Student("Mary", 23, Gender.FEMALE), new Student("Jessica", 21, Gender.FEMALE), new Student("Sam", 24, Gender.OTHER), new Student("Alex", 20, Gender.OTHER)); } } record Student(String name, int age, Gender gender){} enum Gender { MALE, FEMALE, OTHER }
In Entry.java, we now have an Entry class, which houses the main method. We also have two other reference types, a Student record and a Gender enum. Lastly, there is a List<Student> in main, which we can reuse for our code later (because Stream objects cannot be reused).
There are two versions of partitioningBy(), so let us start with the easier one first.
public static <T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate)The first version only requires a Predicate. To use it, we turn our student list into a stream and pass the Collector into the collect method.
Map<Boolean, List<Student>> result = students.stream().collect(
Collectors.partitioningBy(student -> student.name().length() < 4));
System.out.println(result);The Predicate lambda used here returns true if the student name has less than 4 characters, and false otherwise.
If I were to translate this code into plain English, it would mean: “For all of the students on the list, put the students whose names have less than 4 characters into the True column, and anything else in the False column”.
When we print the resulting Map, we can see all students with names less than 4 characters in the List<Student> associated with the true key.
{false=
[Student[name=John, age=22, gender=MALE],
Student[name=Mary, age=23, gender=FEMALE],
Student[name=Jessica, age=21, gender=FEMALE],
Student[name=Alex, age=20, gender=OTHER]],
true=
[Student[name=Bob, age=21, gender=MALE],
Student[name=Sam, age=24, gender=OTHER]]}The 2nd version of partitioningBy() is a little bit more complicated because it allows you to chain another Collector to the result.
public static <T,D,A> Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate, Collector<? super T,A,D> downstream)Here is how to use it.
Map<Boolean, Map<Boolean, List<Student>>> result2 = students.stream().collect(
Collectors.partitioningBy(student -> student.name().length() < 4,
Collectors.partitioningBy(student -> student.age() > 22)));
System.out.println(result2);Remember the Map<Boolean, List<Student>> that we get from the simpler version of partitioningBy()? Now the value for each key in the Map is no longer a List<Student>, but is another Map<Boolean, List<Student>>.
If we print out result2, we will see that the first Predicate(if name length is less than 4) creates the top Map with Boolean keys, but the values are now another Map (withBoolean keys as well). I have formatted the println output so it would be easier to observe what happened. The outermost boolean pairs are the results of the first Predicate, and the inner pairs are the results of BOTH Predicate.
{false={
false=[
Student[name=John, age=22, gender=MALE],
Student[name=Jessica, age=21, gender=FEMALE],
Student[name=Alex, age=20, gender=OTHER]],
true=[
Student[name=Mary, age=23, gender=FEMALE]]},
true={
false=[
Student[name=Bob, age=21, gender=MALE]],
true=[
Student[name=Sam, age=24, gender=OTHER]]}}Solution Code
package com.example.collectors;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Entry {
public static void main(String[] args){
List<Student> students = List.of(
new Student("John", 22, Gender.MALE),
new Student("Bob", 21, Gender.MALE),
new Student("Mary", 23, Gender.FEMALE),
new Student("Jessica", 21, Gender.FEMALE),
new Student("Sam", 24, Gender.OTHER),
new Student("Alex", 20, Gender.OTHER));
Map<Boolean, List<Student>> result = students.stream().collect(
Collectors.partitioningBy(student -> student.name().length() < 4));
System.out.println(result);
Map<Boolean, Map<Boolean, List<Student>>> result2 = students.stream().collect(
Collectors.partitioningBy(student -> student.name().length() < 4,
Collectors.partitioningBy(student -> student.age() > 22)));
System.out.println(result2);
}
}
record Student(String name, int age, Gender gender){}
enum Gender {
MALE, FEMALE, OTHER
}Summary
In this tutorial, we have learned what partitioningBy() does and went over both partitioningBy() variants.
The full project code can be found here https://github.com/dmitrilc/DaniWebPartitioningBy