Language modeling is the cornerstone of advanced natural language processing, forming the backbone for cutting-edge technologies like ChatGPT. At its core, it involves predicting words based on context, a fundamental principle underlying modern large language Models (LLMs). There are various techniques for language modeling, with attention mechanisms emerging as the latest innovation. To comprehend attention, understanding Recurrent Neural Networks (RNNs) is crucial.
In this article, you will implement a language model in Keras using a Long Short-Term Memory (LSTM) network, a specialized type of recurrent neural network. We will focus on training our model with text data from Wikipedia. After training, the model will be able to predict the next word accurately based on input text.
So let's begin without ado.
Importing Wikipedia Data
We will use the content from Wikipedia's page on "Artificial Intelligence" to train our next word predictor model.
You can import the Wikipedia data using the Python Wikipedia library. You can download the library using the following script:
! pip install wikipediaLet's search some Wikipedia pages using a keyword. You can use the wikipedia.search() function to do so.
import wikipedia
pages = wikipedia.search("Artificial Intelligence")
pages
The search() method returns the following pages based on the keyword' Artificial Intelligence'.
Output:
['Artificial intelligence',
'Generative artificial intelligence',
'Artificial general intelligence',
'A.I. Artificial Intelligence',
'Applications of artificial intelligence',
'Hallucination (artificial intelligence)',
'Ethics of artificial intelligence',
'History of artificial intelligence',
'Swarm intelligence',
'Friendly artificial intelligence']You can limit the number of results using the results parameter. The following script will return the single most relevant result.
pages = wikipedia.search("Artificial Intelligence", results = 1)
pagesOutput:
['Artificial intelligence']The output shows that the Wikipedia page "Artificial Intelligence" is the most relevant to our search query.
You can retrieve a page's contents using the wikipedia.page() method. The method accepts the page title. The following script prints the content of the Wikipedia article on "Artificial Intelligence" using the content attribute. The output below shows cropped content for the page.
ai_page = wikipedia.page(pages[0])
ai_page.contentOutput:
Artificial intelligence (AI) is the intelligence of machines or software, as opposed to the intelligence of humans or animals. It is also the field of study in computer ...We will use the content of the above page to train our LSTM model for the next word prediction.
Preprocessing Text for LSTM
LSTM accepts text in a specific format. We need to preprocess the content of the Wikipedia page to convert the contents of the page to the LSTM desired format.
The first step is to split the page's contents into multiple sentences. You can use any splitting strategy that suits you. I will split the page into multiple sentences using the new line \n character as a splitter.
The below script returns 224 sentences. The script also prints the first sentence. Note that we only keep sentences having at least two words. This is because we will split the sentences into inputs and outputs later and need at least one input word to predict the output word.
import re
# Split the text into sentences using '\n' as the separator
sentences = ai_page.content.split('\n')
# Function to remove special characters from a sentence
def remove_special_characters(sentence):
return re.sub(r'[^\w\s]', '', sentence)
# Filter sentences with at least two words
sentences = [sentence.strip() for sentence in sentences if len(remove_special_characters(sentence).split()) >= 2]
# Printing length of total sentences
print(f"Total number of sentences: {len(sentences)}")
sentences[0]
Output:
Total number of sentences: 224
Artificial intelligence (AI) is the intelligence of machines or software, as opposed to the intelligence of humans or animals. It is also the field of study in computer science that develops and studies intelligent machines. "AI" may also refer to the machines themselves.
LSTM is a neural network that works with numbers. The input sentences in our dataset consist of texts. We need to convert the text inputs to numbers. You can use the Tokenizer class from the keras.preprocessing.text module to do so.
The fit_on_texts() method assigns an integer value to each unique word in your input sentences. The number of unique words will also be our vocabulary size.
You can see the integer value assigned to each word using the word_index attribute of the tokenizer class.
from keras.preprocessing.text import Tokenizer
# Create a tokenizer instance
tokenizer = Tokenizer()
# Fit the tokenizer on the text data
tokenizer.fit_on_texts(sentences)
# Print the word index (word to integer mapping)
tokenizer.word_index
Output:
{'the': 1,
'and': 2,
'of': 3,
'to': 4,
'a': 5,
'in': 6,
'that': 7,
'ai': 8,
'is': 9,
'as': 10,
'for': 11,
'are': 12,
'by': 13,
'or': 14,
'it': 15,
'intelligence': 16,
'be': 17,
'learning': 18,
'artificial': 19,
'can': 20,
'with': 21,
'an': 22,
'machine': 23,
'on': 24,
'not': 25,
.......
The following script prints the vocabulary size for our model.
vocab_size = len(tokenizer.word_index)
print(vocab_size)Output:
2472Next, using the word_index dictionary mappings, we will convert all our input text sequences to integer sequences. The following script does this task and prints a partial integer sequence for the first sentence in our dataset.
Note: We did not show the whole sequence in the output due to space constraints.
# Convert text to integers using the tokenizer
int_sequences = tokenizer.texts_to_sequences(sentences)
int_sequences[0]
Output:
[19,
16,
8,
9,
1,
16,
3,
63,
14,
175,
10,
604,
.....
You can see that the first word in the first sentence is "Artificial", and it has been assigned the integer 19, which you can verify from the word_index dictionary. The second word is "intelligence," which is converted to 16, its integer counterpart from the word_index dictionary, and so on.
The next step is tricky. We will not use the complete sequence as inputs to train our model. Instead, we will split each input sequence into multiple sub-sequences. Let's take an example to illustrate this: consider an example sequence [19, 16, 8, 9]. We will create sub-sequences like [19, 16], [19, 16, 8], and [19, 16, 8, 9].
The idea here is to provide the model with varying contexts for prediction. For instance, the first sub-sequence [19, 16] informs the model that, given the first word, we want to predict the second word. Similarly, the second sub-sequence [19, 16, 8] instructs the model to predict the third word when provided with the first two words as context. This pattern continues for all the integers in the input sequence, allowing the model to grasp the relationships between words at different positions in the sequence.
By structuring the input data in this way, we enable the model to learn the sequential nature of language. It learns to predict the next word based on all the previous words, making our language model more accurate and contextually aware.
The following script divides the data into sub-sequences.
# Initialize an empty list to store the processed sequences.
processed_sequences = []
# Iterate through each input sequence in the list of integer sequences.
for inp_sequence in int_sequences:
# Create a temporary list containing the first two items of the input sequence.
temp_list = inp_sequence[:2]
# Append a copy of the temporary list to the processed sequences list.
processed_sequences.append(temp_list.copy())
# Iterate through the remaining items in the input sequence starting from the third item.
for item in inp_sequence[2:]:
# Add the current item to the temporary list.
temp_list.append(item)
# Append a copy of the updated temporary list to the processed sequences list.
processed_sequences.append(temp_list.copy())
Let's print the first three sub-sequences. If you map the integer values in the following outputs to the words using the word_index dictionary from our tokenizer, you will see that these sub-sequences correspond to the words "Artificial intelligence", "Artificial intelligence ai", "Artificial intelligence ai is".
processed_sequences[0], processed_sequences[1], processed_sequences[2]
Output:
([19, 16], [19, 16, 8], [19, 16, 8, 9])
Finally, we will split our sub-sequences into features and labels. We want to predict the last word in the sequence based on all the previous words. The following script converts data into features and output labels.
# Extract features (X) and labels (Y) using list comprehensions
X = [sequence[:-1] for sequence in processed_sequences] # Features (excluding the last item in each internal list)
y = [sequence[-1] for sequence in processed_sequences] # Labels (only the last item in each internal list)
Let's print the first three original sequences and corresponding features and labels.
print(f"First 3 sequences: {processed_sequences[0], processed_sequences[1], processed_sequences[2]}")
print(f"Features list: {X[0], X[1], X[2]}")
print(f"Labels list: {y[0], y[1], y[2]}")
Output:
First 3 sequences: ([19, 16], [19, 16, 8], [19, 16, 8, 9])
Features list: ([19], [19, 16], [19, 16, 8])
Labels list: (16, 8, 9)
Our input features have varying lengths, but Keras models require input features to be of the same shape. To achieve uniformity, we first determine the length of the largest input sequence. Then, we pad all smaller sequences by adding 0s, making them the same size as the largest sequence.
The following script demonstrates how to find the length of the largest input sequence.
# Find the length of the longest sentence. We will use this for padding
max_length = max(len(internal_list) for internal_list in X)
max_length
Output:
552
And the following script uses the pad_sequences() method from the keras.preprocessing.sequence module to pad the smaller input sequences with 0 at the beginning.
from keras.preprocessing.sequence import pad_sequences
# Apply pre-padding to processed_sequences using pad_sequences function
X = pad_sequences(X, maxlen=max_length, padding='pre')
Finally, we need to convert output labels to one-hot encoded labels. The output will be a probability distribution over all the words in our vocabulary. Therefore, the output columns will equal the number of words in the vocabulary + 1.
We add one to the vocabulary size since the Keras tokenizer assigns word indexes from 1 to N where N is the vocabulary size. On the other hand, the to_categorical() method from the Keras.utils module expects integer values from 0 to N-1. Therefore to accommodate the word with the largest index value, we add 1 to the vocabulary size and pass it to the num_classes attribute of the to_categorical() method.
from keras.utils import to_categorical
y = to_categorical(y, num_classes = vocab_size + 1)
Finally, we can print the shapes of our input features and output labels to see what our training data looks like.
print(f"{X.shape, y.shape}")
Output:
(9136, 552), (9136, 2473))
Training an LSTM Model
We are now ready to define and train our LSTM model.
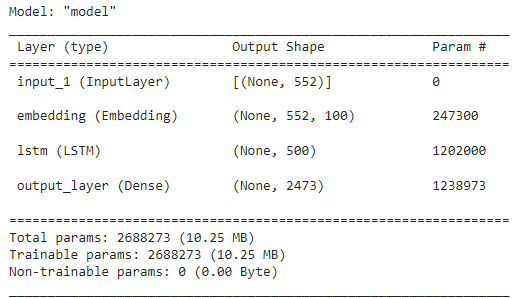
In the code below, we define our Keras model for next-word prediction. We define the input shape, specifying the sequence length as max_length, which is the length of the longest input sequence. Next, we define the input layer, which serves as the entry point for our model.
Subsequently, we add an embedding layer, a crucial component in natural language processing tasks. This layer transforms words into fixed-size vectors, capturing semantic relationships between them. In this example, we set the embedding size to 100, but you can adjust it according to your specific use case.
Next, we incorporate an LSTM (Long Short-Term Memory) layer, a type of recurrent neural network (RNN) capable of capturing long-term dependencies in sequential data. The LSTM layer comprises 500 units. You can modify the number of units you want.
Finally, our output layer employs the softmax activation function, creating a probability distribution over the words in our vocabulary. The model is compiled with the Adam optimizer, categorical cross-entropy loss function, and accuracy metric.
By calling get_model(), we instantiate our model and print its summary.
from keras.models import Model
from keras.layers import Embedding, LSTM, Dense, Input
def get_model():
# Define the input shape (sequence length)
input_shape = (max_length,)
# Input layer
input_layer = Input(shape=input_shape)
# Embedding layer
embedding_size = 100 # Example embedding size, adjust according to your use case
embedding_layer = Embedding(input_dim = vocab_size +1,
output_dim = 100,
input_length =max_length)(input_layer)
# LSTM layer
lstm_1 = LSTM(500)(embedding_layer)
# Output layer with softmax activation
output_layer = Dense(vocab_size + 1,
activation='softmax',
name='output_layer')(lstm_1)
# Create the model
model = Model(inputs=input_layer, outputs=output_layer)
# Compile the model with Adam optimizer, categorical cross-entropy loss, and accuracy metric
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
model = get_model()
# Print the model summary
model.summary()
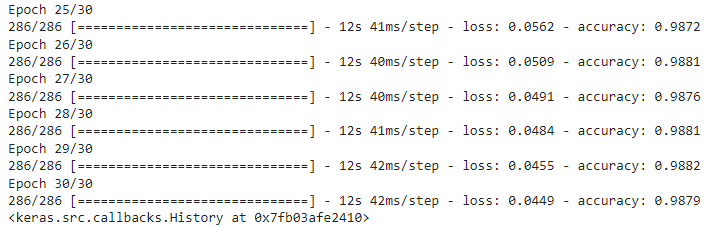
Finally, we train our model using the fit() method. We do not specify any validation data since we have a very small dataset, and our model will most likely overfit. The idea here is to see how to train a language model for next-word prediction. You can try validation data to see what results you get.
# Fit the model using X_train and y_train
model.fit(X, y,
epochs = 30
)
After 30 epochs, I achieved an accuracy of 98.97% on the training set.
Using Model for Text Generation
Let's generate the next words using the language model we trained.
We will define a method named generate_text() that accepts the input text and the number of words to generate as parameter values and return the generated text.
# Import the necessary libraries
import numpy as np
# Define a function 'generate_text' that takes input text and the number of words to generate as parameters
def generate_text(input_text, num_gen):
# Initialize the current input with the given input text
current_input = input_text
# Iterate 'num_gen' times to generate the specified number of words
for i in range(num_gen):
# Convert the current input text into tokenized form using the tokenizer
tokenized_text = tokenizer.texts_to_sequences([current_input])[0]
# Pad the tokenized text to match the required input length for the model
padded_text = pad_sequences([tokenized_text],
maxlen=max_length,
padding='pre')
# Use the model to predict the next word in the sequence
prediction = model.predict(padded_text, verbose=0)
# Get the index of the predicted word with the highest probability
predicted_index = np.argmax(prediction)
# Find the corresponding word for the predicted index using the tokenizer's word index
predicted_word = []
for word, index in tokenizer.word_index.items():
if index == predicted_index:
predicted_word = word
break;
# Add the predicted word to the current input for the next iteration
current_input = current_input + " " + predicted_word
# Return the generated text
return current_input
Using the generate_text() method we just defined, let's generate the next 20 words for the input text "natural".
input = "natural"
words_to_generate = 20
output = generate_text(input, words_to_generate)
output
Output:
natural language processing nlp allows programs to read write and communicate in human languages such as english and economics and others
In the output, you can see that the model generated the next 20 probably words. The output looks pretty coherent.
Conclusion
Language models form the foundation of many state-of-the-art text generators such as Chat-GPT, Bing, Bard, etc. In this tutorial, you saw how to develop a very naive language model that predicts the next most probable word. Using the LSTM model in Keras, you created a next-word predictor language model using text from a Wikipedia page.
However, this is just the tip of the iceberg. You should train your own next word predictor model on a larger dataset and see its performance on the validation data.
In one of my next articles, I will explain how to implement a large language model using attention layers in Keras. Till then, happy coding!
