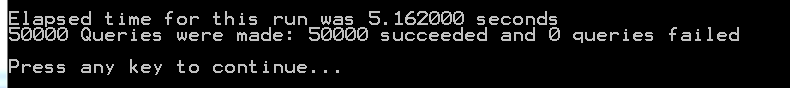@CSE.avinash:
Your program has too many zeroes in the size of the array! You should only have SIX zeroes in the size of your array, not eight.
As it turns out, the Sieve of Eratosthenes is faster than any of the other sieve prime number generators unless you optimize the others. I ran one against the new Sieve of Atkins I just coded up (with huge pseudo code help from Wiki), and it was actually faster than Atkins' Sieve, by a hair, going up to a max of 5 million.
I know with some optimizing, I can bring down the times on Sieve of Atkins', but I believe we can use the Sieve of Eratosthenes, just as well. Smeagel, I'd like to see the test times of your program handling 50,000 Queries, with an average kth of 2,500,000. I know I gave you the wrong number before. Brain not working! ;)
We can compare that with the Sieve of E. program CSE brought in, and see how they compare in that same 50,000 query test, if Smeagel has the time to test CSE's program, also. I'd do it, but it should be done on the same system to be meaningful.
@CSE: what size of array for holding primes would you recommend? I'll make up whatever size you want to try out for some testing. Maybe 10,000 would be OK? Better would be 25,000 or more, but what is the largest array you can use in …