Hi everyone!!
Help me please with my script. I'm using Perl Express for scripting in .
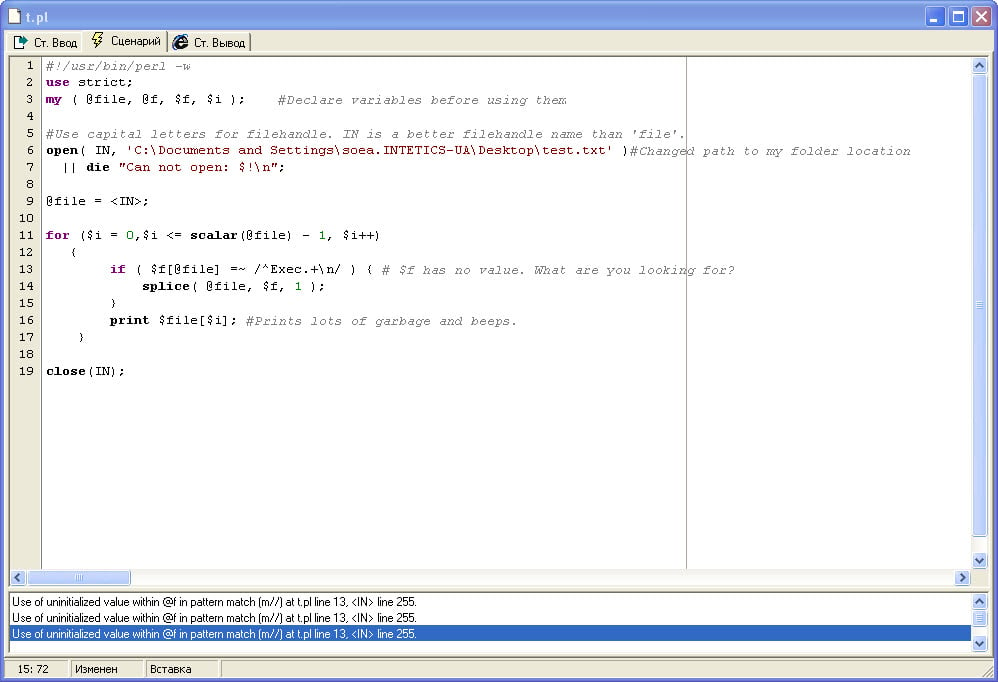
This is my script:
use warnings;
use strict;
open (file,'C:\Documents and Settings\soea\Desktop\Test.docx') || die "Can not open: $!\n";
@file = <file>;
for (my $i = 0;
$i<=scalar(@file)-1;
$i++;)
{
if ($f[@file] =~ /^Exec.+\n/)
{
splice(@file, $f, 1);
}
}
close (file);This is output:
Unrecognized \D passed through at ... line 6
Unrecognized \s passed through at ... line 6
Unrecognized \D passed through at ... line 6
Unrecognized \T passed through at ... line 6
Global symbol "@file" requires explicit package name at ... line 7
.....