Hello, I've downloaded PythonWin as a better IDE for writing Python code.
I came across an interesting issue (as vegaseat pointed out)
When I try to write this sentence in my native language
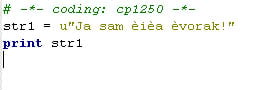
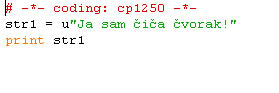
"Ja sam ia vorak!"
PythonWin automatically convert my language's charater to something other because it cannot handle them. However if I start Python default IDE (which came with installer - IDLE) this code works fine
# -*- coding: cp1250 -*-
str1 = u"Ja sam ia vorak!"
print str1How this is possible? Do IDE's yuse different font or what?
HOW IT IS POSSIBLE THAT ONE EDITOR SHOWS CORRECT CHARACTER AND OTHER DOESN'T?
I must admit that I don't understand how to use UNICODE and will UNICODE will help at all?
if I copy that changed text form PythonWin and paste it here changed characters are back again in what I've expected.
Maybe because of your windows local settings you cannot see exact characters, that's why I send two pictures.
I hope someony can clearfy this
Thanks