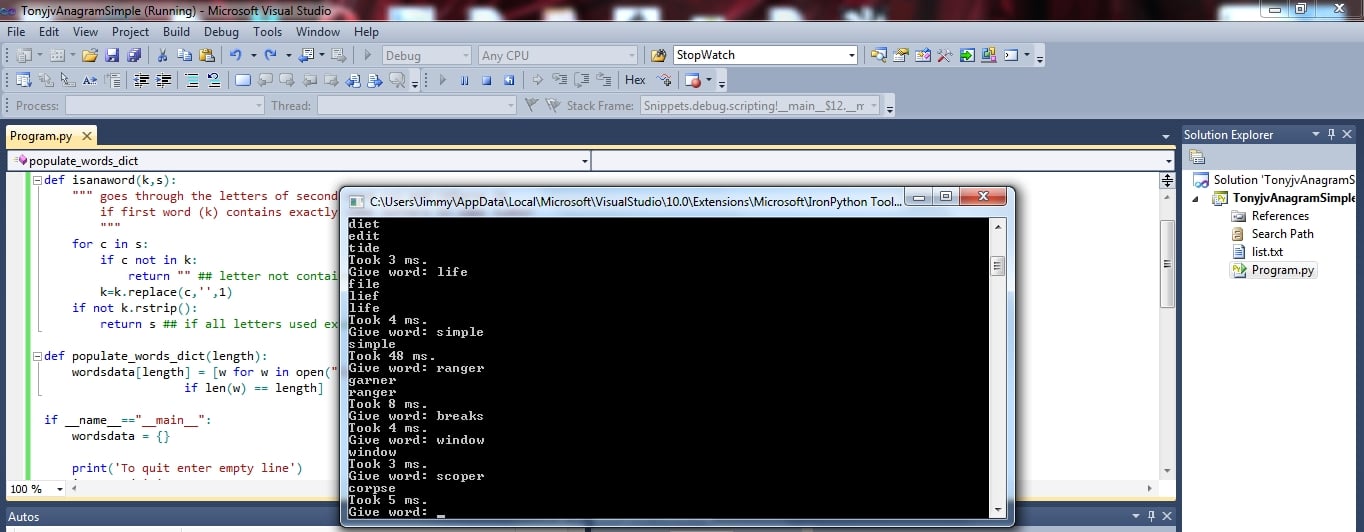
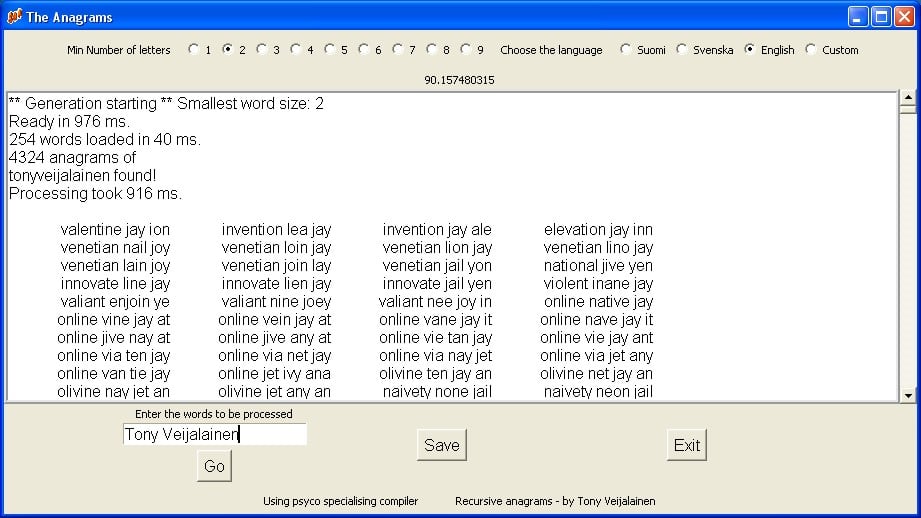
Here is solution number one for one word anagrams, I gave in discussion thread, response time in my humble Athlon PC under 70 ms.
List of words is from original posting of the discussion thread.
http://www.daniweb.com/forums/post1206616.html#post1206616
This version does not give we'd for input dew.
Next time I give final speed demon solution: preparing lookup table file.
You can prove the program without the length check part it is optional, program becomes around 3 times slower without it in my computer.