So I am trying to do a neat little script in a wordpress plugin that replaces matching keywords with links to other articles on the site. I think I'm done all except one little thing down here below.
I need to fix the preg replace function.
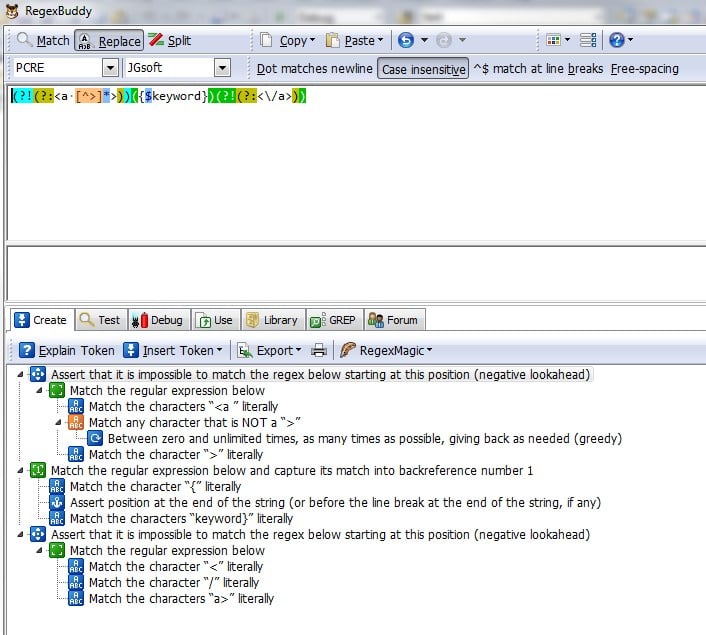
It should match anything that...
* is not inbetween < and > chars
* is not between any <a> and </a> tags (not stricktly mind you, but a tags with href's and target's and anything else you can put in them)
* will not mess up any existing html (if you can think of anything)
If you could lend me a hand with this regex stuff, and if you can a short explaination, that would be terriffic!
<?php
//$words = array(); // this is full of keywords and urls, loaded earlier in the script
krsort($words); // Sort by key (reverse) with the bigger key word groups first.
// Now go through the entire post, and replace the matching and previously unlinked keywords with the links :)
foreach ($words as $k => $v){
foreach ($v as $keyword => $url){
$content = preg_replace("/(?!=(?:<a [^>]*>))({$keyword})(?!(?:<\/a>))/si","<a href=\"{$url}\">{$keyword}</a>",$content,1);
}
}
?>
As of right now, I get these errors (link 67 is the preg_replace() line above):
Warning: preg_replace() [function.preg-replace.html]: Unknown modifier 'B' in C:\xampp\htdocs-wordpress-dev\wp-content\plugins\Johns-Interlink\index.php on line 67
Warning: preg_replace() [function.preg-replace.html]: Unknown modifier 'a' in C:\xampp\htdocs-wordpress-dev\wp-content\plugins\Johns-Interlink\index.php on line 67
Warning: preg_replace() [function.preg-replace.html]: Unknown modifier 'B' in C:\xampp\htdocs-wordpress-dev\wp-content\plugins\Johns-Interlink\index.php on line 67
Warning: preg_replace() [function.preg-replace.html]: Unknown modifier '/' in C:\xampp\htdocs-wordpress-dev\wp-content\plugins\Johns-Interlink\index.php on line 67
Warning: preg_replace() [function.preg-replace.html]: Unknown modifier 'T' in C:\xampp\htdocs-wordpress-dev\wp-content\plugins\Johns-Interlink\index.php on line 67
Warning: preg_replace() [function.preg-replace.html]: Unknown modifier 'P' in C:\xampp\htdocs-wordpress-dev\wp-content\plugins\Johns-Interlink\index.php on line 67
Thank you!