In one of my research projects, I needed to extract text from video files and create a CSV file that included sentiments expressed in the text. Manual extraction was time-consuming and costly. So, I explored Automatic Speech Recognition (ASR) systems and discovered OpenAI Whisper, known for its high accuracy in converting spoken words to text. Using the Whisper model, I efficiently extracted text from videos and generated a CSV file.
In this article, I'll guide you through the code I developed to seamlessly connect my Python script with the OpenAI API for video text extraction. By the end of this article, you'll be ready to use OpenAI Whisper for your video text extraction projects.
Setting Up OpenAI Whisper Model
To connect your Python script with OpenAI API, you need an OpenAI API key. You will need to sign up with OpenAI to retrieve your Key.
Next, you need to install the OpenAI Python library.
pip install openaiTo connect with OpenAI API in your code, import the openai module and set your OpenAI API key using the api_key attribute of the openai module.
Next, open the audio file you want to transcribe using the open() method and pass the file object to the Audio.transcribe() method of the openai module.
The first argument to the transcribe() method is the whisper model name (whisper-1), and the second argument is the audio file object.
The transcribe() method returns a dictionary in which you can access the transcribed text using the text key. Here is an example:
import openai
openai.api_key = "your-api-key"
audio_file_path = open(r"D:\Dani Web\extract text from videos\videos\video_file_4.mp3", 'rb')
transcript = openai.Audio.transcribe("whisper-1",
audio_file_path)
print(transcript)Output:
{
"text": "Oh, how can anybody do that to their cat? Let it get so fat."
}And that’s how simple it is to transcribe text using the Whisper model. However, it can become a little tricky when you have to transcribe multiple files.
In my case, I had to transcribe over 1000 video files. Therefore, I wrote some utility functions that convert videos to audio and extract text from audio files.
Extracting Audios from Videos
I used the MoviePy Python module to extract audio from videos. You can install the MoviePy module with the following command:
pip install moviepyNext, we define the source directory for the video files and the destination directory where audio files will be stored.
The moviepy.editor module extracts audio from videos, therefore we import this module, along with the os and glob modules for file management.
import os
import glob
import moviepy.editor as mp
#directory containing video files
source_videos_file_path = r"D:\Dani Web\extract text from videos\videos"
#directory for storing audio files
destination_audio_files_path = r"D:\Dani Web\extract text from videos\audios"Subsequently, we will define the convert_video_to_audio() method that accepts as parameter values, the source and destination directories for video and audio files, respectively. The method iterates through all the video files in the source directory, extracts audio from videos, and writes the audio files to the destination directory.
def convert_video_to_audio(source_path, destination_path):
# get paths of all files in source directory
video_files_list = glob.glob(source_path+"\*.mp4")
for i, file_path in enumerate(video_files_list):
# get the base name of the file
file_base_name = os.path.basename(file_path)
i = i + 1
print("Converting file", i, "-", file_base_name)
# convert video file to audio
my_clip = mp.VideoFileClip(file_path)
# writing audio file with the same name in the destination director
# we remove the text ".mp4" from the file name and append ".mp3"
destination_file_path = destination_path + "\\" + file_base_name.split(".")[0]+".mp3"
my_clip.audio.write_audiofile(destination_file_path)In the convert_video_to_audio() function defined above, we first use the glob module to create a list called video_files_list that contains the file paths of all the ".mp4" files in the source directory. This step allows us to loop through each video file for conversion. You will need to change the file extension if your videos are in formats other than “.mp4”.
We then loop through each video file using a for loop and enumerate the list to keep track of the file number.
Inside the loop, we extract the base name of the video file using os.path.basename method. This helps us in naming the resulting audio file.
Using the moviepy.editor module (aliased as mp), we create a VideoFileClip object called my_clip from the current video file.
Next, we specify the destination file path for the audio file. We remove the ".mp4" extension from the video file name using split(".") method and append ".mp3" to the end. This ensures that the audio file has a similar name to the video file but with a ".mp3" extension.
Finally, we use my_clip.audio.write_audiofile() method to convert and save the audio content from the video into the specified destination directory with the appropriate file name.
By calling this function and providing the source and destination paths, you can easily convert a batch of video files into audio files.
Let’s test the convert_video_to_audio() method.
convert_video_to_audio(source_videos_file_path,
destination_audio_files_path)Once you run the above script, you should see audio files in the destination directory. While the above script is run, you will be able to see the file that is currently being converted to audio, as shown in the following screenshot:
The next step is to extract text from these audio files which we can do so via the Whisper model.
Converting Audio to Text Using Whisper
I defined a function named convert_audio_to_text() that accepts as a parameter value, the source directory containing the audio files. The method returns a list of lists where each internal list contains the file name, the text, and the randomly assigned sentiment value for the text.
def convert_audio_to_text(source_path):
# this list will contain our text with annotations
text_annot = []
# get paths of all files in source directory
audio_files_list = glob.glob(source_path+"\*.mp3")
for i, file_path in enumerate(audio_files_list):
# get the base name of the file
file_base_name = os.path.basename(file_path)
i = i + 1
print("Converting file", i, "-", file_base_name)
# opening audio file
audio_file = open(file_path, 'rb')
# transcribing audio using OpenAI
transcript = openai.Audio.transcribe("whisper-1", audio_file)['text']
# you will use your own annotation scheme
# the following is a random annotation scheme
annotation = ""
if i % 2 == 0:
annotation = "Positive"
else:
annotation = "Negative"
# create a list of list containing file name, text transcription, and annotation
val = [file_base_name] + [transcript] + [annotation]
text_annot.append(val)
return text_annotIn the convert_audio_to_text() function defined above, we initialize an empty list named text_annot. This list will contain file names, transcribed texts, and corresponding sentiments.
Using the glob module, we create a list called audio_files_list containing the file paths of all audio files (with the “.mp3” extension) in the specified source directory.
We initiate a for loop to iterate through each audio file in the list. In this process, we also keep track of the file number using the variable i.
Inside the loop, we extract the base name of the current audio file using os.path.basename and print a message to indicate which file is being converted.
We open the audio file in binary mode using open(file_path, 'rb').
The core of this function lies in transcribing the audio content. To achieve this, we use OpenAI's capabilities by invoking openai.Audio.transcribe("whisper-1", audio_file)['text'] method. This step converts the audio into text using the Whisper model.
In the code snippet provided, there is an example of an annotation scheme. Depending on your specific use case, you can create your own annotation scheme. In this example, if the file number is even, the annotation is set to "Positive," otherwise, it's "Negative." This is a very random annotation scheme.
Next, we create a list called val that contains the file name, the transcribed text, and the annotation for the current audio file.
Finally, we append this val list to the text_annot list, effectively creating a list of lists, where each inner list represents a file with its name, transcribed text, and annotation.
The function returns the text_annot list, which now contains the transcribed text from all the audio files along with their corresponding annotations.
By utilizing this function and providing the source directory containing your audio files, you can effortlessly convert audio content into text while maintaining a structured record of annotations.
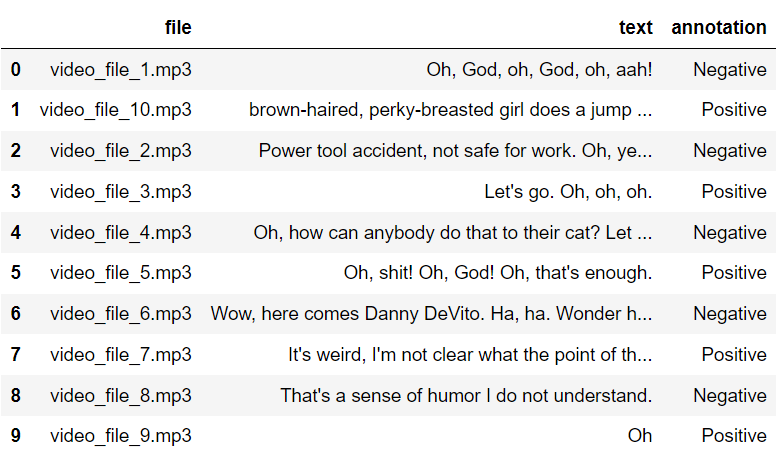
The next step is to convert the text_annot_list to a Pandas dataframe, which you can achieve via the following script:
import pandas as pd
text_annot_df = pd.DataFrame(text_annotations,
columns = ['file', 'text', 'annotation'])
text_annot_df.head(10)Output:
Converting Audio to Text Using Whisper
While testing my script, I stumbled upon the fact that you can also directly transcribe videos using the Whisper model. To achieve that, I modified the following line of the convert_audio_to_text() function. With this, you can retrieve all types of files from a source folder.
audio_files_list = glob.glob(source_path+"\*")You can also modify the above file as follows to only retrieve video files with “.mp4” extensions:
audio_files_list = glob.glob(source_path+"\*.mp4")The following script transcribes all video files from your source directory and creates a Pandas dataframe containing file names, the transcribed text, and corresponding sentiment.
video_files_path = r"D:\Dani Web\extract text from videos\videos"
text_annotations = convert_audio_to_text(video_files_path)
text_annot_df = pd.DataFrame(text_annotations,
columns = ['file', 'text', 'annotation'])
text_annot_df.head(10)Here is the output of the above script:

Conclusion
In conclusion, OpenAI's Whisper model offers a powerful solution for transcribing both audio and video files with remarkable accuracy. Considering the cost, it's worth noting that transcribing 1000 video files, averaging around 6 seconds each, amounts to approximately $1, making it a cost-effective choice for many projects.
I'm eager to hear your insights on how we can enhance the video transcription process for your research. Additionally, if you have any suggestions for more efficient and budget-friendly alternatives, please do share.

