I would read and print every line from the file into a new file, changing the line that matches your first two arguments. If you read the entire file without finding a match then print your new line at the end of your new file. If the new file needs to be in ascending order you can reopen it, sort it, and rewrite it.
d5e5 109 Master Poster
P.s: An error occurs at line 19th solved by an arobase: push @{$h_fruit{$fruitname}}, @fields;
For some reason perl didn't give me an error or warning about line 19 and it seemed to work OK, but you are correct: a good way to dereference the array reference $h_fruit{$fruitname}, as I needed to do in order to push values into it, is to enclose it in curly brackets and prefix it with an @, as you did.
d5e5 109 Master Poster
Your idea of a hash with keys of fruit names and values as array references should be sufficient. In your last script you convert the hash to a hash reference. You don't need a hash reference in this case and it makes the code look more complex when you want to dereference your array. The following should work:
#!/usr/bin/perl
use strict;
use warnings;
use List::Util qw(sum);#You probably have this module.
my $file=$ARGV[0];
my %h_fruit;#Keys will be fruits. Values will be references to arrays of values.
#Always test that file open worked, and die if it failed
#Best practice: open lexical filehandle such as $fh instead of bareword such as fruit_file
open (my $fh, '<', $file) or die "Failed to open $file: $!";
while (my $line = <$fh>){
chomp $line;
#You can use your regex but split on spaces looks simpler to me.
my @fields = split(/\s+/, $line);#split on spaces
my $fruitname = shift(@fields); #Remove the first field and assign it to $fruitname
$h_fruit{$fruitname} = [] unless exists($h_fruit{$fruitname});
push $h_fruit{$fruitname}, @fields;
}
foreach my $fruit (keys %h_fruit){
my @values = @{$h_fruit{$fruit}};#Dereference the array reference
my $nbval = @values;#Number of fields in the array
my $sum = sum(@values);
my $moy = $sum / $nbval;
print $fruit, ' Average: ', $moy, "\n";
}
d5e5 109 Master Poster
The set function gives a set of the unique items in a list. Iterate through that and print the count method of the list for each item.
#!/usr/bin/env python
def checkForWidthCount(mylist):
for x in set(mylist):#Iterate through set of unique list items
print x, 'count = ', mylist.count(x)
ExampleOfList = [1,2,3,3,3,5,5,5,6]
checkForWidthCount(ExampleOfList)
d5e5 109 Master Poster
If you replace those lines with the following it works without problems.
my $record_separator = "\n\n";
When I make that change the script prints headings only, because I have Linux. I hope abulut is still reading this, because I think you (replic) have solved the problem of running it under Windows.
d5e5 109 Master Poster
I suspect the statements that need to change to make it run under Windows are one of the following two:use constant {WINDOWS_LINE_END_CHAR => chr(13) . chr(10)}; my $record_separator = WINDOWS_LINE_END_CHAR x 2;
The input file records contain newline characters and Perl assumes newline as the default record separator. When I examine the input file (LOG.txt) it appears to me that each true record ends in a double set of the Windows newline characters. Unlike Linux, Windows ends its lines with a combination of Carriage Return and Line Feed characters. I think that newline \n means just Line Feed in Linux and Carriage Return + Line Feed in Windows. That's why I specify the line separator for input (not output) explicitly. But for some reason running the script in Windows hides or modifies the newline characters. I don't know why and I would have to experiment with various line separators and test under Windows, which I don't have.
It looks like a long complex script to debug, but I suspect that getting a simple script reading multi-line records to work under Windows would reveal the secret to getting this one to work.
d5e5 109 Master Poster
@abulut, I received a private message from you saying you get no output when you run my script, but I can't understand why not. When I run the above script on my computer I see 50 lines in the output file named KESIK_SEKTOR.txt which I have attached to this message. I don't know why this would not work on your computer. I believe your operating system is Windows and mine is Linux, but I don't know why this would make a difference. I don't have Windows on my computer so I don't think there is anything else I can do to make it work under Windows.
BSC BCF DATE TIME SAHA ALARM
BMALK02 BCF-0491 2012-02-28 19:27:52.89 MA24101 BCCH MISSING
BMALK02 BCF-0491 2012-02-28 19:27:53.25 MA24103 BCCH MISSING
BMALK02 BCF-0491 2012-02-28 19:27:54.26 MA24102 BCCH MISSING
BELAK01 BCF-1201 2012-02-29 13:14:00.19 EL04941 BCCH MISSING
BELAK01 BCF-1201 2012-02-29 13:14:00.58 EL04942 BCCH MISSING
BKONK02 BCF-2321 2012-02-29 18:32:30.42 KN07061 BCCH MISSING
BKONK02 BCF-2321 2012-02-29 18:32:30.81 KN07062 BCCH MISSING
BKONK02 BCF-2321 2012-02-29 18:32:31.22 KN07063 BCCH MISSING
BBINK01 BCF-0401 2012-03-01 19:10:59.59 BN08061 BCCH MISSING
BBINK01 BCF-0401 2012-03-01 19:11:01.96 BN08062 BCCH MISSING
BBINK01 BCF-0401 2012-03-01 19:11:02.34 BN08063 BCCH MISSING
BTOKK01 BCF-1061 2012-03-01 22:12:09.43 TO22011 BCCH MISSING
BTOKK01 BCF-1061 2012-03-01 22:12:09.81 TO22012 BCCH MISSING
BTOKK01 BCF-1061 2012-03-01 22:12:10.18 TO22013 BCCH MISSING
BVANK01 BCF-0061 2012-03-02 09:30:53.40 VA47762 BCCH MISSING
BVANK01 BCF-0061 2012-03-02 09:31:01.61 VA47763 BCCH MISSING
BVANK01 BCF-0061 2012-03-02 09:31:02.07 VA47761 BCCH MISSING
BSIVK01 BCF-1781 2012-03-02 11:10:32.32 SV45751 BCCH MISSING
BSIVK01 BCF-1781 2012-03-02 11:10:32.69 SV45752 BCCH MISSING
BSIVK01 BCF-1781 2012-03-02 11:10:33.08 SV45753 BCCH MISSING
BSAMK01 BCF-0631 2012-03-02 11:14:15.16 SM62681 BCCH MISSING
BSAMK01 BCF-0631 2012-03-02 11:14:15.56 SM62682 BCCH MISSING
BSAMK01 BCF-0631 2012-03-02 11:14:15.99 SM62683 BCCH MISSING
BSAMK01 BCF-0491 2012-03-02 11:14:16.51 SM61951 BCCH MISSING
BSAMK01 BCF-0491 2012-03-02 11:14:16.90 SM61952 BCCH MISSING
BSAMK01 BCF-0491 2012-03-02 11:14:17.31 SM61953 BCCH MISSING
BADYK01 BCF-1601 2012-03-02 14:40:08.49 AY02983 BCCH MISSING
BVANK01 BCF-0621 2012-03-02 20:02:06.07 VA48873 BCCH MISSING
BVANK01 BCF-0621 2012-03-02 20:16:49.40 VA48871 BCCH MISSING
BVANK01 BCF-0621 2012-03-02 20:16:49.78 VA48872 BCCH MISSING
BVANK01 BCF-0211 2012-03-02 20:26:12.97 VA48292 BCCH MISSING
BVANK01 BCF-0211 2012-03-02 20:26:13.30 VA48291 BCCH MISSING
BVANK01 BCF-0091 2012-03-02 20:30:45.90 VA48841 BCCH MISSING
BVANK01 BCF-0091 2012-03-02 20:30:48.34 VA48842 BCCH MISSING
BMALK02 BCF-0441 2012-03-02 20:31:00.78 MA24021 BCCH MISSING
BMALK02 BCF-0441 2012-03-02 20:31:01.21 MA24022 BCCH MISSING
BSRNK01 BCF-0161 2012-03-02 21:55:28.16 SR11122 BCCH MISSING
BSRNK01 BCF-0161 2012-03-02 22:22:18.19 SR11121 BCCH MISSING
BSIVK01 BCF-1041 2012-03-02 22:28:49.40 SV43901 BCCH MISSING
BVANK01 BCF-0021 2012-03-02 22:38:20.81 VA48931 BCCH MISSING
BVANK01 BCF-0021 2012-03-02 22:38:21.18 VA48932 BCCH MISSING
BVANK01 BCF-0021 2012-03-02 22:38:21.55 VA48933 BCCH MISSING
BKAYK02 BCF-0181 2012-03-02 22:41:03.12 KY46031 BCCH MISSING
BKAYK02 BCF-0181 2012-03-02 22:41:35.17 KY46032 BCCH MISSING
BKAYK02 BCF-0181 2012-03-02 22:41:35.18 KY46033 BCCH MISSING
BVANK01 BCF-0111 2012-03-02 22:42:26.05 VA48801 BCCH MISSING
BVANK01 BCF-0111 2012-03-02 22:42:26.43 VA48802 BCCH MISSING
BVANK01 BCF-0171 2012-03-02 22:44:10.70 VA48701 BCCH MISSING
BVANK01 BCF-0171 2012-03-02 22:44:11.07 VA48702 BCCH MISSING
BVANK01 BCF-0171 2012-03-02 22:44:11.45 VA48703 BCCH MISSING d5e5 109 Master Poster
I can't recreate the problem. did you literally type which perl- with a hyphen -? Why not just which perl? Are you logged into a remoter server somehow? I don't really understand the question.
d5e5 109 Master Poster
Lexical variables declared with my are defined only within the block in which you declare them. In your script you are returning a value in a void context instead of printing it or assigning it to a variable having a scope outside the subroutine. Here is how you would assign the returned value to a variable that you can print.
#!/usr/bin/perl
use strict;
use warnings;
my $num = 1;
my $newnum = cal($num);#Assign returned value to variable with required scope
#print "$newnum\n";#This won't work outside of cal subroutine's scope
print "New number is $newnum\n";
sub cal{
my $num = shift;
my $newnum = $num + 1;
return $newnum;
}
d5e5 109 Master Poster
For this sort of task I would prefer using inplace-edit instead of read-write mode.
#!/usr/bin/perl
use strict;
use warnings;
if (@ARGV == 0){
my $filename = 'test.txt';
#So you can use diamond operator and inplace editing
push @ARGV, $filename;
warn "No file name argument so I assume you want to edit $filename.\n"
}
#Enable inplace editing. Copy of input file saved as 'test.txt.bk'
$^I = ".bk";
while (<>) {
chomp;
print "$_\n";
if ($. == 2){
print "foo\n";
}
}
d5e5 109 Master Poster
If you also want to capture (or extract) the portion of the string that matches your pattern, then have a look at Extracting Matches.
d5e5 109 Master Poster
Sorry, the above example of using qr to store a pattern is not quite correct. You could store your pattern as follows:my $word = qr(DOT\d+);
For example:
#!/usr/bin/perl
use strict;
use warnings;
my $string = 'Number = DOT123';
my $word = qr(DOT\d+);
if ($string =~ m/^Number\s=\s$word/){
print "$string matches the $word pattern\n"
}
else{
print "$string does not match the $word pattern\n"
}
d5e5 109 Master Poster
my $word=~/DOT\d+/; attempts to match whatever is in $word and there is nothing in $word at this point in the script.
You can store a regex pattern in a variable using the Regexp-like quote function as follows: my $word = qr(/DOT\d+/);
d5e5 109 Master Poster
You can read through the first file line by line, and for each line you can check if it represents a required update to the database. It doesn't matter too much that the first file is huge because you only hold one line at a time in memory.
However, if the second file extracted from the database is also huge, that would pose a problem because the simplest thing would be to load it all into a hash or some data structure in memory in order to look up each key from your first file. The data structure holding the data from the second file could possibly exceed your available memory, so you are better off looking up each key from the original table in the database instead. If it's a relational database you can download DBI and the appropriate DBD module from CPAN and write a query that will look up each key and retrieve the associated value from the database table.
d5e5 109 Master Poster
I had to guess what characters to look for to know when the end of an input record occurs because each input record has several lines. The following script prints 50 BCCH MISSING lines on my computer.
#!/usr/bin/perl
use strict;
use warnings;
use constant {
ASC => 1,
DESC => -1
};
my $date_pattern = '\d\d\d\d-\d\d-\d\d';
my $time_pattern = '\d\d:\d\d:\d\d\.\d\d';
my $filename = 'LOG.txt';
my $filenane="KESIK_SEKTOR.txt";
open my $fh, '<', $filename or die "Failed to open $filename: $!";
use constant {WINDOWS_LINE_END_CHAR => chr(13) . chr(10)};
my $record_separator = WINDOWS_LINE_END_CHAR x 2;
my $ctr = 0;
my %lines;#Save report lines to sort later
while (my $aref = get_next_rec($record_separator)){
my ($bsc,$bcf,$date,$time,$saha,$alarm) = @$aref;
$lines{$date . $time. $ctr++} = $aref if $alarm eq 'BCCH MISSING';
}
open my $fp2, '>', $filenane or die "Cannot open $filenane for output\n :$!";
print $fp2 " BSC BCF DATE TIME SAHA ALARM \n";
foreach (sort {($a cmp $b) * ASC} keys %lines){
my @flds = @{$lines{$_}};
my $line = sprintf '%-10s%-12s%-15s%-16s%-14s%-12s', @flds;
print $fp2 $line, "\n";
}
sub get_next_rec{
local $/ = shift;
while (my $r = <$fh>){
my $dtrec = $r =~ m/^\s+([\w]+)\s+(\w+-\d+).+($date_pattern)\s+($time_pattern)/;
if ($dtrec){
my ($bsc,$bcf,$date,$time) = ($1,$2,$3,$4);
my $saha;
if ($r =~ m/([A-Z]{2}\d{5})/m){
$saha = $1;
}
else{
$saha = 'SahaNotFound'
}
my $alarm;
if ($r =~ m/ALARM.+\d\d\d\d\s((\w+\s?)+\w+)/ms){
$alarm = $1;
}
else{
$alarm = 'ALARMNotFound'
}
return [($bsc,$bcf,$date,$time,$saha,$alarm)];
}
else{
next;
}
}
} d5e5 109 Master Poster
Sorry, I was able to answer your original question about how to sort lines by date and time but I'm not able to filter your input data in the right way to give exactly the output you want. You may need to hire an expert to do that.
d5e5 109 Master Poster
#!/usr/bin/perl
use strict;
use warnings;
my $str = '01010';
#When 10 found, 'lookbehind' to see if 0 precedes it.
#If 0 precedes the 10 then capture the 10
#You can do this for repeated matches.
my @results = $str =~ m/(?<=0)10/g;
print join ', ', @results, "\n";
#If you want 010 010 instead of 10 10 you need to fix the results
#by prepending a 0 to each 10.
@results = map 0 . $_, @results;
print join ', ', @results, "\n"; d5e5 109 Master Poster
You can read the second file into a hash if the values in the first column are unique. By 'unique' I mean that '153814_at' occurs no more than once in the second file, so you can use it as a key in your hash whose value is 0.09276438. After building your hash by reading through your second file you can open your first file. For each record in your first file you can split the record into its two columns and see if an entry corresponding to the value in the first column occurs in the hash. If it does you can take the value associated with that key from the hash and you have the three data items that you want to print.
For example:
file1.txt
beans green
lime green
banana yellow
carrot orangefile2.txt
apple fruit
carrot vegetable
beans vegetable
banana fruit
spinach vegetable#!/usr/bin/perl
use strict;
use warnings;
my $filename1 = 'file1.txt';
my $filename2 = 'file2.txt';
my %categories;#Hash to store key=>value pairs from file2.txt
open my $fh, '<', $filename2 or die "Failed to open $filename2: $!";
while (<$fh>){
chomp;
my ($name, $cat) = split;
$categories{$name} = $cat;
}
close $fh;
open $fh, '<', $filename1 or die "Failed to open $filename1: $!";
while (<$fh>){
chomp;
my ($name, $colour) = split;
my $cat;
if (exists $categories{$name}){
$cat = $categories{$name}
}
else{
$cat = "***$name Not Found in $filename2***";
}
print "$name\t$colour\t$cat\n";
}
close $fh;Output:
beans green vegetable
lime green … d5e5 109 Master Poster
#!/usr/bin/perl
use strict;
use warnings;
use constant {
ASC => 1,
DESC => -1
};
my $date_pattern = '\d\d\d\d-\d\d-\d\d';
my $time_pattern = '\d\d:\d\d:\d\d\.\d\d';
my $filename = 'LOG.txt';
my %lines;#Save report lines to sort later
open my $fh, '<', $filename or die "Failed to open $filename: $!";
while (my $line = <$fh>){
$line =~ s/\R//g; #Remove Windows end-of-line characters because I have Linux
if ($line =~ m/^\s+(\w+\d\d)\s+(\w+-\d\d\d\d)\s+\w+\s+($date_pattern)\s+($time_pattern)/){
my ($bsc,$bcf,$date,$time) = ($1,$2,$3,$4);
my $saha = get_saha();
next if $saha eq '***SAHA NOT FOUND***';
my $alarm = get_alarm();
next if $alarm eq '***Alarm NOT FOUND***';
#print "$bsc\t$bcf\t$date\t$time\t$saha\t$alarm\n";
my $ctr = sprintf '%04d', $.;
$lines{$date . $time . $ctr}{'bsc'} = $bsc;
$lines{$date . $time . $ctr}{'bcf'} = $bcf;
$lines{$date . $time . $ctr}{'date'} = $date;
$lines{$date . $time . $ctr}{'time'} = $time;
$lines{$date . $time . $ctr}{'saha'} = $saha;
$lines{$date . $time . $ctr}{'alarm'} = $alarm;
}
}
print " BSC BCF DATE TIME SAHA ALARM \n";
#To change sort from ascending to descending sequence replace ASC with DESC
#in the following line.
foreach (sort {($a cmp $b) * ASC} keys %lines){
my @flds = ($lines{$_}{'bsc'}, $lines{$_}{'bcf'},
$lines{$_}{'date'}, $lines{$_}{'time'},
$lines{$_}{'saha'}, $lines{$_}{'alarm'});
my $line = sprintf '%-10s%-12s%-15s%-16s%-14s%-12s', @flds;
#print $line, "\n";#Change this statement to the following
print $line, "\n" if $lines{$_}{'alarm'} =~ 'BCCH MISSING';
}
sub get_saha{
while (my $line = <$fh>){
$line =~ s/\R//g; #Remove Windows end-of-line characters because I have Linux
#Changed the following to include alarms preceded by one or more asterixes *
if ($line =~ m/^\*+\s+ALARM\s+(\w+)/){
return $1;
}
if … d5e5 109 Master Poster
#!/usr/bin/perl
use strict;
use warnings;
my @matrix;
while (<DATA>){
chomp;
push @matrix, [split];
}
foreach my $row (@matrix){
foreach my $cell (@$row){
$cell = no_more_than_1($cell);
}
}
foreach (@matrix){
print join ' ', @$_, "\n";
}
sub no_more_than_1{
my $nbr = shift;
if ($nbr > 1){
return '1.0';
}
else{
return $nbr;
}
}
__DATA__
0.5 0.8 0.9 0.10
1.0 0.5 0.75 0.6
2.5 6.0 0.5 0.53
3.0 2.75 0.9 0.5 d5e5 109 Master Poster
I wouldn't call either of them wrong. For multiple inserts in a loop, I prefer the prepare + execute with place holders rather than the do, for a couple of reasons. In theory it makes more sense to prepare the insert statement once outside your loop and then execute it inside the loop for each set of values. You say it makes no difference in speed for MySQL, so there is no need to change scripts that already run satisfactorily ("If it ain't broke, don't fix it"). However if one day you migrate to a different database system and want to run the same scripts maybe it will make a difference, since some databases may optimize execution of previously prepared sql better than MySQL does.
Another reason. Look what happens in the following example of using $dbh->do in a loop. It works for some names but not the last one because it contains an apostrophe, whereas preparing the sql beforehand and passing the values to place holders avoids this problem.
#!/usr/bin/perl
use strict;
use warnings;
use DBI;
my $dbh=DBI->connect('dbi:mysql:daniweb','david','dogfood') ||
die "Error opening database: $DBI::errstr\n";
$dbh->do("CREATE TABLE IF NOT EXISTS people (fname VARCHAR(20),
lname VARCHAR(20))");
while (<DATA>){
chomp;
my ($fname, $lname) = split;
my $sql = "insert into `people` (fname, lname) values ('$fname', '$lname')";
print $sql, "\n";
$dbh->do($sql) or die "do failed: " . $dbh->errstr();
}
# Close connection
undef($dbh);
__DATA__
John Doe
Jane Smith
Martin O'Hara
Outputs
DBD::mysql::db do failed: You have an error in your … replic commented: Always answers with a well written response and adds some code to point out certain problems etc. +1
d5e5 109 Master Poster
#!/usr/bin/perl
use strict;
use warnings;
my $date_pattern = '\d\d\d\d-\d\d-\d\d';
my $time_pattern = '\d\d:\d\d:\d\d\.\d\d';
my $filename = 'LOG.txt';
my %lines;#Save report lines to sort later
open my $fh, '<', $filename or die "Failed to open $filename: $!";
while (my $line = <$fh>){
$line =~ s/\R//g; #Remove Windows end-of-line characters because I have Linux
if ($line =~ m/^\s+(\w+\d\d)\s+(\w+-\d\d\d\d)\s+\w+\s+($date_pattern)\s+($time_pattern)/){
my ($bsc,$bcf,$date,$time) = ($1,$2,$3,$4);
my $saha = get_saha();
next if $saha eq '***SAHA NOT FOUND***';
my $alarm = get_alarm();
next if $alarm eq '***Alarm NOT FOUND***';
#print "$bsc\t$bcf\t$date\t$time\t$saha\t$alarm\n";
my $ctr = sprintf '%04d', $.;
$lines{$date . $time . $ctr}{'bsc'} = $bsc;
$lines{$date . $time . $ctr}{'bcf'} = $bcf;
$lines{$date . $time . $ctr}{'date'} = $date;
$lines{$date . $time . $ctr}{'time'} = $time;
$lines{$date . $time . $ctr}{'saha'} = $saha;
$lines{$date . $time . $ctr}{'alarm'} = $alarm;
}
}
print " BSC BCF DATE TIME SAHA ALARM \n";
foreach (sort {$b cmp $a} keys %lines){
my @flds = ($lines{$_}{'bsc'}, $lines{$_}{'bcf'},
$lines{$_}{'date'}, $lines{$_}{'time'},
$lines{$_}{'saha'}, $lines{$_}{'alarm'});
my $line = sprintf '%-10s%-12s%-15s%-16s%-14s%-12s', @flds;
print $line, "\n";
}
sub get_saha{
while (my $line = <$fh>){
$line =~ s/\R//g; #Remove Windows end-of-line characters because I have Linux
if ($line =~ m/^\*\*\*\s+ALARM\s+(\w+)/){
return $1;
}
if ($line =~ m/^\s+(\w+\d\d)\s+(\w+-\d\d\d\d)\s+\w+\s+($date_pattern)\s+($time_pattern)/){
return '***SAHA NOT FOUND***';
}
}
}
sub get_alarm{
while (my $line = <$fh>){
$line =~ s/\R//g; #Remove Windows end-of-line characters because I have Linux
if ($line =~ m/^\s+\(\d+\)\s+\d+\s+([\w\s]+)$/){
return $1;
}
if ($line =~ m/^\s+(\w+\d\d)\s+(\w+-\d\d\d\d)\s+\w+\s+($date_pattern)\s+($time_pattern)/){
return '***Alarm NOT FOUND***';
}
}
}Outputs:
BSC BCF DATE TIME SAHA ALARM … d5e5 109 Master Poster
hİ
I've tried that you did not run script. Can you check it again. as the following must be cut according to SEKTORLER.txt log.txt file.
My output txt BSC BCF DATE TIME SAHA ALARM BCORK01 BCF-0021 2012-02-29 19:11:41.65 CO11801 BCH MISSING BCORK01 BCF-0021 2012-02-29 19:11:42.65 CO11802 BCH MISSSING BCORK01 BCF-0021 2012-02-29 19:11:43.65 CO11802 BCH MISSSING
Sorry, I don't understand what you mean by 'I've tried that you did not run script.' Also, you said previously 'the top of the written must be the newest date' but the sample output you show above has the most recent date + time at the bottom.
d5e5 109 Master Poster
Because I hope to use two value $gia and $name1 in my script. And I tried to use
my $position="$gia$name1"; read_positions ($position);but it has error to read file.
The erro: Failed open 6114067_contig34:No such file or directory at c:\users\PCUSER\desktop\thu.pl line 129I do not know how to solve that error. Could you show me how to solve this error?
That message says that a file named '6114067_contig34' does not exist in your current directory. Either the file named '6114067_contig34' is in a different directory or it has a different name. Should it have an extension (such as dot something). For example if the file is really named '6114067_contig34.txt' then trying to open '6114067_contig34' will result in the error message you are getting.
Do you know what the current directory is when perl runs your scripts? What is the output when you run the following?
#!/usr/bin/perl
use strict;
use warnings;
use Cwd qw();
my $path = Cwd::cwd();
print "$path\n";
my @files = <6114067_contig34*>;
foreach my $file (@files) {
print $file . "\n";
}
print "No files exist starting with '6114067_contig34' in $path\n" if @files == 0; d5e5 109 Master Poster
Rather than change your long complex script, you can run a second script that takes the resulting file as input, then modifies the spacing and sorts the lines.
#!/usr/bin/perl
use strict;
use warnings;
my $filename = 'KESIK_SEKTORLER.txt';
open my $fh, '<', $filename or die "Failed to open $filename: $!";
my @file = <$fh>; #Read file into array so you can sort
map s/\R//g, @file; #Remove Windows end-of-line characters because I have Linux
@file = sort sortsub @file;
foreach(@file){
s/\s+/ /g;#Replace many spaces with one space
s/^\s//;#Remove space at beginning of line
print $_, "\n";
}
sub sortsub{
my $date_pattern = '\d\d\d\d-\d\d-\d\d';
my $time_pattern = '\d\d:\d\d:\d\d\.\d\d';
my ($a_dt) = $a =~ m/($date_pattern\s+$time_pattern)/;
my ($b_dt) = $b =~ m/($date_pattern\s+$time_pattern)/;
#print "adt is $a_dt\tbdt is $b_dt\n";
$a_dt = '9' x 23 unless defined $a_dt;
$b_dt = '9' x 23 unless defined $b_dt;
$b_dt cmp $a_dt;
} d5e5 109 Master Poster
You want to put the content of $gia and $name together to have the name of an existing file that you can pass to a subroutine which will open and read that file, right? I don't know why you would ask how to separate that file name into columns, but the following is an example of passing a variable containing one scalar value that should be a valid file name.
#!/usr/bin/perl
use strict;
use warnings;
my $gia = 12;
my $name = 'tai';
my $oneval = $gia.$name; #Name of file should be '12tai', right?
print_first_argument($oneval);#Call subroutine and pass one scalar value as argument
sub print_first_argument{
my ($filename) = @_;#Assign argument to lexical variable
print "The first argument is '$filename'\n";
#If $filename contains the name of a file that exists
#then you should be able to open and read it.
}If my ($filename) = @_;#Assign argument to lexical variable looks confusing you can substitute with my $filename = shift(@_);#Assign argument to lexical variable which does exactly the same thing.
d5e5 109 Master Poster
Have a look at this similar question on StackOverflow. I like the following idea:
#!/usr/bin/perl
use strict;
use warnings;
my $command = '/usr/bin/perl';
my $script = '/home/david/Programming/Perl/print_values.pl';
my $value1 = 'Boiling point of water';
my $value2 = '100 degrees celsius';
{
local @ARGV = ($value1, $value2);
unless (my $return = do $script) {
warn "couldn't parse $script: $@" if $@;
warn "couldn't do $script: $!" unless defined $return;
warn "couldn't run $script" unless $return;
}
} d5e5 109 Master Poster
#!/usr/bin/perl
use strict;
use warnings;
my $gia = '12tai';
#Capture sequence of digits into one variable,
#capture sequence of non-digits into another variable
my ($number, $name) = $gia =~ m/(\d+)(\D+)/;
print "$number $name\n";#Two values separated by one space d5e5 109 Master Poster
I have 2 perl files. 1st file is my main program and the 2nd is a small sub which I call by using system("file.pl"); I would like to reuse a stored value/s in variables from the main program and use them in the external file. How is this possible?
Main script calls perl and passes the name of another script plus a couple of values for the second script to print.
#!/usr/bin/perl
use strict;
use warnings;
my $command = '/usr/bin/perl';
my $script = '/home/david/Programming/Perl/print_values.pl';
my $value1 = 'Boiling point of water';
my $value2 = '100 degrees celsius';
system($command, $script, $value1, $value2) == 0
or die "system $command, $script, $value1, $value2 failed: $?"print_values.pl
#!/usr/bin/perl
use strict;
use warnings;
my ($v1, $v2) = @ARGV;
print "First variable contains '$v1'\n";
print "Second variable contains '$v2'\n"; d5e5 109 Master Poster
I don't have Windows on my computer so I can't answer your question if you are asking about installing PPM under Windows. You have a better chance of getting the attention of someone who can help you if you start a new thread with a relevant title such as "Installing PPM (Perl Package Manager) under Windows." (This thread title is "using the 'use Mysql' command" and it's more than a year old.)
If you have a non-Windows platform such as Mac-OS or Ubuntu, please include that information in your question.
d5e5 109 Master Poster
I can't reproduce your error. The following script gets a title from a web page and prints it. The output looks OK on my computer.
#!/usr/bin/perl
use strict;
use warnings;
# define the subclass
package IdentityParse;
use base "HTML::Parser";
use LWP::Simple;
use Encode qw(encode decode);
my $printit = 0;
sub start {
my ($self, $tag, $attr, $attrseq, $origtext) = @_;
$printit = 1 if $tag eq 'title';
}
sub text {
return unless $printit == 1;
my ($self, $text) = @_;
my $encoded_text = encode('UTF-8', $text);
print $encoded_text;
}
sub end {
my ($self, $tag, $origtext) = @_;
$printit = 0 if $tag eq 'title';
}
my $p = new IdentityParse;
my $content = get 'http://greekcook.gr/tags/%CE%BA%CF%81%CE%B9%CE%B8%CE%B1%CF%81%CE%AC%CE%BA%CE%B9';
$p->parse($content);Outputs Συνταγές : κριθαράκι
d5e5 109 Master Poster
What do you expect file.pl to do when called that it doesn't seem to do? Do you want control to return to your calling script after the file.pl finishes or just to terminate, or to call another script? Since what someone told you about system didn't work, have you had a look at perldoc -f system?
d5e5 109 Master Poster
wooh it is wonderful. Thanks d5e5!
Could you show me the mean of two sentence and why we should use that ?
$name =~ m/(\d+)\s(\w+\d\d)/;
$key = lc("$1_$2");
I just know
\d+ : Matches a digit [0-9].
\w+ : matches an anpha chater
\s: Matches a whitespace character
Thank you so much.
$name =~ m/(\d+)\s(\w+\d\d)/; means that when the text in $name contains a string of one or more digits followed by a space followed by one or more alphanumeric characters followed by exactly two digits we want the first string of digits saved in $1 and the alphanumeric string and the following two digits saved in $2.
Because we don't want to use all the text in $name, we capture the desired text by means of parentheses in the regex pattern. When a match occurs, the value corresponding to the pattern in the first parentheses is captured into the special Perl variable $1 and the value corresponding to the pattern in the second parentheses is captured into $2. We want the key in the hash to be the same as what we will read in the data1.txt so we put $1 and $2 together in a string with an underscore _ between them. See Extracting Matches.
\d matches one digit.
\d+ matches one or more digits (See Matching Repetitions.
"\w matches a word character (alphanumeric or _), not just [0-9a-zA-Z_] but also …
d5e5 109 Master Poster
#!/usr/bin/perl
use strict;
use warnings;
my %aas; #Hash to store amino acids
read_amino_acids('data2.txt');
read_positions('data1.txt');
sub read_amino_acids{
my ($filename) = @_;
open my $fh, '<', $filename or die "Failed to open $filename: $!";
my ($name, $key);
while (<$fh>){
s/\s+$//; #Remove end-of-line characters
my @flds = split /\|/;
if (@flds > 1){
$name = $flds[4];
$name =~ m/(\d+)\s(\w+\d\d)/;
$key = lc("$1_$2");
undef $aas{$key} unless exists $aas{$key};
}
else{
$aas{$key} .= $_;
}
}
}
sub read_positions{
my ($filename) = @_;
open my $fh, '<', $filename or die "Failed to open $filename: $!";
print "Name posi amino acid\n";
while (<$fh>){
s/\s+$//; #Remove end-of-line characters
my ($name, $pos) = split;
next unless $name =~ m/^\d+_/;
my $tuple = substr $aas{$name}, $pos - 1, 3;
printf "%s%7d%16s\n", ($name,$pos,$tuple);
}
} d5e5 109 Master Poster
Why not do the following?
#!/usr/bin/perl
use strict;
use warnings;
use Data::Dumper;
my @type1_cols = qw(col1 col2 col3);
my $string = 'beer:beef:cabbage';
my %hash;
($hash{'col1'}, $hash{'col2'}, $hash{'col3'}) = split (/:/,$string);
print Dumper(\%hash);That looks easier to understand, to me, than having to resort to eval() .
d5e5 109 Master Poster
Have you tried $hash->{$col} = eval(qq(\$$col)); ?
d5e5 109 Master Poster
The Dot Matches (Almost) Any Character
Also have a look at Repetition with Star and Plus and after reading the first part, scroll down to the paragraph about Laziness vs. Greediness which explains what the ? character does in this context.
d5e5 109 Master Poster
Thanks, I made the change. I will let you know, I haven't had a chance to test it yet. Having a "whale of a time" with the server I have to work with... they're still using PHP 4 and I've hit a "brick wall" with another script I am trying to get to work in conjunction with the PERL script. Are you well-versed in PHP 4? (d5e5) I'm not a "programmer" but can get around rather well with pieces of code and modifying them to my liking.
I don't know much PHP. I learned a bit by lurking on the daniweb php forum a couple of years ago but have forgotten most of it since then. You might try asking there.
d5e5 109 Master Poster
The value of whatever matches what is in the first pair of parentheses goes into $1, and the value of whatever matches what is in the second pair of parentheses goes into $2. Here's an example of capturing matches into the $1 and $2 variables.
#!/usr/bin/perl;
use strict;
use warnings;
my $line = "Hello Harry, how is your house?";
$line =~ m/(\bh\w+).*?(\bh\w+)/i;
print '$1 = ', "$1\n";
print '$2 = ', "$2\n";Note that it's not as flexible as thines01 script because the pattern will capture only the first to words starting with 'h' or 'H' and ignores the rest.
d5e5 109 Master Poster
Thanks (d5e5), I'll give this a try :) much appreciated, cheers!
You're welcome. I made one mistake in the third line of the prepend2file subroutine. The open statement should sayopen my $fh, '>', $file or die "Couldn't open $file: $!";
to refer to the $file variable declared inside that subroutine.
d5e5 109 Master Poster
Any chance to get a rewrite of a script?
You already know how to do the CGI which I think must be logically independent of how to prepend a string to a file.
#!/usr/bin/perl;
use strict;
use warnings;
my $filename = 'data.txt';
#If file doesn't exist, create it
if (-e $filename){
#File exists, so don't create new file
}
else{
open my $fh, '>', $filename or die "Failed to create $filename: $!";
}
my $string2prepend = 'Tom';
prepend2file($string2prepend, $filename);
sub prepend2file{
my ($str, $file) = @_;
my $old_data = slurp_file($file);
open my $fh, '>', $filename or die "Couldn't open file: $!";
print $fh $str, $old_data;
}
sub slurp_file{
my $filename = shift;
local $/=undef;
open my $fh, '<', $filename or die "Couldn't open file: $!";
my $string = <$fh>;
return $string;
} d5e5 109 Master Poster
An associative array, otherwise known in Perl as a hash, does not preserve the order in which the elements were added. If you want to list the contents of a hash in a particular order you can sort the keys according to rules which give you the desired result. If you want to sort by keys, or values, in ascending or descending order, by numeric or alphabetic comparisons, etc. you can do that. But 'the same order' in which elements were added to a hash cannot be determined. See Perl Tutorial - Hashes.
If you need to save key-value pairs in a particular sequence you could build a more complex data structure, such as an array of references to hashes. See Arrays of Hashes.
d5e5 109 Master Poster
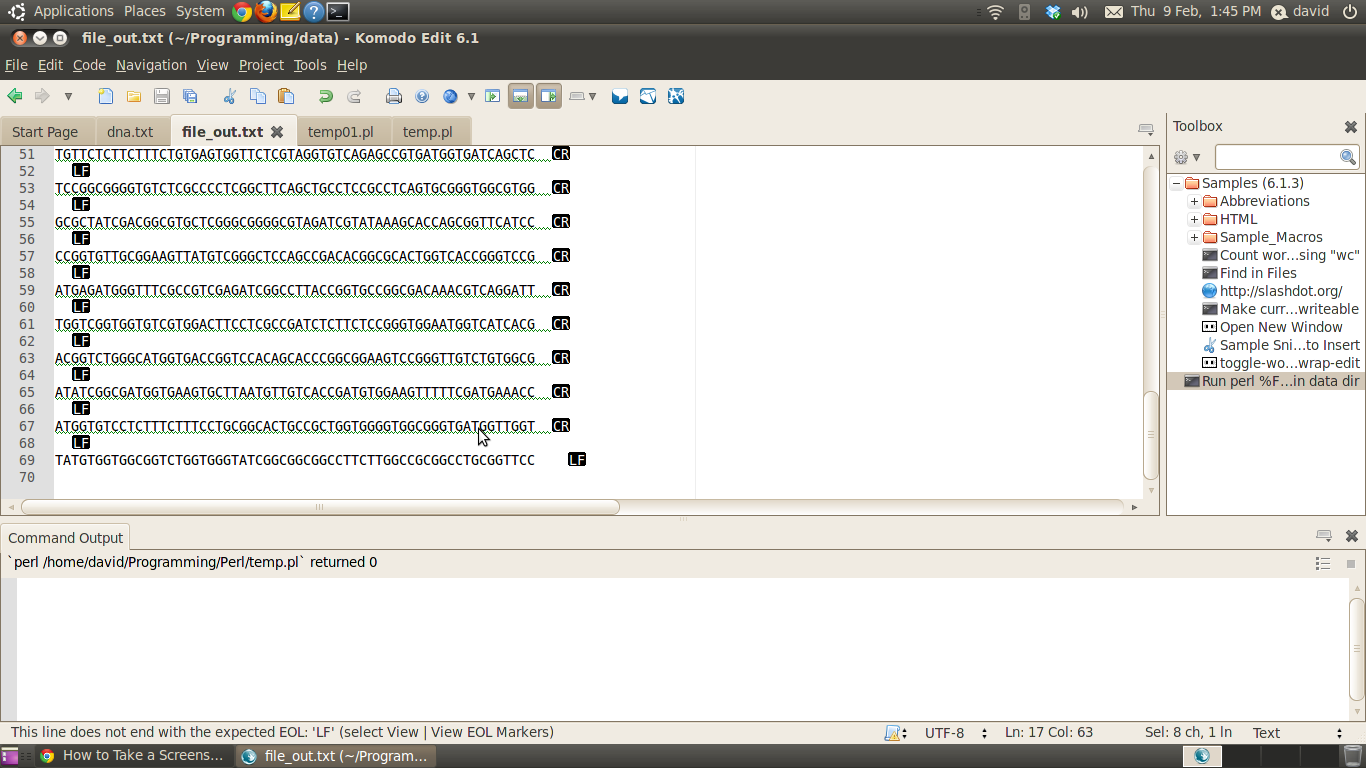
I was 2 minutes to slow. True, I would not have remove the space at the end.
It's not an ordinary space character at the end of each line. It's a carriage return character that causes my text editor to warn me "This line does not end with the expected EOL: 'LF'..." (see attached screenshot.) The input file has Windows format newlines (CRLF) but linux expects linux-type newlines so perl's chomp command removes only the LF. When the script prints it re-adds LF to every line. If all the lines have carriage return characters except for the last then the output file has CRLF newline characters on all lines but the last, which will have only LF.
That's not a biggie normally, unless the output file will be processed as input by another script that gets confused by mixed line endings.
d5e5 109 Master Poster
See if this does what you want.
#!/usr/bin/perl use strict; use warnings; if ( !defined($ARGV[0])){ print "\nUsage: $0 <name>\n"; print " Example: $0 AGQQ01000003.1\n\n"; exit; } my ($filename3,$filename,$printIt) = ('file_out.txt','dna.txt',0); my @columns; my $pat = quotemeta($ARGV[0]); open my $fh, '<', $filename or die "Failed to open $filename: $!"; open my $fho, '>', $filename3 or die "Failed to open $filename3: $!";#Open file for output while (my $rec = <$fh>){ chomp($rec); @columns = split(/\|/,$rec); if ( $#columns >= 3 ) { if ( $columns[3] =~ /$pat/ ){ #print $fho "$columns[3]: "; $printIt = 1; } else { $printIt = 0; } } print $fho "$rec\n" if ( $printIt && $#columns == 0 ); } close $fh;
That way looks good too, histrungalot. One thing: I notice you left out the $rec=~ s/\s//g; statement the original script had. That may or may not be wanted depending on whether you want to keep the Windows-style CRLF newlines or if you want to replace them with those of the current platform (in my case, linux).
d5e5 109 Master Poster
#!/usr/bin/perl;
use strict;
use warnings;
my $filename3 = 'file_out.txt';
my $filename = 'dna.txt';
open my $fh, '<', $filename or die "Failed to open $filename: $!";
open my $fho, '>', $filename3 or die "Failed to open $filename3: $!";#Open file for output
my $name;
while (my $rec = <$fh>){
$rec=~ s/\s//g;
chomp($rec);
#If reading first line of data (starts with '>') for a name, save the name
if ($rec =~ m/^>/){
my @flds = split(/\|/, $rec);#split first line of group to get name
$name = $flds[3];
next; #Read next line (you don't want to print first line of group)
}
if ($name eq 'AGQQ01000002.1'){
print $fho "$rec \n";
}
}
close $fh; d5e5 109 Master Poster
Your script looks up each name in a hash before inserting it into your database and saving it into the hash. That works as long as your script runs, but when it stops your hash no longer exists. The database persists when the script isn't running, so you need to attempt to select the name from your database before inserting it. For example:
my ($name, $phone) = ('Jane Doe', '123 4567');
# execute SELECT query
my $sth = $dbh->prepare("SELECT name FROM Phonebook WHERE name = ?");
$sth->execute($name);
#Fetch result into hash reference
my $ref = $sth->fetchrow_hashref();
if (defined $ref->{'name'}){
die "A record for $name already exists in the phonebook.\n";
}
else{
#Prepare insert statement
$sth = $dbh->prepare('INSERT INTO Phonebook (name, Phone) VALUES (?, ?)')
or die "Couldn't prepare statement: " . $dbh->errstr;
$sth->execute($name, $phone);
print "$name $phone successfully added.\n";
} d5e5 109 Master Poster
If the script reads each line into the $rec variable, then you won't find anything in the $_ variable. my ($po) = $rec =~ m/\[(protein=.+?)\]/g; should work OK.
If you want to read many files, one at a time, you can assign the list of input file names into the @ARGV array and then read from the empty diamond operator.
#!/usr/bin/perl;
use strict;
use warnings;
#Assign any number of file names to Perl's special @ARGV array
@ARGV = qw(file1.txt file2.txt file3.txt);#Example with 3 file names
#Each file automatically opens and closes as script reads the contents
while(my $rec = <>){
chomp($rec);
print "$rec\n";
}You can get the same result by using a glob pattern to put the list of desired files into @ARGV, which may be easier than typing 43 file names.
#!/usr/bin/perl;
use strict;
use warnings;
@ARGV = <file?.txt>;#Glob list of files matching pattern. ? stands for any character
#Each file automatically opens and closes as script reads the contents
while(my $rec = <>){
chomp($rec);
print "$rec\n";
} d5e5 109 Master Poster
...Now, I am trying to run the script with the 1406_01.txt which was attached in this question last time, I have some erorr.
I hope the put out data with :Id product start end gene=KIQ_00005 protein_id=EHE85001.1 1 423 gene=KIQ_00010 protein_id=EHE85002.1 710 1225Could you show me how can I put out that form 1406_01.txt data?
Because location is not always in the same column I use regular expressions (regex) instead of split to extract the desired data. To understand what the regex means I recommend this link to a Regex Tutorial.
#!/usr/bin/perl;
use strict;
use warnings;
my $filename = '14067_01.txt';
open my $fh, '<', $filename or die "Failed to open $filename: $!";
printf "%s%21s%21s%7s\n", qw(id product start end);
while (my $rec = <$fh>){
next unless $rec =~ m/^>/;#Skip all lines other than the first line of record
chomp($rec);
#Because location is not always in the same column I use regular expressions (regex)
#instead of split to extract the desired data.
my ($name, $product, $loc) = $rec =~ m/\[(gene=.+?)\]\s.*\[(protein_id=.+)\]\s(\[.+\]?)/g;
$loc = 'undefined' unless defined $loc;
my ($start, $end) = $loc =~ m/\d+/g;
printf "%-16s%21s%7s%7s\n", ($name, $product, $start, $end);
}
close $fh; d5e5 109 Master Poster
To extract two substrings of sequential digits from a string you can do a regex match using the /g option to get a list.
#!/usr/bin/perl;
use strict;
use warnings;
my $location = '[location=complement(<1..423)]';
my ($start, $end) = $location =~ m/\d+/g;#Regex match makes list of substrings of sequential digits
print "Start position is $start and end position is $end";