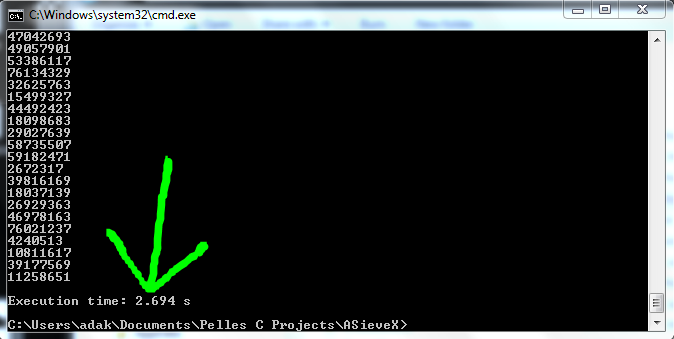
A few timing facts, for the curious. These were all run on the same PC, which was otherwise not busy.
The "A" algorithm, was the one that used the Sieve of Eratosthenes, but not the best one from CSE (it was getting 4.65 on the IDE and 4.0 on the terminal). It was "almost as good as CSE's version", but it was much simpler to test with.
Note: A "terminal" is sometimes called a Command Window, in Windows.
This included an aux1 (auxiliary) array (sometimes called Big[]), that held LOTS of prime numbers (a few hundred to a few thousand), to try and get a feel for the effect on the timing. Data shows the aux1 array was helpful, but not very much. At the largest number of primes we could use for the challenge, it could save 0.3 seconds, only (on my system).
The "B1" algorithm used no aux1 or big array of primes, at all. The k queries were sorted by Quicksort, and printed as they were generated, inside the loop that finds the primes - one number per call to printf().
The "B2" version of the algorithm is similar to the B1 version except the answers are not printed right away. They're stored in an array, and then printed out with multiple numbers being printed, in a single call to printf(). I'm experimenting with printing 125 numbers per call to printf(). Also, the query (kth) numbers are not sorted.
I believe the sorting would have the challenge test fail because the replies would be in the wrong (sorted), order. I could correct it, but it simply isn't fast enough.
I believe we know what the answer is, and we just have to find the best way to use it. My next test should be the best, using the B2 version.
With the "A" Algorithm:
=========================
With Big[]or aux1 array, common IDE times are 5.40 seconds
with one number per call to printf().
With Big or aux1 array, printing 128 numbers per
call to printf(),(in the terminal) times are 2.61 seconds
Inside the IDE: . . . . . . . . . . . . . . 3.48 seconds
With the "B" Algorithm:
==========================
Has no big or aux1 array at all. Each number is
printed with one call to printf(). in the IDE
The kth numbers are all sorted first. 5.38 seconds
Same as directly above, but in the terminal
instead of in the IDE. 4.58 seconds
Same as above, EXCEPT, 1.the print calls are not Should be good! ;)
made one at a time. Many numbers are printed
with each call to printf(), and 2. The kth
query numbers, are not sorted.I don't expect to use the aux1[] array again. More hassle than it's worth, imo.
File size is currently (with the B algorithm), below 5KB, so no problem with our size.
I'll be doing the B2 test, this evening, after I finish modifying the current code.
Have you tried the "print many numbers with one printf() call", idea, in your program yet? If so, how did it perform?