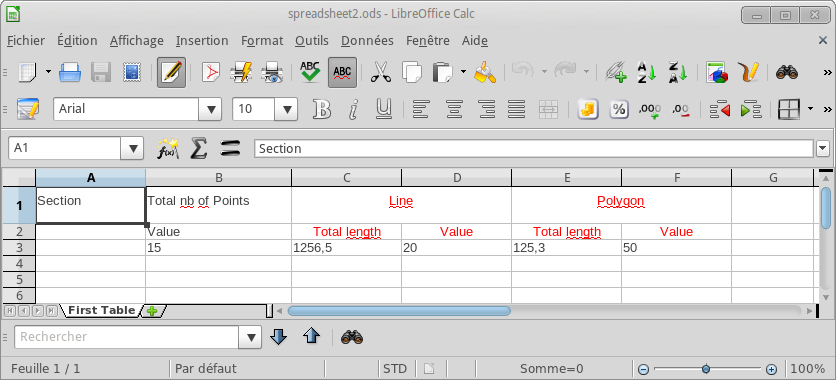
I think this is not possible in csv. Csv does not contain any cell style information. I was able to produce an open-document spreadsheet using the development version of lpod-python (the function to merge cells was added 1 month ago). Here is the code
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
from __future__ import unicode_literals, print_function, division
import os
from lpod.document import odf_new_document
from lpod.table import odf_create_table
from lpod.style import odf_create_style
if __name__=="__main__":
data = [
["Section\n", "Total nb of Points\n", "Line\n", None, "Polygon\n", None],
[None, "Value", "Total length", "Value", "Total length", "Value"],
[None, 15, 1256.5, 20, 125.3, 50],
]
cellstylenum = odf_create_style('table-cell', name='cellstylenum')
cellstylenum.set_properties(area='paragraph', align='start')
cellcenterred = odf_create_style('table-cell', name='cellcenterred')
cellcenterred.set_properties(area = 'text', color="#FF0000")
cellcenterred.set_properties(area='paragraph', align='center')
celltopred = odf_create_style('table-cell', name='celltopred')
celltopred.set_properties(area = 'text', color="#FF0000")
celltopred.set_properties(area='paragraph', align='center')
col3cm = odf_create_style('table-column', width='3cm')
col4cm = odf_create_style('table-column', width='4cm')
row1cm = odf_create_style('table-row', height='1cm')
document = odf_new_document('spreadsheet')
document.insert_style(col3cm, automatic=True)
document.insert_style(col4cm, automatic=True)
document.insert_style(row1cm, automatic=True)
document.insert_style(cellstylenum, automatic=True)
document.insert_style(cellcenterred, automatic=True)
document.insert_style(celltopred, automatic=True)
body = document.get_body()
table = odf_create_table(u"First Table", width = len(data[0]), height = len(data))
body.append(table)
for r in range(len(data)):
for c in range(len(data[r])):
if data[r][c] is None:
continue
z = table.get_cell((c, r))
z.set_value(data[r][c])
if r == 0 and c >= 2:
z.set_style(celltopred)
elif r == 1 and c >= 2:
z.set_style(cellcenterred)
elif r >= 2:
z.set_style(cellstylenum)
table.set_cell((c, r), z)
table.set_span((2,0,3,0))
table.set_span((4,0,5,0))
for column in table.get_columns():
column.set_style(col4cm if column.x == 1 else col3cm)
table.set_column(column.x, column)
pass
row = table.get_row(0)
row.set_style(row1cm)
table.set_row(row.y, row)
#print("table size:", table.get_size())
table.rstrip(aggressive=True)
print(table.to_csv())
test_output_dir = 'test_output'
if not os.path.exists(test_output_dir):
os.mkdir(test_output_dir)
output = …
Gribouillis1,391 Programming Explorer Team Colleague
I don't use eric4, but it can probably be used to write python 3 code as well. On the other hand, you need to install python 3 to run your program. This post in a linuxmint forum could help you.
Gribouillis1,391 Programming Explorer Team Colleague
You can remove lines 6 to 11 because raw_input() always return a str object. The string's content is not examined, if the user types 123, the string "123" is returned. .isalpha() tests if all the characters in the string are alphabetic, for example "ps2pdf".isalpha() returns False.
Otherwise, variable is not a very good variable name, use something more descriptive like user_input or input_length.
Do you know if your january course uses python 2 or 3 ? If it is python 3, use python 3 right now !
Gribouillis1,391 Programming Explorer Team Colleague
loc = locals()
pf_list = [loc["p%sf" % x] + float(loc["p%s" % x]) for x in "abcdefgh"]
ps_list = ["%.2f" % val for val in pf_list]
or dicts
loc = locals()
pf_dict= dict((x, loc["p%sf" % x] + float(loc["p%s" % x])) for x in "abcdefgh")
ps_dict = dict((k, "%.2f" % v) for (k, v) in pf_dict.items()]
print(ps_dict["a"], ps_dict["b"])
Gribouillis1,391 Programming Explorer Team Colleague
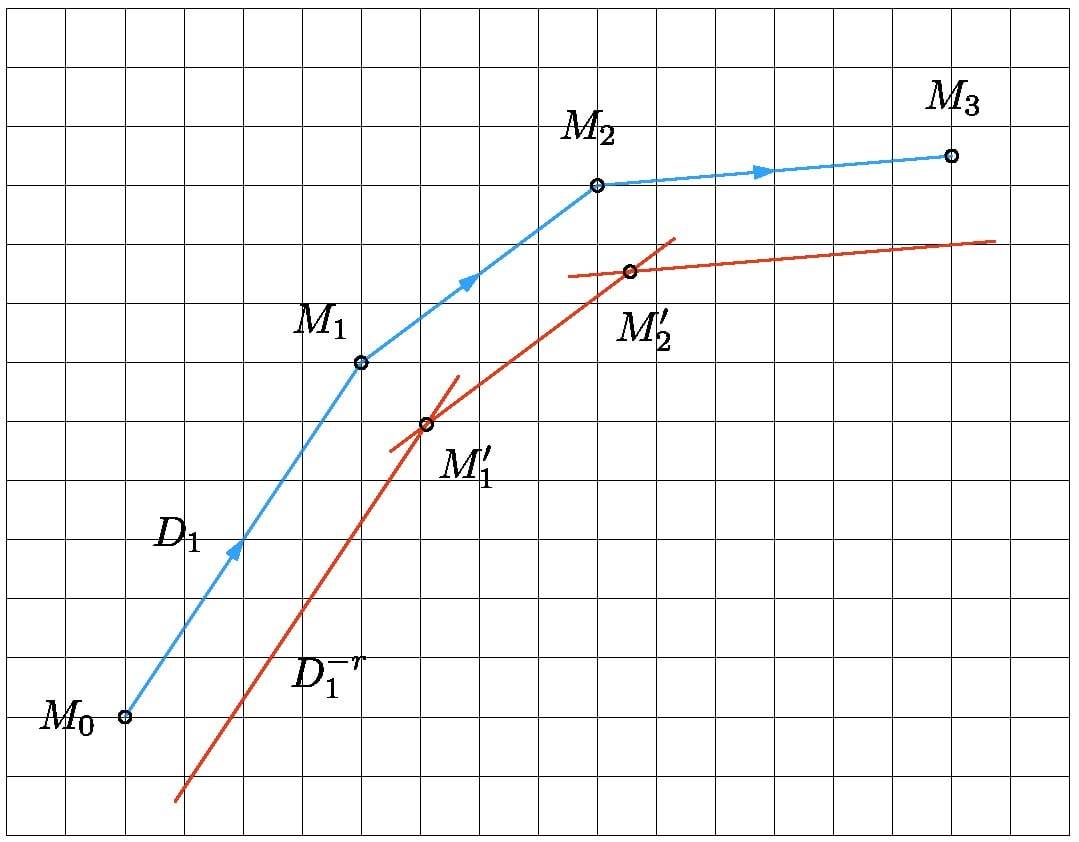
Well, here is a right path computed with the previous function. The first and last points are missing, you can add them using the px0, py0 method
#!/usr/bin/env python
# -*-coding: utf8-*-
from __future__ import unicode_literals, print_function, division
from math import sqrt
data = """
2761066.458,4209083.553
2760885.230,4209203.495
2760702.221,4209317.843
2760506.633,4209436.833
2760316.499,4209562.510
2760122.803,4209691.190
2759937.790,4209831.062
2756662.771,4210809.258
2756436.792,4210791.790
2756209.923,4210754.669
2755984.390,4210688.616
2755775.888,4210602.640
2755571.728,4210508.202
2755359.331,4210408.171
2755148.937,4210293.538
2754594.566,4209838.703
2754493.599,4209652.845
2754385.285,4209454.435
2754286.211,4209273.905
2754294.560,4209039.479
""".strip().split("\n")
M = list(tuple(float(v) for v in line.split(',')) for line in data)
def right_M(r, M0, M1, M2):
x, y = zip(*(M0, M1, M2))
dx, dy = ((t[1]-t[0], t[2]-t[1]) for t in (x, y))
norm = tuple(sqrt(dx[i] ** 2 + dy[i] ** 2) for i in (0, 1))
u, v = ((-dy[i]/norm[i], dx[i]/norm[i]) for i in (0,1))
p = 1 + u[0]*v[0]+u[1]*v[1]
w = ((u[0]+v[0])/p, (u[1]+v[1])/p)
return (x[1] - r * w[0], y[1] - r * w[1])
if __name__ == "__main__":
r = 1 # distance (same unit as the points)
for i in xrange(len(M) - 2):
print(right_M(r, *M[i:i+3]))
""" my output -->
(2760885.7709899466, 4209204.336130894)
(2760702.7458359217, 4209318.69422428)
(2760507.1687698085, 4209437.677572424)
(2760317.0513888276, 4209563.343587389)
(2760123.3817485413, 4209692.006075578)
(2759938.2491084263, 4209831.96852491)
(2756662.8791700928, 4210810.269344599)
(2756436.672511555, 4210792.7837467715)
(2756209.7008925797, 4210755.645955941)
(2755984.0579236434, 4210689.560748778)
(2755775.487301093, 4210603.556452203)
(2755571.305043517, 4210509.108156547)
(2755358.8783515077, 4210409.063172728)
(2755148.3756782985, 4210294.370962217)
(2754593.7805975624, 4209839.352114648)
(2754492.72078066, 4209653.32325918)
(2754384.4078044216, 4209454.915134511)
(2754285.201830749, 4209274.144655606)
"""
All this should be made faster by using numpy.
(image added for r=40)
Gribouillis1,391 Programming Explorer Team Colleague
Here is a function to compute the point M1 prime in the picture above, given the coordinates of M0, M1, M2. Change r into -r to compute the point on the left side
#!/usr/bin/env python
# -*-coding: utf8-*-
from __future__ import unicode_literals, print_function, division
from math import sqrt
def right_M(r, M0, M1, M2):
x, y = zip(*(M0, M1, M2))
dx, dy = ((t[1]-t[0], t[2]-t[1]) for t in (x, y))
norm = tuple(sqrt(dx[i] ** 2 + dy[i] ** 2) for i in (0, 1))
u, v = ((-dy[i]/norm[i], dx[i]/norm[i]) for i in (0,1))
p = 1 + u[0]*v[0]+u[1]*v[1]
w = ((u[0]+v[0])/p, (u[1]+v[1])/p)
return (x[1] - r * w[0], y[1] - r * w[1])
if __name__ == "__main__":
M = [(0, 0), (4, 6), (8, 9), (14, 10.5)]
print(right_M(1.5, *M[0:3]))
print(right_M(1.5, *M[1:4]))
""" my output -->
(5.10555127546399, 4.954163456597992)
(8.657670780786754, 7.618253085590066)
"""
Gribouillis1,391 Programming Explorer Team Colleague
These objects are only created once and stored in the views list, but their repaint_canvas() method is called every time we switch the views. You could change this and always create new objects if you want, but you'd need a good reason to do so. These objects only hold a pointer to the application's canvas, there is no memory leak to worry about.
Gribouillis1,391 Programming Explorer Team Colleague
I read that for large lists, the module zc.blist would be a useful addon to your use of ZODB. It hides a B-tree storage structure behind a list interface. A Pypi search with 'zodb' may reveal other goodies.
Gribouillis1,391 Programming Explorer Team Colleague
Sorry, I misunderstood your question. You can go with pickle if the number of records is small enough and you are ready to load the whole list in memory to access elements.
Otherwise there are many persistence solutions in python. A simple one in your case is the ZODB module, a package which was created for the Zope framework but is independent of Zope. Install it with easy_install. Here is the code for your case
#!/usr/bin/env python
# -*-coding: utf8-*-
from __future__ import unicode_literals, print_function
from collections import namedtuple
from contextlib import contextmanager
from persistent.list import PersistentList
@contextmanager
def zodb(path, create = False):
"""
My own context to open easily a zodb database
"""
from ZODB import FileStorage, DB
import transaction
storage = FileStorage.FileStorage(path, create = create)
db = DB(storage)
conn = db.open()
root = conn.root()
try:
yield root
finally:
transaction.commit()
conn.close()
db.close()
storage.close()
FileInfo = namedtuple("FileInfo", "path foo bar baz")
datafile = "mylist.fs"
CREATE = True
if CREATE:
mylist = PersistentList()
mylist.append(FileInfo("file1", "val0", "val1", "val2"))
mylist.append(FileInfo("file2", "v0", "v1", None))
with zodb(datafile, create=True) as root:
root["mylist"] = mylist
else:
with zodb(datafile) as root:
print(root["mylist"][1].foo)
Run it the first time with CREATE = True, then with CREATE = False.
Another solution could be a sqlite3 database for example. Or an hdf5 file managed with the module h5py (I like this solution).
Gribouillis1,391 Programming Explorer Team Colleague
from collections import namedtuple
FileInfo = namedtuple("FileInfo", "path foo bar baz")
mylist=[]
for file in glob.glob(inputpath+"\\*.txt"):
mylist.append(FileInfo(file, value1, value2, value3))
import pickle
pkl = "fileinfo.pkl"
with open(pkl, "wb") as ofh:
pickle.dump(mylist, ofh)
with open(pkl, "rb") as ifh:
print(pickle.load(ifh))
Gribouillis1,391 Programming Explorer Team Colleague
You can tell where the function was called from using module inspect
#!/usr/bin/env python
# -*-coding: utf8-*-
from __future__ import unicode_literals, print_function
__doc__ = """ sandbox.funccall -
show how to print where a function was called from
"""
import inspect
import os
def calling_line(level):
level = max(int(level), 0)
frame = inspect.currentframe().f_back
try:
for i in xrange(level):
frame = frame.f_back
lineno, filename = frame.f_lineno, frame.f_code.co_filename
finally:
del frame
return lineno, filename
def thefunc(*args):
lineno, filename = calling_line(1)
print("thefunc() was called from {0} at line {1}".format(
os.path.basename(filename), lineno))
return 3.14
def foo():
x = thefunc() ** 2
if __name__ == "__main__":
foo()
""" my output -->
thefunc() was called from funccall.py at line 32
"""
Otherwise, yes, nametest.__name__ = ... resets the original variable. __name__ is an ordinary global variable which is automatically inserted in the module's namespace. Another interesting variable which exists only for imported modules is__file__.
Gribouillis1,391 Programming Explorer Team Colleague
Read the csv module's documentation! Here, you need at least to pass delimiter=';' to csv.reader(). If necessary, play with dialects and formatting parameters until you get the correct result.
Gribouillis1,391 Programming Explorer Team Colleague
There is a way to ask python what are start, stop and step:
>>> s = slice(None, None, -2) # a slice object corresponding to [::-2]
>>> s.indices(8)
(7, -1, -2) # start, stop, step if the slice is applied to a tuple of length 8
Gribouillis1,391 Programming Explorer Team Colleague
Add return p_num at the end of the function. Your function currently returns None. The p_num inside the function is not the same as the p_num outside the function (because it appears in the left part of assignment statements). It is a local variable. You need a return statement to catch its value.
Gribouillis1,391 Programming Explorer Team Colleague
The difference is that in your first version, the same list object testarr is appended to finarr at line 13. In the end, all the lines in finarr are a single list object containing the values appended at the last iteration.
Gribouillis1,391 Programming Explorer Team Colleague
You need a return statement. Also, I deduce from your print statement that you're using python 2 where raw_input should be used instead of input, so it will be
def comein(string):
return raw_input(string)
Gribouillis1,391 Programming Explorer Team Colleague
I don't know what this variable infile is, but it's not rfile nor rfile1. In the same way, why do you read the first file with read() and the last one with readlines() ? The 2 functions return different datatypes. Files are better opened with the with construct:
with open('original.txt', 'rb') as infile:
content = infile.read() # content is now an instance of 'str'
with open('copy.txt', 'wb') as outfile:
outfile.write(content)
with open('copy.txt', 'rb') as infile:
content2 = infile.read()
print "check if copies are the same: ", content == content2
After each with block, the file is properly closed. The 'b' in the opening mode is better in some OSes. It does nothing in other OSes.
Gribouillis1,391 Programming Explorer Team Colleague
if file == 'sample':
m = hashlib.md5()
with open(file, 'rb') as ifh:
while True:
s = ifh.read(1024)
if s:
m.update(s)
else:
break
print '\n', m.hexdigest()+ '\n'
Gribouillis1,391 Programming Explorer Team Colleague
The third item in os.walk is a list of filenames. Otherwise, the md5 of a file refers to the content of the file, not to the filename. Run your code before posting issues!
Gribouillis1,391 Programming Explorer Team Colleague
The default implementation is called C python. It is the main flavor of python, compiled from C. I would recommend C python unless you have specific needs in your apps.
In practice, code written for IronPython will access microsoft .net classes, code written for Jython will access java classes, code for Stackless python will use microthreads, so it all depends on which libraries your python code is using. In the same way, some libraries are available in C python and not in the other pythons.
General python code using standard libraries should run in all versions (however, read the docs).
Gribouillis1,391 Programming Explorer Team Colleague
>>> s = '"Give me bacon and eggs", said the other man' # (Hemingway)
>>> s.find("an")
15 # substring "an" found in position 15
>>> s[15:15+2]
'an'
>>> s.find("an", 15+2)
42 # after position 17, "an" found in position 42
>>> s[42:42+2]
'an'
>>> s.find("an", 42 + 2)
-1 # no occurrences after position 44
Gribouillis1,391 Programming Explorer Team Colleague
Your triangle condition is false as (-1, 4, 2) would be a triangle. A correct condition is simply abs(b-c) < a < b+c. I would check 'triangulity' at object creation and raise ValueError if it fails
#from math import*
class Triangle(object):
"""Checks if given sides can make a Triangle then shows the Angles."""
def __init__(self, a, b, c):
self.a = a
self.b = b
self.c = c
self._check_triangle()
def _check_triangle(self):
"""Checks if given sides can make a Triangle"""
if not(abs(self.b - self.c) < self.a < self.b + self.c):
raise ValueError("Not a triangle")
def get_angles(self):
"""Calculates the Angles based on the Cosine Rule."""
A = degrees(acos((self.b**2+self.c**2-self.a**2)/float(2*self.b*self.c)))
B = degrees(acos((self.a**2+self.c**2-self.b**2)/float(2*self.a*self.c)))
C = 180 - (self.A+self.B)
return A, B, C
Also with a method name like get_angles(), one expects that the method computes and returns a tuple of angles, and not that it prints something. Usable methods don't print anything, they return values.