
Hello again
The following method for counting occurrences in a table and storing the result in another table works fine on my mysql version 5.1.48:
create trigger comment_count AFTER INSERT on comments
FOR EACH ROW
BEGIN
declare cnt int;
select count(id) into cnt from comments where article_id=t1.id and published=0 and status=0;
UPDATE sub_sections as t1 SET t1.published_comment_count = cnt
WHERE id= NEW.article_id;
END;The into-clause is only allowed within stored procedures&functions and in triggers or in embedded SQL. Within triggers you can make use of almost all features of stored procedures and functions as explained in 12.7. MySQL Compound-Statement Syntax of 5.1 manual. These are true PSM programming language features as standardized in SQL 1999/2003.
I have also used NEW.article_id instead of subselect for NEW selects the just inserted value of column article_id from table comments.
The trigger can also count occurrences in the table which just invoked the trigger itself, there is no restriction (as I had supposed).
-- tesu
Well, if I understand you correctly, then you want to select all product types together with the product types associate with a relevant team within a single query. This can be done by set operations union and difference or by subselects.
I'll explain it step by step. First, let me allow to change the naming of your columns a little to have a more handy scenario:
Given three tables teams(teamid, team), products(productid, product_type) and a linking table team_product (teamid, productid), where the latter defines the many-to-many relationship between teams and products. Columns with id-suffix in their names denote the primary key.
1st step: Select all product types of the relevant team, say for teamid = 2, from linking table team_product
select teamid, productid from team_product where teamid = 2;
/* result
teamid productid
----------------
2 2
2 4*/2nd step: Select all product types from table products
select productid from products;
/* result
productid
---------
1
2
3
4
5*/3rd step: Combining both result sets by union set operation
To adjust the number of columns a formal -1 is added as teamid to the 2nd select to get two columns. This also allow to differentiate between product types already associate to a team and other product types the team not have chosen so far.
Modified select statement from 2nd step:
select -1 as teamid, productid from products;
/* result
teamid productid
----------------
-1 1
-1 2
-1 3
-1 4 …Hello
Derby/JavaDB & JDBC/type2/3 is a perfect basis, I also use it in netbeans-developement. If you put all attributes together in just one relation/table, you will run into problems like insert/update/delete anomalies. Then you will be forced to patch by Java code for SQL queries will not work or too difficult to design. Therefore NF (3NF) is a must!
You can post your tables and key-definitions so we can discuss them.
-- tesu
Hi,
EXPLAIN always shows the number of all rows if filesort is required for GROUP BY and ORDER BY clauses. I have examined over ten queries on a larger mysql database. No matter how the where clause looks like, EXPLAIN always quotes the number of all rows plus something more (see table below)! The result by EXPLAIN cannot considered to be a true execution plan.
I generated a test program using your select statement and table definition on Sybase database system. The execution times for number of rows from range 100,000 up to 1,000,000 were between 0.23 and 1.89 sec.
Porting this PSM and C program to mysql is rather impossible for there are too much limitations, for example creation of tables or indexes within a user defined function are not allowed for mysql always associate an implicit commit with DDL, and as a result, the function will be aborted. Also subselect (from clause) will not be carried out properly.
So I wrote a little PSM function for mysql to generating random data in the style of test tools on Sybase. I regarded the data ranges you quoted. However, the analysing and statistical methods can't be implemented on mysql, just fancy it doesn't have any output functionality for user defined functions! So one can't send any result to user screen. I can only show you the execution times on mysql database, here is the result:
/*
reps rows insert (sec) select (sec) drop+create (sec) rows …Hi
This trigger is invoked after a row has been inserted in table comments. Within the trigger you can access all just inserted column-values by NEW.column_name, for example NEW.article_id ist the article_id of the row just inserted.
>> where article_id=t1.id and
If article_id is from the trigger-invoking table comments, use: where NEW.article_id=sub_sections.id and.
I have also replaced alias t1 by table name sub_sections for mysql has a rather weird notion of aliases in where-clause.
>> WHERE id= (select article_id
If you want to get the article_id which has been just inserted, use: WHERE sub_sections.id= NEW.article_id
As for the select count(id)... I am really not sure whether you will already have access to table comments on this conventional way by using select etc because you are in the trigger which is invoked by inserting a row in that table. You could test it with a simpler trigger.
You may also consider that on older versions of mysql (before 5.1?) the user who creates triggers must have super privilege. If not, behaviour of invoked triggers are indeterminate.
-- tesu
Hello
Well, you could get better help if you were more precise on which tables exist and, important too, how they are related to. As rch1231 already did I also see some of these objects:
1st usertable pk(ipaddress, userid) ?
2nd useractivitytable fk(ipaddresse, userid), what pk ?
3rd activitytable pk(activityid) ?
If so, there might be a many-to-many relationship between usertable and activitytable which could be given by useractivitytable. To form the many-to-many relationship correctly the linking table useractivitytable must have: fk((ipaddress, userid) AND fk(activityid).
At least both foreign keys must be part of useractivitytable´s primary key: pk(ipaddress, userid, activityid). If those keys were correctly definded, you wouldn´t get slow sub-selects or joins (assuming there are some 10000 or better some 100000 entries in the linking table at least. Hint: Fetching 20% of about 1000.000 entries in useractivitytable should last about 1 to 2 seconds on mysql database (innodb) + medium-power computer).
However, I am wondering why ipaddress is part of the user´s primary key. If you are interested, we can discuss this until your tables and relationships are clearly known.
-- tesu
You are using "0" for labelling the root of a tree. If "0" is a numeric value, it may function. If it were NULL, you can't get the root by my first select. For example:
SELECT cpy_id, cpy_name FROM cpytable WHERE cpy_id IN (SELECT parent_id FROM cpytable WHERE cpy_id=4444 OR parent_id=0);gives parent of 4444 and ALL parents having parent_id = 0, those are all parents theirselves. To differentiate between the root parents why not setting parent_id = cpy_id, as for example:
cpy_id cpy_name parent_id
1111 "ABBB" 1111
2222 "CDDD" 2222
3333 "ABBB Japan" 1111
4444 "CDDD China" 2222
-- and the first select could work:
SELECT cpy_id, cpy_name FROM cpytable WHERE cpy_id IN (SELECT parent_id FROM cpytable WHERE cpy_id = 4444 OR cpy_id = 2222);-- tesu
I understand your concern completely. I know by extensive experiences that one can hardly trust that database system besides its considerable lack of basic functionality of ANSI SQL standards. I have never met another such error-prone database.
The only way to figure out whether tablesort is carried out on only those rows constrained by WHERE-condition is doing tests. You may automatically generate test data and carrying out your query on increasing numbers of rows measuring their execution time.
To get expressive results, your table must be correctely defined, especially there must be primary and foreign keys as well as most likely an index on column question_id. Just a day ago I did a similar test on a Sybase database where I have comprehensive test tools for investigating SQL statements. However, it isn´t that difficult and costly to write a simple test case for your individuell problem. I can support you. So you can post your exact select statement you want to investigate.
-- tesu
In your example say, 1 and 4, is 1 identical to 1111 respectively 4444? if so, this select could help:
select cpy_id, cpy_name from cpytable where cpy_id in (select parent_id from cpytable where 'your criteria to get 1 and 4');However, if 1 and 4 kind of level, than I would add level number to your table:
cpy_id cpy_name parent_id level
1111 "ABBB" 0 1
2222 "CDDD" 0 1
3333 "ABBB Japan" 1111 2
4444 "CDDD China" 2222 2
-- and the select could be for example:
select cpy_id, cpy_name from cpytable where cpy_id in (select parent_id from cpytable where level = 2);
/* result
1111 "ABBB"
2222 "CDDD"
*/Btw, there is a famous guy on the internet: Joe Celko, he wrote a book only dealing with SQL and trees, hierarchies. You may google celko trees sql.
-- tesu
Hi
I am really confused, how is your "set of values (1,4)" related to your example table? An why you decide that then you should get the names 1 and 2? The names 1 and 2 point to what of your example table?
I understand that your table is kind of recursive table which defines a tree because parent_id points to rows in same table, however I don´t see the pair (1,4) in that table.
-- tesu
Supposing that the calculated sum(score) were correct, you already wrote that the result were fine and you might have already computed this sum manually, and further, If there are only 14 rows having question_id = '4' as you just reported, then the ORDER BY score can only include these 14 rows and no any further rows.
If all 547 were sorted in decending order, the sum would have been plain wrong, except all score values are equal. That means that the tablesort needed for sorting only considered these 14 rows and not the indicated 547 rows. Thus, for some reason EXPLAIN reports wrong row number.
This is why I tried to explain the steps your query is executed in particular and why I asked how many rows fulfill question_id = '4'.
Addition: You can proof this immediately: Look up the maximum score values for question_id other than '4'. If you find one which is greater than any of the 14 score values for question_id = '4' AND sum(score) is correct, then you have got the evidence that only those 14 row were sorted by tablesort.
-- tesu
Hi
These tables can hardly be joined together for the 2nd query does not contain table v_Add_Remove_Programs of 1st query. Possibly the program what auto-generated the second query could know how v_Add_Remove_Programs is related to the tables v_GS_LOGICAL_DISK, v_FullCollectionMembership, v_R_System etc. of 2nd query. One also need to know where to find column DisplayName0 in those tables.
-- tesu
Just out of curiosity: Is there also an error message or faulty behavior of that code?
Supposing your update and subselects are correct, I would replace END; by END | for you have chosen delimiter |
-- tesu
So let’s say i have a table with one column containing the following 6 records:
[SR No#]='111' [Club Name], [Problem / Symptom Description],
[SR No#]='111' [Club Name], [Problem / Symptom Description],
[SR No#]='222' [Club Name], [Problem / Symptom Description],
[SR No#]='222' [Club Name], [Problem / Symptom Description],
[SR No#]='333' [Club Name], [Problem / Symptom Description],
[SR No#]='444' [Club Name], [Problem / Symptom Description],After using the DISTINCT Command on my SQl Statement It should display
[SR No#]='111' [Club Name], [Problem / Symptom Description],
[SR No#]='222' [Club Name], [Problem / Symptom Description],
[SR No#]='333' [Club Name], [Problem / Symptom Description],
[SR No#]='444' [Club Name], [Problem / Symptom Description],
Hello,
The solution you need deals with the question on how to eliminate duplicate rows from a table. On MS SQL Server there has been a very effective approach given by the new OLAP extensions since SQL Server 2005. You only need the new added aggregate function row_number() and the partition method (from the mighty OLAP functionality) to add an appropriate row number to every row what then easily allow to filter out duplicate rows. For I don't like the notation with those square brackets I am using simple names you can easily translate into your brackets notation.
Consider this query which makes use of the new aggregate function row_number():
select srno, clubname, problem, row_number() over (partition by srno order by srno) as ronu from sheet1 order by ronu, srno;
/* result: …Hi
Thanks for posting your data.
Finally I figured out why my suggested query never ends on your Mysql database if there are just 10585 rows affected. The reason is that simple and also that frustrated: MySQL does NOT have effective Query Optimizer. I found that indirectly by calculating the execution plans for my select statement on those databases: MS SQL Sever, Oracle and Sybase SQL Anywhere. All these three database systems replace slow correlated selects by fast table join operations! Query optimizing is quite usual and virtually almost all database systems have this useful functionality except mysql.
On Sybase database I have SQL test tools for testing and optimizing select statements by means of automatically generated test data. I fed the test tool with the select statement in question, defined your both table and necessary data pattern for automatic generation of test data.
Testing was carried out with the following volume: table viscawangan 10585 rows (your number), historytable 105850 rows. I decided that each branch_code should have 10 randomly generated date_update and amount_of_people values on average, that is 10 times 10585. So the total amount of rows processed in first inner join was 116435 rows. The result set contained 9843 rows something less than viscawangan rows for I allowed that also viscawangan rows were generated without entries in historytable.
Testing result for this scenario: Execution time 0.445 seconds (less than a half second). Well, that's it, the result of a true relational database system.
… Tesu,
The count record is 10585.
Well, 10585 rows is something heavy for correlated selects. Can you tell me the indexes and keys which are chosen for this query? Simply run
explain
select v.branch_code, v.branch_name, h.date_update as date_latest, h.amount_of_people as amount
from viscawangan v join historytable h on v.branch_code = h.branch_code
where h.date_update=(select max(date_update) from historytable where v.branch_code = branch_code) order by v.branch_name;Then post its result. Also post your original select what you have derived from mine.
You see the max(date_update) above. Can you estimate from how many row per branch_code the max() is taken?
I think, if you put an index on (branch_code ASC, date_update DESC), execution time will be substantially reduced.
-- tesu
Well, you should carefully read my posting. The cited error message is very clear.
You chould verify the old content of SQL Server table "text_data" with the content of "updateprice.mdb" which you are trying to insert into table "text_data". If primary-key column "Text_Id" of table "text_data" already contains values of the corresponding column of "updateprice.mdb", there is a "Violation of PRIMARY KEY constraint 'PK_text_data'".
If there aren't any duplicates, well, then it will become more difficult. The mess is that '80004005' is a common error number what stands for a fair quantity of individual errors!
You can get further detail error information by enabling the error log of your ODBC datasource. This can be done by starting MS ODBC management tool, checking the log mark and entering a file name where the log data should be written to.
-- tesu
Well, my suggested query should meet your requirements. Can you examine how many rows this join viscawangan v JOIN historytable h on v.branch_code = h.branch_code includes by executing:
select count(*) from viscawangan v JOIN historytable h on v.branch_code = h.branch_code;The drawback of my suggested query is that it uses a correlated query (WHERE v.branch_code = branch_code) what becomes very slow if a plenty of rows are affected and no index or key can be used.
One can speed up correlated queries by putting indexes/keys on the appropriate columns. In your case the max(date_update) is the obstacle. Therefore you could index the important column date_update of historytable. And you should then use EXPLAIN to examine whether this newly generated index is really used in the correlated queries.
I am about to thinking over whether these correlated queries might be replaced by better query not having correlations, however, I am afraid there is no other solution. If so, only additional index/key on column date_update of historytable wil be able to speed up calculation considerably.
-- tesu
well jwebb, this is kind of "disimproving".
Why didn't you exactly do what I suggested?
int factorial(int input)
{
// my suggestion and NOTHING else!
}
int main(){
int input;
cin >> input;
cout << factorial(input);
return 0;
}-- tesu
Well, and the body of function factorial(...) should be better completely replaced by
{
if(input<=1) return 1;
else return input*factorial(input-1);
}I am glad that the result of the final query has met your notion.
Sometimes it is like not seeing the wood for the trees, for I was too much fixed on filtering the rows by both status in the where-clause what was a plain wrong idea.
When you mentioned that there could also be duplicates because I omitted week of history, the solution by way of set difference became clear. Unfortunately, I forced you to post an extensive example which was not any more necessary, sorry for this additional work.
-- tesu
Let me try to explain what happen when your query executes:
To filter out all rows having '4' key question_id is used. 547 rows are affected. Next step is sorting the result set in descending order on column score. Obviously there is no Index/key on this column which could support this sort. Therefore all rows in resultset must be explicitly sorted by tablesort. Finally the sorted resultset is skrinked to ten rows having the highest score values in descending order. This shrinked resultset is returned in from clause where the sum() is calculated from.
Explicit tablesort carried out by a fast sorting method like mod. quicksort or mergesort must always be done in the context of group-by or order-by clauses if no convenient index or key is available which would speed up sorting considerably.
Using a subselect is completely correct for the sum() should be done over the 10 highest score values. If you write select any_aggregate_function(...) from answers limit 10, then any_aggregate_function(...) is always carried out on ALL rows of table answers. Limit 10 is useless in this case.
You may try count(*): select count(*) from answers where question_id = '4'; What is the result?
-- tesu
Meanwhile I have got an idea which deals with difference operation on sets (A \ B = {x | x element(A) and not element(B)}, sorry this math is not that important) which is MINUS (Oracle specific) or EXCEPT, the latter is a standard operation in ANSI SQL, however mySQL does not support set operations except UNION.
One can simulate set difference by means of subselect. You may try this code:
select distinct tc, serial from history
where tc not in (select a.tc from history a join meter b on a.serial = b.serial where b.status=1);Pls try it out, I haven't test this code so far. Tell me the result asap. Then I'll dive into your examples.
-- tesu
Hello
>>> I think the reason the code is returning TCs with status 1 METERs is because of the
same problem?
Yes that's it, that's a mess with the many-to-many relationship. Now I understand why you put week in primary key of history. you needed it to get unique row id.
>> Therefore TC 00803 should not be...
where is 00803 in your above examples?
The suggested select isn't appropriate for your problem because of many-to-many. So we need more information to filter the correct rows. This points to table HISTORY: Can you state a more complete example containing all columns of its primary key (serial, tc, week, ?) and their associate instances of TC and METER with their pk's too?
If you are further interested in examining data, week must be listed in query for it is an additional differentiator:
SELECT h.SERIAL, h.week, count(h.tc) FROM TC t JOIN history h on t.tc = h.tc GROUP BY h.SERIAL, h.week;-- tesu
Well, you are working on MS SQL Server.
The error message:
Violation of PRIMARY KEY CONSTRAINT 'PK_text_data'. Cannot INSERT duplicate key IN object 'text_data'.
means that the new row you are trying to insert in table text_data already exists. That happens if one inserts same data twice.
You can examine this by using sql server management console and query table text_data, for example:
select * from text_data;
The output can then be verified with the notpad or excel data. (If text_data is too large, you may reduce selected data by adding a where clause above.)
-- tesu
There are many people looking for normalized hotel systems. Even Richad Nixon once did so in China by the time Edgar Frank Codd borrowed the normalization theory from him.
So can you be more specific? What have you got so far?
If both Agent and Owner don't act with the system for they only fill in forms from which data will be captured by staff personal they aren't direct actors. Therefore they don't have use cases. For that reason I would omit Agent and Owner.
-- tesu
Hello
Yes, company is not an entity. Your explanation is correct. If your application is to manage many such parcel-service companies, it were a multi-client software (like SAP R/3).
There are further entities I have found at a first glance:
- Delivery_options and conditions
- Serice_stations, especially where packages are being tracked
- Package_Movement (locations, timestamp, conditions)
- Delivery_details (including recipient's confirmation)
You could draw and post in an ERD (nice tool is freeware visual paradigm) so one can examine its completeness and correct relationships.
-- tesu
Your statement:
with many METERS in one TC
(and)
each METER only having one TC
defines a true one-to-many relationship (primary key of TC is attribute of METER).
However your linking table History contains foreign keys serial and tc of related tables. So this is a true many-to-many relationship what allows that one METER could have many TC.
You can examine whether your tables contain consistent data with this query:
select h.serial, count(h.tc) from TC t join history h on t.tc = h.tc group by h.serial;If count(h.tc) > 1 then there are METER having more than one TC, thus inconsistent data.
As for your query, due to the clause "where t.status = 1 and m.status = 0" it must only list METER having status 0 and TC having status 1. Yet I think your are not that content with the query's result. Can you give more details how the result should look like?
-- tesu
Hello,
If I understand you correctly, there is a many-to-many relationship between METER and TC where the linking table is HISTORY (has got pk serial and tc from METER and TC). Primary key of HISTORY consists of (serial, tc, week, create_date). Then the select could be:
select h.`week`, h.create_date, ... further data ...
from METER m join HISTORY h on m.`serial` = h.`serial` join TC t on h.tc = t.tc
where t.status = 1 and m.status = 0 order by h.`week`, h.create_date;Hope, this will help you a little.
-- tesu
Hi
Supposing your both queries select staffids which are not on holidays OR in
sessions you should select staffids which are in both result sets:
select * from staff
where staffid in (your select not on holidays )
AND staffid in (your select not in sessions);-- tesu
Hello
first, put your code between code tags and improve formatting:
select dp.product_lob As lobs,
SUM(fs.written_premium_amt_ytd) As Gross_written_premium [B]from[/B]
--xxx-- opening parenthesis
(select
dp.product_lob As lobs,
SUM(fs.written_premium_amt_ytd) As Gross_written_premium
FROM dbo.Fct_Summary as fs
inner join Dim_product as dp on ( fs.product_key = dp.product_key )
inner join Dim_Calendar as dc on ( fs.calendar_key = dc.calendar_key)
where dc.calendar_month_name like $P{Month} -- what's that?
Group by product_lob,
written_premium_amt_ytd -- not necessary for it is used in sum()
order by SUM(fs.written_premium_amt_ytd) desc -- not allowed in that clause!
) -- closing parenthesis from --xxx--, therefore this is missing here: AS musthavename
from -- here illegal for you already have a from clause (bold-marked)
dbo.Fct_Summary as fs
inner join Dim_product as dp on ( fs.product_key = dp.product_key )
inner join Dim_Calendar as dc on ( fs.calendar_key = dc.calendar_key)
where rownum<=5 -- Oracle knows this, but MS Sql Server doesn't it?Second, no matter whether the overall select may ever produce usefull results, there are too much mistakes. The ones I could figured out are red-coloured + comments (--). You may correct your query but I am afraid it will not give satisfied results. Why do you interleave two almost same queries into each other?
I think it is a good idea to test select parts of this complex statement first, then
mount them together.
Selamat Siang
Tell me what will be the result if you carry out this:
select v.branch_code, v.branch_name, h.date_update as date_latest, h.amount_of_people as amount
from viscawangan v join historytable h on v.branch_code = h.branch_code
where h.date_update=(select max(date_update) from historytable where v.branch_code = branch_code) order by v.branch_name;You may examine all words and syntax, there might be typos etc.
-- tesu
Hi red_ruewei,
the result corresponds completely to your select statement. However, it seems that it does not meet your concept. So what's wrong, what should be the exact result? Can you give an example? (Unfortunately, I have deleted the data once you sent to me. So I am unable to look inside the problem).
-- tesu
Of course!
Nevertheless, you might post in what you have got so far. I don't like to give you complete solution based on your rather complete proposed paper.
-- tesu
Do you select directly from R/3 tables or make use of sap transport system? If selecting directly, you may explicitely lock the concerning R/3 tables to be sure that nobody makes changes before finishing your copy-transaction.
On sql server I would write a transact stored procedure. The effort to spend for 10 or 20 sql selects and further for 10 to 20 updates isn't that important when running in a procedure.
Idea:
Instead of comparing each value individually, sometimes it's useful to work with checksums. While fetching the data for copying them you compute a before-checksum. After finishing copy-transaction successfully you compute after-checksum. If they differ, you may rerun copy-transaction.
-- tesu
You are right!
Drop both from the list. I already kept the ERM design in mind when writing them down.
Both updates require different where-clauses. Therefore you can't do these updates within one update-statement.
May I ask you why you would like to execute both updates within one statement?
-- tesu
Hi muppet
Usually I don't like to meddle into progressed postings. However, this time let me allow to ask whether you are still want to calculate the down times from your priorly shown example table (heading: running | error | timestamp). Reason is I feel rather confident that this table is quite well designed for straight calculations with simple methods for processing consecutively stored rows. Even you don't need running-column. Error and timestamp columns are entirely sufficient.
-- tesu
ochi, ime stin germania (bavaria). ya diakopes tha imai sti aegeou (limou, lesvou, shiou.. kathe xrono).
From your text one can draw some actors / roles which also become classes in OOA:
TAT staff (employees, role: Enquiries Desk)
owners
agent(s)
Properties
holiday resorts (two at least)
Customers
Mapping them into ERM (later database) all of them become entities and later tables.
I myself switched to visual paradigm tool recently, which allow designing both UML 2.0 and also ERM (Chenn) diagrams. Do you know it?
You may post your use case diagram.
-- tesu
Hi andyjeans,
glad to meet you again.
... SELECT Product2ID, 'Product2', c.ClientID, c.App1FirstName, c.App1LastName, c.App1Email,c.App1Phone, c.App2Email, c.App2Phone, p.clients_ClientID
FROM clients c JOIN Product2 p on c.ClientID = p.clients_ClientID
WHERE p.clients_ClientID IS NULL
GROUP BY ClientID
...This is again wrong. All database systems but one stringently refuse execution of that wrong select-statement for it is a severe contradiction to relational algebra and set theory. However mysql let user be defining and executing such stuff.
We have already discussed the problem of incomplete group-by clause in earlier postings. You may also find something more here.
Btw, "WHERE p.clients_ClientID IS NULL" is formally correct, for it refers to a foreign key in an one-to-many relationship where NULL values are allowed on the many-side. However, it cannot be used that way in ON condition as rch1231 already stated. A primary key cannot be NULL (on the one-side)! Therfore no results.
-- tesu
Kalimera, ti kanis (supposing you are living in the south part)
UML-CS Actors could also be entities on ERM (and tables on RM later) depending on their relevance and scope of their data. Usually they are attributes of an entity named ACTOR, if necessary.
If you had disclose some more details on your project, I would have given you better guidance.
-- tesu
Hi
You already have got this:
select name, country_code from city where population >= 5000000);If you omit "name", you get a country_code list with all countries having at least one city with pop. >= 5000000.
select distinct country_code from city where population >= 5000000);This list can be used to get all cities of a particulary country where the condition is true:
select "Name" from city where country_code in (select distinct country_code from city where population >= 5000000);You may add further country data by inner join:
select city."Name", country."Name" from city join country on city.country_code = country.country_code
where city.country_code in (select distinct country_code from city where population >= 5000000);You may omit or replace delimeters " " by mysql ` `. For "Name" is a reserved word in most database systems it isn't a good idea to use it for a column. In such case some database require that the word be surrounded with delimeters.
There is also an if-statement (if (cond) then ... else... end if; ) what can be used in user definded functions written in PSM language. This is supported by mysql. Unfortunately, mysql does not support the ANSI SQL if-statement for select-statements, yet it has case-statement.
-- tesu
hi,
decimal 12345 is hex 0x00003039. So to get a more practical example I changed:
character=*((char *)(&adad)+2); // 0x00 is storedto:
character=*((char *)(&adad)+1); // 0x30 is storedAssuming Intel processor, the assembly should look like:
lea ebx, adad ; address points to 0x39 (little Endian)
add ebx, 1 ; address of 2nd byte, points to 0x30
mov al, [ebx] ; loads 0x30 into reg al
mov character, al ; stores 0x30 into characterAfter execution above code:
printf ("character: %x\n", character);should output character: 30
I hope this is a little help.
Addition: Instead of add ebx,1 and mov al, [ebx] also displacement addressing: mov al, [ebx+1] is possible.
-- tesu
>>> You have saved this project from derailment. I will put forward 'Tesuji' as the name of our next born son in your honour.
Haha, I cherish you, yet you should grasp tesuji´s meaning above all. (Indeed, it has really good meaning in Japanese once I accidently came across with due to the initials of my names Te. Su.)
My problem with mysql is I actually almost never use it seriously, except for customers asking to getting some help if their badly designed applications, what's typically inherent in the mysql system, let programming costs explode.
tesu
well muppet,
yes, there are other solutions up the sleeve, for example a permanent view (for mysql's unability processing standard sql with clause) or simply a stored procedure which returns the union-part of the censured query.
However such stuff wouldn't have been necessary if one had simply replaced ansi sql standard delimeter " " by mysql's propritary well-known ` ` ones! You may study attached screen shot below.
I wish you all the very best!
-- tesu
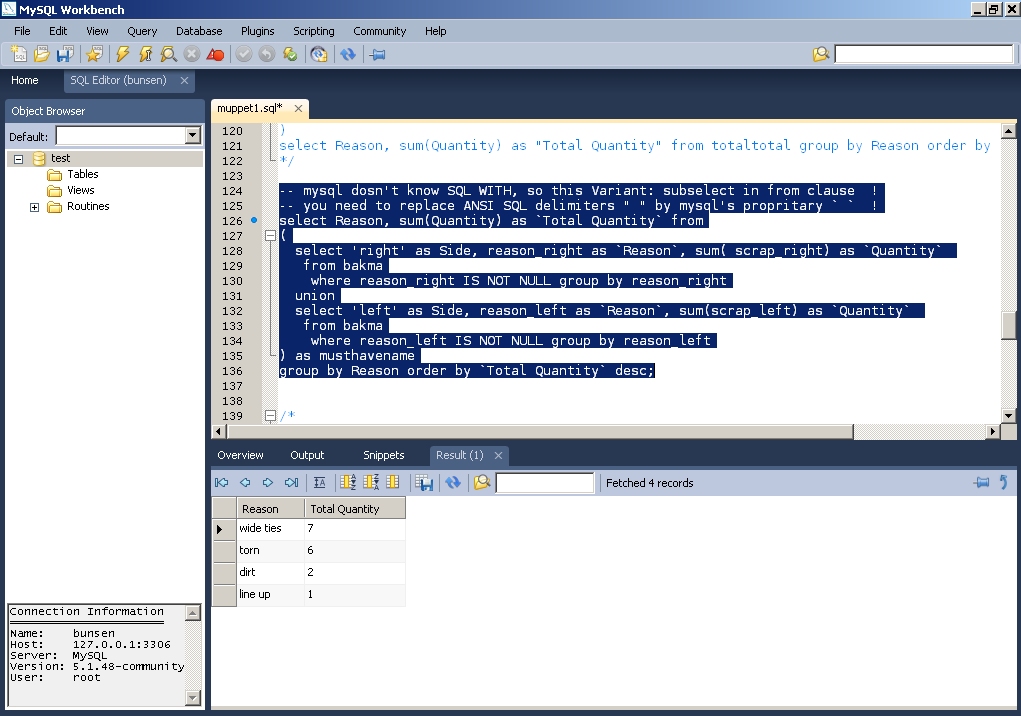
Don't worry there are two further tries to go which I know from (or feel so at least)
Ah muppet, too bad that mysql still don't support ANSI SQL WITH-clause which has been introduced since SQL 1999 standard.
Yet there are some other approaches to solve it even on mysql.
So next try:
select Reason, sum(Quantity) as "Total Quantity" from
(
select 'right' as Side, reason_right as "Reason", sum( scrap_right) as "Quantity" from bakma2
where "Reason" IS NOT NULL group by "Reason"
union
select 'left' as Side, reason_left as "Reason", sum(scrap_left) as "Quantity" from bakma2
where "Reason" IS NOT NULL group by "Reason"
) as musthavename
group by Reason order by "Total Quantity" desc;Should function on mysql for msyql manual tells that subqueries in from clause would be fully supported now. I am about to believe that :D
Result might be as desired:
| Reason | Quantity |
| wide ties | 7 |
| Torn | 6 |
| dirt | 2 |
| line up | 1 |-- tesu
Aha age columns. That makes the query tremendously simpler:
SELECT all_my_dating FROM mytables WHERE age BETWEEN 30 AND 35;... BUT: where keeps the DOB file? And will those ages be manually updated in database just before or just after pupil's birthday partys every year?
-- tesu