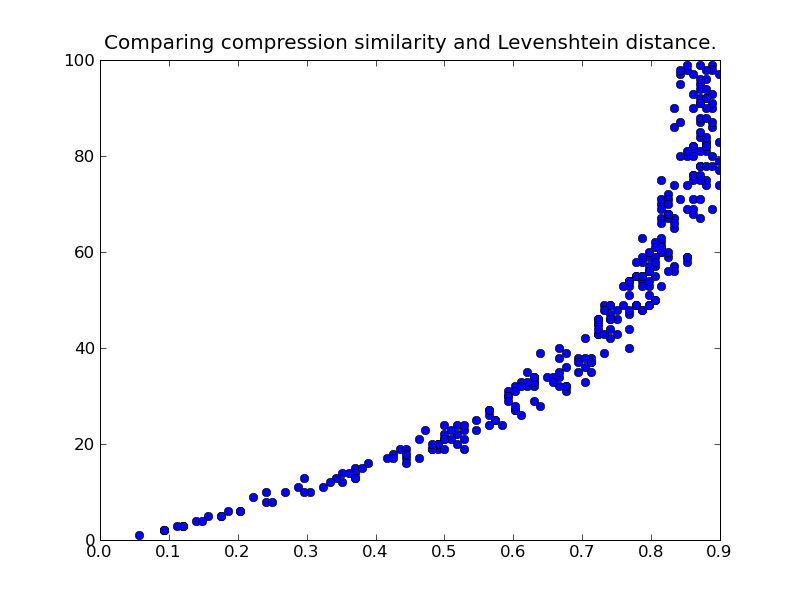
Hi,
Have written a script that downloads rss feeds, compares the latest download with the one before using md5, and if they're different sends an email with the updated headlines.
However, have noticed the email update is sent even for a change as minor as the insertion of a comma.
Is there a method to compare files that shows the degree of similarity?
From searches so far it seems the vector space model would do the job but it looks pretty tough to use for someone who is an absolute beginner to python, so would love to hear of any alternatives.
Blair