a way to solve this completely independently from the number of categories and subcategories are (recursive) trees in SQL. There is a famous book: Transact-SQL Cookbook by Ales Spetic, Jonathan Gennick what has an extra chapter only dealing with that topic. They also explain how to traverse trees recursively by means of transact SQL.
Below table I once designed for a similar problem you are facing with is based on an example from this book. Our categories table (it slightly differs from below simple example) works great, and the table now has over 4000 categories and subcategories, still increasing.
create table categories ( -- father of main knot is NULL
ucat integer null, -- a father knot of a tree, it has many son knots
lcat integer not null, -- the son knot. has only one father knot
name varchar (30),
primary key (lcat),
foreign key (ucat) references categories); -- recursive definition
-- Some samples
insert into categories values (null,1,'Categories');
insert into categories values (1,2,'Software');
insert into categories values (1,3,'Hardware');
insert into categories values (1,4,'Network');
insert into categories values (2,5,'Linux');
insert into categories values (3,6,'PC');
insert into categories values (3,7,'Printer');
insert into categories values (6,8,'LCD');
commit
-- for example select all subcategories of category hardware
select * from categories
where ucat = all (select lcat from categories
where name = 'Hardware');
/* Result
ucat lcat name
------------------
3 6 PC
3 7 Printer
*/
are in doing data modelling? Superkey is any subset of attributes that uniquely identifies the tuples of a relation. This subset need not be minimal, that is, one can remove some attributes from it and it is still uniquely identifying. If all redundant attributes are removed you get a subset what is called primary key. A key (better: primary key) is the minimal subset of attributes that uniquely identifies the tuples of a relation, that is, you can't remove further attributes from this subset without losing the property of unique Identification. Therefore, the super superkey (like superman) is always the set of all attributes of a relation.
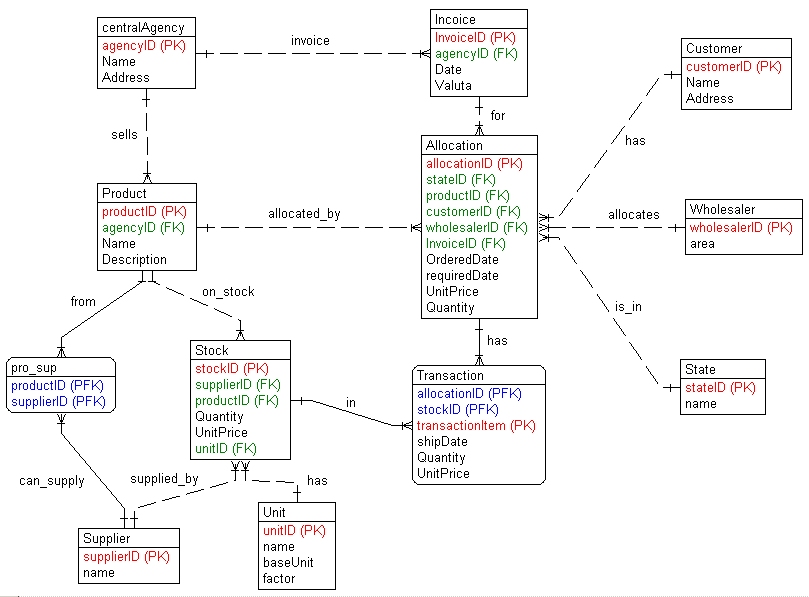
Hi arun, thx for giving further details. Here is the result (sure, incomplete!) attached. Drawing of the ERM has been done by tool from Charonware, which has better feature to create entities and relationships. PK = primary key, FK = foreign key (not identifying), PFK = foreign key what is also part of primary key (identifying). The ERM does not contain formal errors what has been checked by the Charonware tool. But it might have still some logical errors.
Remarks Transaction: There could be more than one transaction for a specific allocationID because of partial deliveries, therefore transactionItem. State: the state of an allocation, for example: not delivered, partly delivered, etc. Stock: what physically is on stock, delivered by supplier. This is decoupled from allocation and transaction, what may also mean that delivered quantities could be split into parts for satisfying different allocations. Unit: not that important (because I took some of the above design from an older design once I did, it appears here too) Maybe there must also be a relationship between customer and wholesaler, if a specific customer buys from various wholesaler? Invoice (not incoice): If there are partial billings for a specific allocation, there must be invoiceItem added, similar to transaction.
krs, tesu
ps. I can also generate sql script for Access 2000 and MySQL from above ERM.
Hi, is there a data type larger than unsigned long long int except double? I don't want double or float because I need to keep it as precise as possible. I also need it to be able to do modulus. How would I do this?
GMP is uniquely great. Yet, how large is very large integer?
So the advised select should function correctly. Solely just out of curiosity, did you true check the advised select on your database? Possibly you might have done some modification of it.
select t.rollno, t.age, s.sex from table1 t
join table3 s on t.rollno = s.rollno
where s.rollno = 1 or s.rollno = 7
union
select t.rollno, t.age, s.sex from table2 t
join table3 s on t.rollno = s.rollno
where s.rollno = 1 or s.rollno = 7
union
select t.rollno, t.age, s.sex from table10 t
join table3 s on t.rollno = s.rollno
where s.rollno = 1 or s.rollno = 7
So far, i didn't test it. what is the reason, that you have split the data over various tables?
there is a formula called Zeller's congurence to computing the day of week for are given date. You may look here: http://en.wikipedia.org/wiki/Zeller's_congruence
A programme in C++ that if date is input it tells day? For example Enter Date : 1-01-1985 The day is 'Monday'
Enter Date : 2-01-1985 The day is 'Tuesday'
Below program is a realisation of Zeller's congruence with the modification that 1 denotes Monday (now ISO standard). Btw, if 01 is month then 2-01-1985 is a Wednesday.
typedef unsigned long int ulint;
// Day of week, Mon=1, Sun=7 (modified Zeller's congruence to meet ISO)
// usage: cout << "Day of week: " << DayOfWeek(1985, 1, 2) << endl;
// Day of week: 3
ulint DayOfWeek ( ulint year, ulint month, ulint day )
{ ulint j, m;
if (month < 3) {m= month + 12; j= year - 1;} else {m= month; j= year;}
return ((day + (13* m - 32)/ 5 + j + j/ 4 - j/ 100 + j/ 400)% 7)+ 1;}
Try that with optimisation enabled, and the dead code should go away.
Thank you Salem, if I enable optimisation compilation error occurs: command line options /Ox and /RTC1 were incompatible, it says so. Occurs also with /O1 or /O2. Shall I switch off run time check?
I let the compiler generate the assembly code of a small program containing if with/without else path to figure out whether omitting else would affect execution time, results below:
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[])
{
// Without else
if ( argc == 0 ) return 0;
return 1;
// With else
if ( argc == 0 ) return 0;
else return 1;
}
/*************** Generated assembly output by VS 2005, V8.0.5
;;;; four semicolons indicate comments added by myself
;;;; 1st Example without else: if ( argc == 0 ) return 0; return 1;
;;;; Entry code left out
; 8 : // Without else
; 9 : if ( argc == 0 ) return 0;
cmp DWORD PTR _argc$[ebp], 0
jne SHORT $LN1@wmain
xor eax, eax
jmp SHORT $LN2@wmain
$LN1@wmain:
; 10 : return 1;
mov eax, 1
$LN2@wmain: ;;;; code to return to caller left out
;;;; 2nd Example with else: if ( argc == 0 ) return 0; else return 1;
;;;; Entry code left out
; 8 : // With else
; 9 : if ( argc == 0 ) return 0;
cmp DWORD PTR _argc$[ebp], 0
jne SHORT $LN2@wmain
xor eax, eax
jmp SHORT $LN3@wmain
jmp SHORT $LN3@wmain ;;;; <-- Doubly generated (dead) code
$LN2@wmain:
; 10 : else return 1;
mov eax, 1
$LN3@wmain: ;;;; code to return to caller left out
***************/
Above small C++ program has been compiled with option to generate assembly file (.asm). Comparison …
> what about solving little/big endian problem by doing appropriate typecast before writing to file? Because endian can't be fixed with a simple cast. You have to write code to rearrange the bytes into the correct order.
> Is there any standard function to test the endianess of the system? Not only is this non-portable (it assumes far too much about internal representations), it also assumes that there are only two endian systems (there's at least 3). http://en.wikipedia.org/wiki/Endianness
This is a completely wrong conclusion :) (maybe you didn't stick to the very original question)
No matter hardware is based on little-, mid- or big-endian, typecast from longer to shorter representation (and vice versa), for example from long double to float, will be correctly carried out. Apart from general loss of precision due to shorting the mantissa, serious problem may occur if the receiving exponent area is too short, what would lead to overflow. But this problems aren't caused by how the byte sequence is physically ordered in memory. Fairly occasionally one will get confronted with the endian problem, for example if one does TCP/IP programming, where data structures often still stick to big-endian tradition from Digital Equipment era.
Oh yes, no, there is no flag telling you "hello, I am little endian", you have to know it!
btw, if you know what endian your data is coded, swapping the bytes to get another endian coding is a very plain …
I have already installed your database, also made some changes.
Pls answer following questions:
1. What is stock allocation? 1.1 an amount of a certain product allocated (= reserved) for delivering to customers in the near future? 1.2 The amount of products ordered from company's supplier not yet delivered, ordered by your company's purchasing department. (if this is true, what is the procedure to move ordered products into "on stock" when they were delivered? So you need a stock-receipt function. Kind of account transfer.
2. What about the amount of products already sold to customers, should this also be recorded? There you would need a shipping-goods function.
3. What is employee, the person of your company who has carried out the "allocation", he who ordered the amount of products from your supplier?
A Wholesaler usually must keep the records of all product movements exactly containing amounts, costs, dates, receiver ..., therefore, for a real application all those movements need to be handled within you design.
There is something to keep in mind when using null modem wiring, see http://www.lammertbies.nl/comm/info/RS-232_null_modem.html Instead of checking the serial port with c++/cli program (maybe managed code cause problems) I would check it with serial port checker, for example using Portmon of Mark Russinovich or free serial port monitor.
Why open the file in binary mode, isn't it a text file created with text editor?
You may check the length of input read in by getline(). Differs it from size of book?
You need to read every line of your file for locating the entered ISBN, therefore repositioning it with bookIn.seekg(sizeof(book) * i, ios::beg) is not necessary.
It is also a good idea to put some test prints within your program to check whether input has correct value, reinterpret_cast works correctly, all book elements contain correct values etc.
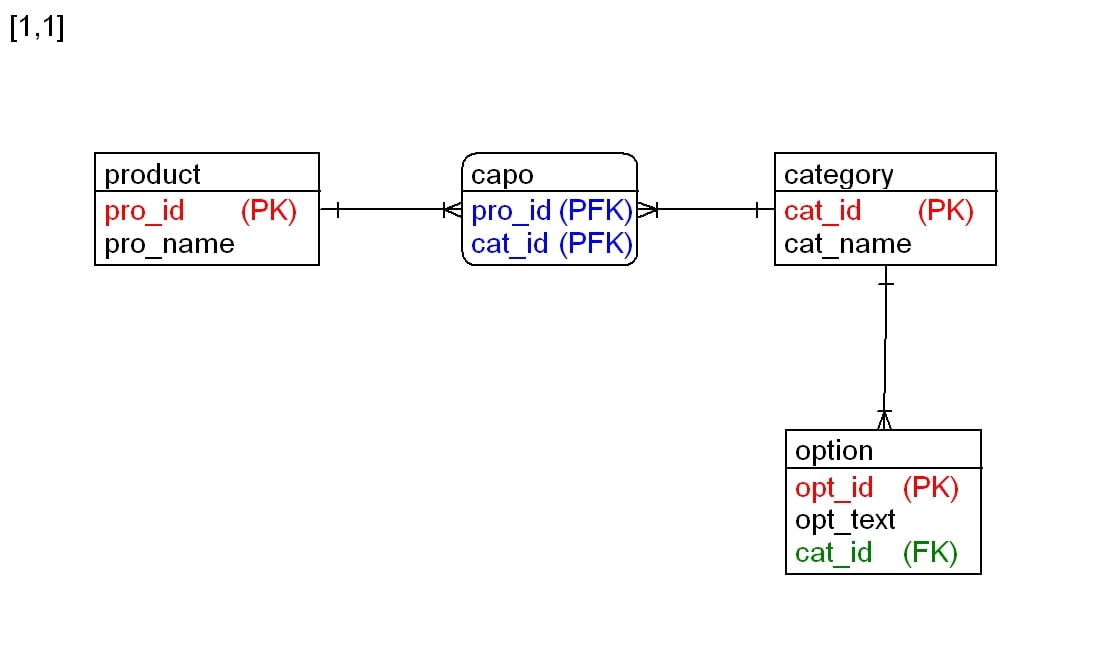
There is still a problem with entity option. Its pk is made of option_id and option_goup_id, what means that there would be a many-to-many relationship between option_group and a third thing like option_data. I think, option_group_id should be simple FK in option. Look at these instances:
Option group is ok, because relationship with category is non identifying. But option has some problems because same option_id can be combined arbitrarily with every option_group. I think an option can only be part of one option group, for example size measurements of rackets and apparels obviously differ in number and unit. Thus, it makes no sense defining a common size measurement option what can be assigned both option groups.
The attachment shows this simplification, maybe this would be enough (Also most modern ERP systems, e.g. MS Axapta, SAP R/3 possess classification systems where a specific product can only be part of one class/category. Then category_id would be non identifying part of product.).
You can upload the SQL script for creating the db, also the mdb file (I have access to acess 2003 only). Better: Upload the ERM, if you have sketched one.
// Two function to computing quotient and remainder
int quotient (int z ) { return z / 10; }
int reminder ( int z ) { return z % 10; }
// Simple solution to split int number into its digits
void demon ()
{ int n, d0, d1, d2, d3, d4;
cout << "Enter an integer between 1 and 32767: ";
cin >> n;
cout << n << endl;
d4 = reminder(n); n = quotient(n);
d3 = reminder(n); n = quotient(n);
d2 = reminder(n); n = quotient(n);
d1 = reminder(n); d0= quotient(n);
cout << d0 << " " << d1 << " " << d2 << " " << d3 << " " << d4 << endl;
}
// Below solution works recursively. Do you understand this?
// if you call split (4562), result is 4 5 6 2
void split(int n){
int d = n % 10; n = n / 10;
if ( n > 0) split (n);
cout << d << " ";
}
int main(int argc, char *argv[])
{
int n = 59;
char c1, c2;
c1 = n / 10 + 0x30; // in ASCII table, dec 0..9
c2 = n % 10 + 0x30; // are in col 3 starting at row 0, so add 30hex
cout << "digits of " << n << " are " << c1 << " and " << c2 << endl;
cout << "ascii of " << n << " are " << (int)c1 << " and " << (int)c2 << endl;
/** results:
* digits of 59 are 5 and 9
* ascii of 59 are 53 and 57
*/
}
krs, tesu
P.s. may I am allowed to ask what school are you attending, which location?
"17" ascii ?
"1" = 41hex (4th column, 1st row) = 0100 0001bin
"7" = 47hex (4th column, 7th row) = 0100 0111bin
17
76543210
00010001 = 16 + 1 = 2^4 + 2^0
-17
00010001
11101110 (invert all digits --> this is one s complement)
+ 1 (add 1 to get two s compl.)
-----------
11101111
0100 1011 1111 (form groups of 4 digits, starting at right)
4 B F
3 F
0011 1111
with temp_table ( name, in_date, out_date )
as ( select name, in_date, coalesce(out_date, '9090-09-09')
as out_date from date_table)
select * from temp_table x
where out_date = (select max(out_date) from temp_table y
where x.name = y.name)
With WITH clause table date_table will be duplicated and all null values of out_date replaced by funny date 9th September, 9090. Replacement is necessary because max() ignores NULL values. I didn't test it with MS SQL Server, but I know SQL Server 2005 also features WITH clause and coalesce function. Possibly date constant must be rewritten, or replace it by getdate().
You can give me a reply, if this also works on MS SQL Server 2005 properly.
a simple way to archive a result is a correlated select like this:
select * from date_table x
where out_date =
(select max(out_date) from date_table y where x.name = y.name)
Unfortunately this does not work properly if you have periods where out_date is not set, that is where out_date is NULL. I will think it over how to factor in NULL values, maybe there is a solution with coalesce(out_date, NOW(*), out_date).
this is a very nice task, but I would suggest you take the first turn starting to design that data model by yourself. Then post your (maybe imperfect) results, and we will help you willingly.
nice ERM. Maybe it s a good idea to state some rules about the cardinalities, for example:
A product can belong to more then as on product category or (shall it be: a product can belong to one category only)
As for the product options:
Relationship between option_group and option is non identifying (dotted line) . If so, there is no need for an identifying relationship between product_option and option_group.
If an option belongs to different option_groups, then I would prefer identifying relationship between option_group and option (there, option would be weak entity). Further an identifying relationship between option and product_option. No relationship between option_group and product_option. (One should avoid loops in ERM because sometimes they cause trouble by duplicating foreign keys.)
btw, to be exact, in that ERM product_option is not an entity, it is a many-to-many relationship between option and product (well, I know, most graphical ERM design tools usually replace many-to-many relationships by a (joining) entity).
The solution would be slightly different if you use product category from your 2nd ERM to control the assignment of options to products.
bad news! I have checked your join operations on those 6 tables, and the (wrong) results are:
1. contact.id id 2 will be counted 20 times id 5 will be counted 16 times id 8 will be counted 4 times
2. Indeed, you need LEFT OUTER JOIN. With inner join (which would be the appropriate one for such tasks, but...) you would lose all information about contact.id 2 and 8.
3. However, the result is wrong because you join four tables (tdocumentsA..D) independently together. The information you have spread over these 4 table MUST be arranged in ONE table only. Then applying of INNER JOIN on tusers INNER JOIN tContacts INNER JOIN tdocuments would work properly.
Long story short, you need to redesign your tables.
krs, tesu
Btw, below is the result of the last join, where you can check out why inner join would produce poorer results (all rows containing (NULL) would then disappear)
Left outer join should be replaced by inner join, as already stated. Can you post the create- table statements? I have got the feeling that something could be wrong with the relationships of your tables. As for example, table tUser contains foreign key contact_id what comes from tContacts. If tUser.id is the primary key then one certain user can only have ONE contact. Maybe that s correct? If a user should have more then one contact, the tUser.id must be foreign key of tContacts. Furthermore, primary key of tContacts, obviously tContacts.id, should then be non-identifying foreign key of the tdocumentsA...D instead of user_id.
As for your four document-tables, it would be a good idea to think of better normalization: What if you get further categories, say tdocumentsE ... ? So all documents should be stored in ONE table. This approach leads to simpler SQL statements, too.
Hi tanha, the given UDF should only be an example on how to program UDF using SQL Standard features. Since SQL 2003 (not 1999) there are UDFs defined, and they can be created with a rather new procedural language called PSM (Persistent Storage Moduls now part of SQL Standard, somehow weird name for programming language), and today, nearly all databases support this PSM, e.g. MS SQL Server, Oracle (within PL/SQL), DB/2, Sybase Databases etc. So far, MySQL 5 does not support PSM, maybe further version will do so.
Therefore, it is impossible to create this UDF example on a MySQL Database.
As already stated, in to-day MySQL there is an other approach for programming UDF, which is based on C programming and dynamically loaded libraries.
There you can find a function str_ucfirst (makes uppercase the first character of the string) which does exactly the task you are looking for. You can download the source, then take a look at the three programming-parts the function is made up. You should carefully follow the instructions on how to create and install such library. The most important step is that the dynamically loaded library must be installed on the computer where the MySQL server is running. I hope, you have access to your server.
Here is an UDF example which runs on SQL Anywhere 9:
CREATE FUNCTION upperFirstChar(IN isc VARCHAR(1000))
RETURNS VARCHAR(1000)
/* Usage:
select upperFirstChar('hello!') AS 'Capitalized 1st Character';
Result:
Capitalized 1st Character
-------------------------
Hello!
*/
BEGIN
DECLARE rtc VARCHAR(1000);
SELECT UPPER(SUBSTRING(isc, 1, 1)) + LOWER(SUBSTRING(isc, 2,
LENGTH(isc)-1)) INTO rtc;
RETURN rtc;
END;
I use select upper(substring(... to capitalize first char. You can also use this select within MySQL because all char functions are also available there.
well tanha, though i ve written UDFs for Sybase Databases a good many times, it s rather time-consuming doing that within MySQL. You may have a look at http://dev.mysql.com/doc/refman/5.0/en/adding-udf.html to get an impression of the hard work to be done for it (as opposed to the convenient way when programming UDF by using SQL1999 standards). krs, tesu
on your ODBC configuration dialog you can activate that detailed ODBC debug information has to be written to log file. Then start your program using mysql over odbc and post the contents of that log file.
Your trigger will be fired AFTER update, and, obviously, it were to catch update errors IF the record to be updated does not exist in your table. Well, if that record does not exist, update would not be execute, therefore (i believe so:)) AFTER-update trigger will never be fired.
If you want to prevent failure, if a record to be inserted already exists (that would lead into duplicate primary key), you might use
INSERT INTO table (...) VALUES (...) ON DUPLICATE KEY UPDATE ....
hi, MySQL does not support user defined functions (UDF) in the sense of standard SQL, which, for example, allow such a declaration in its own PSM language:
create function avgg(*)
returns float
ap float
select avg(price) from goods into ap
return ap
-- usage
select id from goods where price < avgg(*)
In MySQL kind of UDF can be defined as a plain C program. Such C-coded program must be linked dynamically, there is also special header handling. This approach is rather complicated and error prone. Once Borland's interbase had had same approach.
hi, you can also mask bit on position# 6, which is 0 if char is upper case and 1 if char is lower case, e.g. 'A' = 0x41 = 0100 0001 (binary), 'a' = 0x61 = 0110 0001 (binary).
bool isUpperCase (char c) {return !(c&0x20);}
. . .
char c='z';
cout<<c<<(isUpperCase(c)?" is upper ":" is lower ")<<"char";
// z is lower char
if you want to draw an int random number rn out of [0.. n-1] you can do that by supplying rn = rand() % n. rand() always produces the same sequence of random numbers. To avoid this, for example in game program, where you need "true" random numbers, you can initialize rand() with srand( time(NULL) ). Depending on the time, now you get various sequences of random numbers. To get an index for the fish array you may assign index = rand () % TYPE_OF_FISH;
C function rand() isn't that an awesome random generator, for example its period is just 32767-1. Much more better is MTRand of MersenneTwister.
your both tables do not satisfy the requirements of the First Normal Form (1NF), which is the minimum requirement, because they have countless repeating groups. Therefore, it's really hard to construct appropriate Queries, to prevent inconsistent data or to win upper hand against hidden anomalies.
To get rid of this dilemma, doing serious normalization should be your prime step before trying to create sql selects for such poor tables. You may google for normalization, repeating groups, insert anomalies ... to get a true impression.
I can assert that you did a good job. The relationship booking_tbl M:1 vehicle_tbl is correct because:
1. the primary key of vehicle_tbl, which is located at the one-side of the relationship, moves into the table booking_tbl, which is located at the many-side. (This rule must always be satisfied otherwise you don't have a M:1 relationship)
2. The sole primary key of booking_tbl is booking_id. The other keys vehicle_reg and customer_id are foreign keys only. Therefore, you do not have a compound primary key.
3. just to satisfy completeness: If your pk booking_id were to move into vehicle_tbl you would have got an 1:M relationship what s obviously plain wrong.
Maybe you did incorrect implementation on MS Access. As I remember hardly, older versions of access demanded to put an index on the primary key fields, possibly also on foreign key fields, but I am not sure of that. Today versions of relational database system automatically put an index on primary key fields. If not, performance of large tables would be slow down dramatically.
As trudge already stated, access isn't that a good choice for learning relational database design. There are tremendously better RDBMS as for example: MS SQL Server Express, Oracle 10i Express, Mimer SQL, Firebird (aka Borland Interbase), Postgresql, Sybase SQL Anywhere (absolutely great!) …
also your conception of communicating between Fortran and c++ programs is hardly to understand, there are simple ways to call fortran programs from c++ environment.. You may peer at http://wwwcompass.cern.ch/compass/software/offline/software/fandc/fandc.html or further sites easily be found by googling the internet.