Are you interested in finding out what a YouTube channel mostly discusses? Do you want to analyze YouTube videos of a specific channel? If yes, we are in the same boat.
YouTube video titles are a great way to determine the channel's primary focus. Plotting a word cloud or a bar plot of the most frequently occurring words in YouTube video titles can give you precise insight into the nature of a YouTube channel. I will do exactly this in this tutorial using the Python programming language.
So, let's begin without ado.
Getting YouTube Data API Key
You can get information about a YouTube channel in Python programming via the YouTube Data API. However, to access the API, you must create a new project in Google Cloud Platform. You can do so for free.
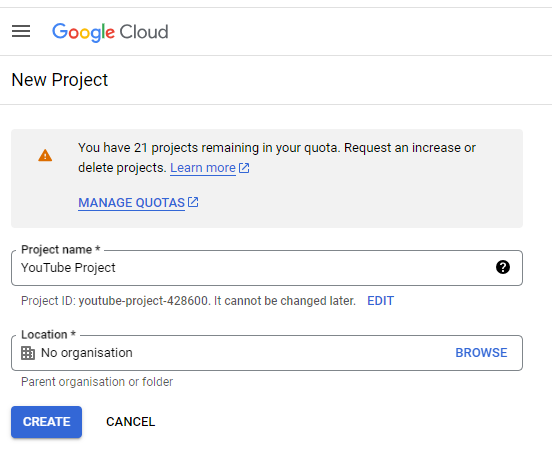
Once you create a new project, click the Go to APIs overview link, as shown in the screenshot below.
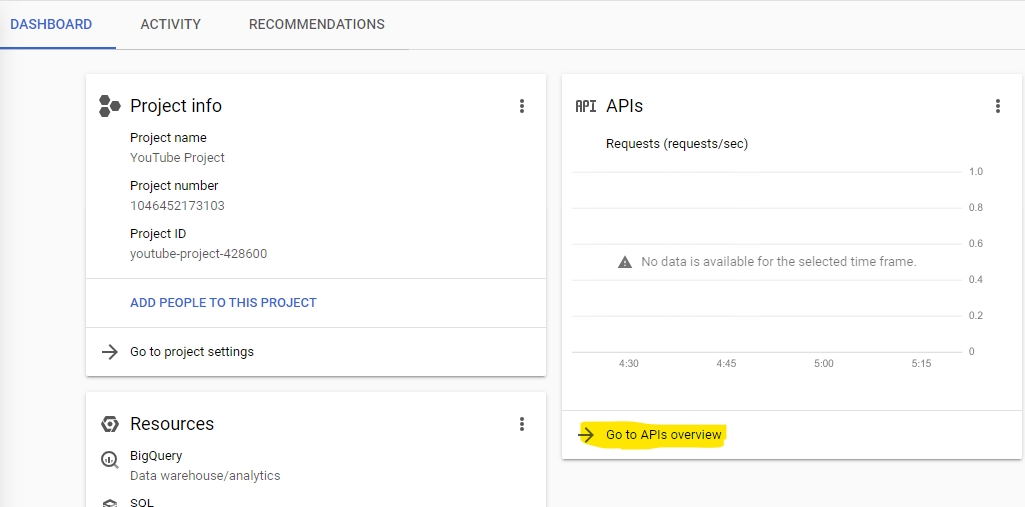
Next, click the ENABLE APIS AND SERVICES link.
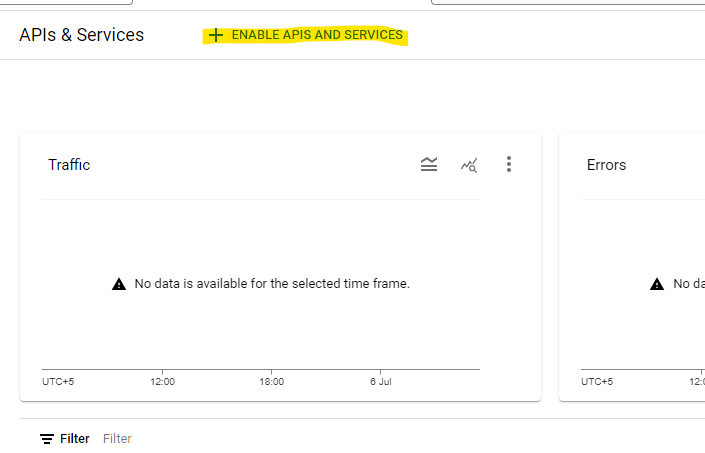
Search for youtube data api v3.
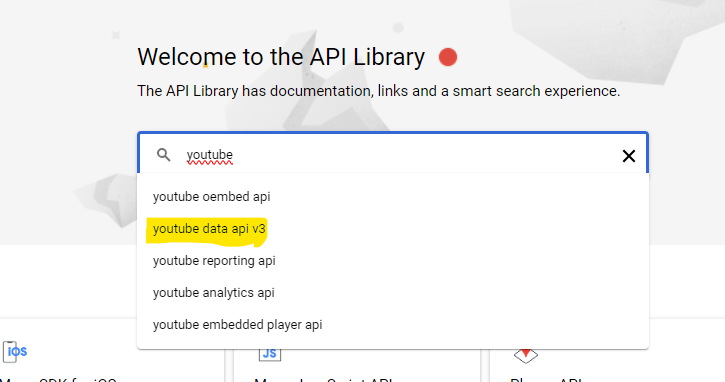
Click the ENABLE button.
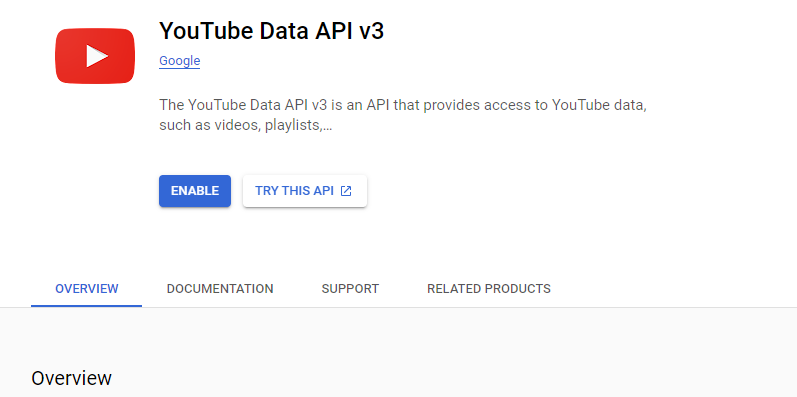
You will need to create credentials. To do so, click the CREDENTIALS link.
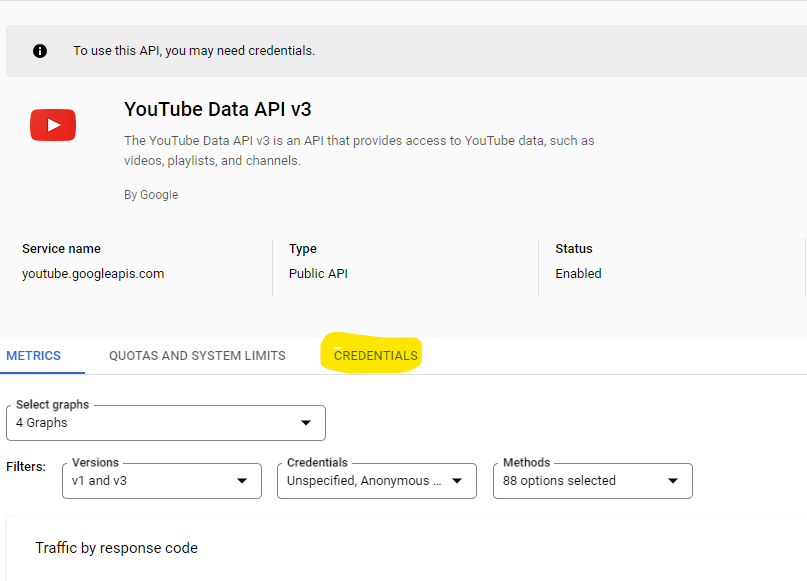
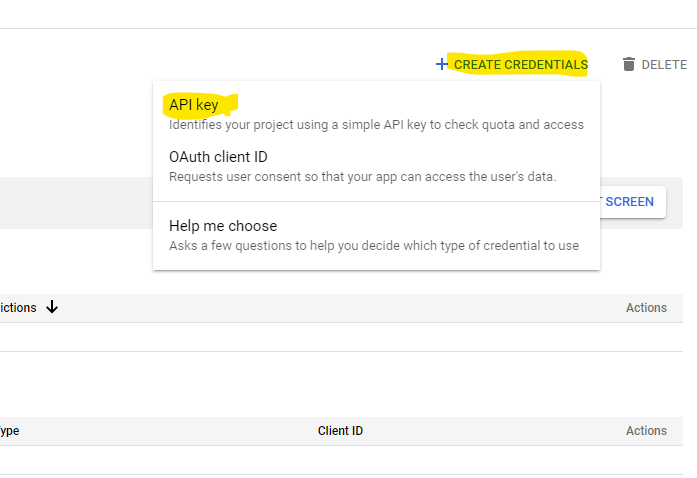
If you have any existing credentials, you will see them. To create new credentials, click the + CREATE CREDENTIALS link and select API key.
Your API key will be generated. Copy and save it in a secure place.
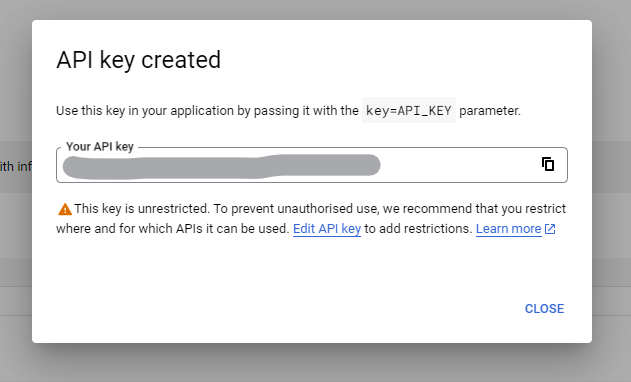
Now, you can access the YouTube Data API in Python.
Installing and Importing Required Libraries
To begin our analysis, we must set up our Python environment by installing and importing the necessary libraries. The main libraries we will use are google-api-python-client for accessing the YouTube Data API, wordcloud for generating word clouds, and nltk (Natural Language Toolkit) for text processing.
!pip install google-api-python-client
!pip install wordcloud
!pip install nltk
Next, import the required libraries. These include googleapiclient.discovery for accessing the YouTube API, re for regular expressions to clean text, Counter from the collections module to count word frequencies, matplotlib.pyplot for plotting, WordCloud from the wordcloud library, and stopwords from nltk.corpus for removing common English words that do not contribute much to the analysis.
import googleapiclient.discovery
import re
from collections import Counter
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import nltk
from nltk.corpus import stopwords
Extracting YouTube Channel Statistics
This section will extract video titles from a specific YouTube channel using the YouTube Data API. To do this, we need to set up our API client with the appropriate API key and configure the request to fetch video data.
First, specify the API details and initialize the YouTube API client using the API key you generated earlier. Replace "YOUR_API_KEY" with your actual API key.
# API information
api_service_name = "youtube"
api_version = "v3"
# API key
DEVELOPER_KEY = "YOUR_API_KEY"
# API client
youtube = googleapiclient.discovery.build(
api_service_name,
api_version,
developerKey=DEVELOPER_KEY)
Next, define the channel ID of the YouTube channel you want to analyze. Here, we are using the channel ID UCYNS-_653RIE9x_BINefAMA as an example. You can use any other channel if you want.
We will then create a request to retrieve video titles for the specified channel. The request fetches up to 50 video titles per call. We use pagination to fetch additional results if available to handle more videos.
# Channel ID of the channel you want to search
channel_id = "UCYNS-_653RIE9x_BINefAMA"
# Request to retrieve all video titles for the specified channel
request = youtube.search().list(
part="snippet",
channelId=channel_id,
maxResults=50,
type="video"
)
# Initialize an empty list to store the video titles
video_titles = []
# Execute the request and retrieve the results
while request is not None:
response = request.execute()
for item in response["items"]:
video_titles.append(item["snippet"]["title"])
request = youtube.search().list_next(request, response)
Finally, print the total number of extracted video titles and display the first 10 titles to ensure our extraction process is working correctly.
# Print the video titles
print("Total extracted videos:", len(video_titles))
print("First 10 videos")
print("===============")
for title in video_titles[:10]:
print(title)
Output:

Plotting a Bar Plot with Most Frequently Occurring Words
This section will process the extracted video titles to identify the most frequently occurring words. We will then visualize these words using a bar plot.
First, download the NLTK stop words and define an additional set of stop words to exclude from our analysis. Stop words are common words like "the", "is", and "in" that does not provide significant meaning in our context.
nltk.download('stopwords')
stop_words = set(stopwords.words('english')) | {'sth', 'syed', 'talat', 'hussain'}
Next, filter the video titles to include only those containing Latin characters. This step ensures we focus on titles written in English or similar languages.
# Filter videos with Latin text only
latin_titles = [title for title in video_titles if re.search(r'[a-zA-Z]', title)]
We then clean the titles by removing special characters and tokenizing them into individual words. Stop words are excluded from the analysis.
# Remove special characters and tokenize
words = []
for title in latin_titles:
cleaned_title = re.sub(r'[^\w\s]', '', title) # Remove special characters
for word in re.findall(r'\b\w+\b', cleaned_title):
if word.lower() not in stop_words:
words.append(word.lower())
Subsequently, we count the frequency of each word and identify the ten most common words. To avoid redundancy, exclude additional common words specific to the dataset, such as "sth", "syed", "talat", and "hussain".
# Count the frequency of words
word_counts = Counter(words)
# Get the 10 most common words
most_common_words = [word for word, count in word_counts.most_common(10) if word not in {'sth', 'syed', 'talat', 'hussain'}]
Finally, create a bar plot to visualize the frequency of the most common words.
# Create bar plot
plt.figure(figsize=(10, 5))
plt.bar(range(len(most_common_words)), [word_counts[word] for word in most_common_words])
plt.title('10 Most Common Words in Video Titles')
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.xticks(range(len(most_common_words)), most_common_words, rotation=45)
plt.show()
Output:
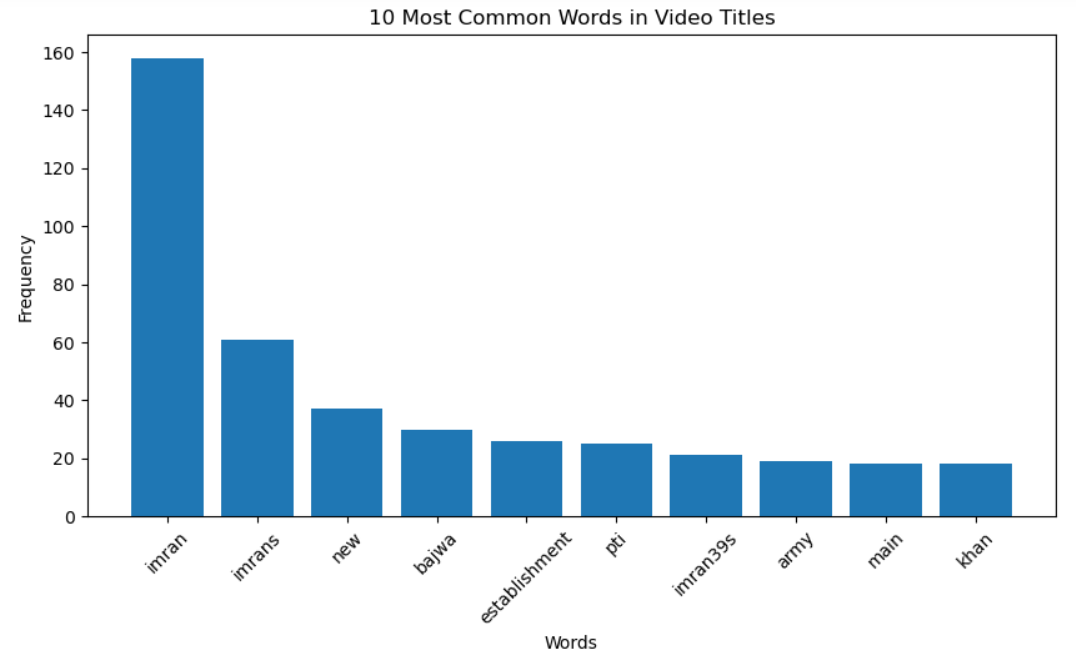
The output will display a bar plot showing the 10 most common words in the video titles, providing a clear insight into the primary topics discussed on the channel.
Word Cloud of Video Titles
We will create a word cloud to visualize the word frequency data further. A word cloud presents the most common words in a visually appealing way, and the size of each word represents its frequency.
First, generate the word cloud using the WordCloud class. The word cloud is generated from the list of words we compiled earlier. Next, we display the word cloud using Matplotlib.
# Generate word cloud
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(' '.join(words))
# Display the word cloud
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.title("Word Cloud of Video Titles")
plt.show()
Output:
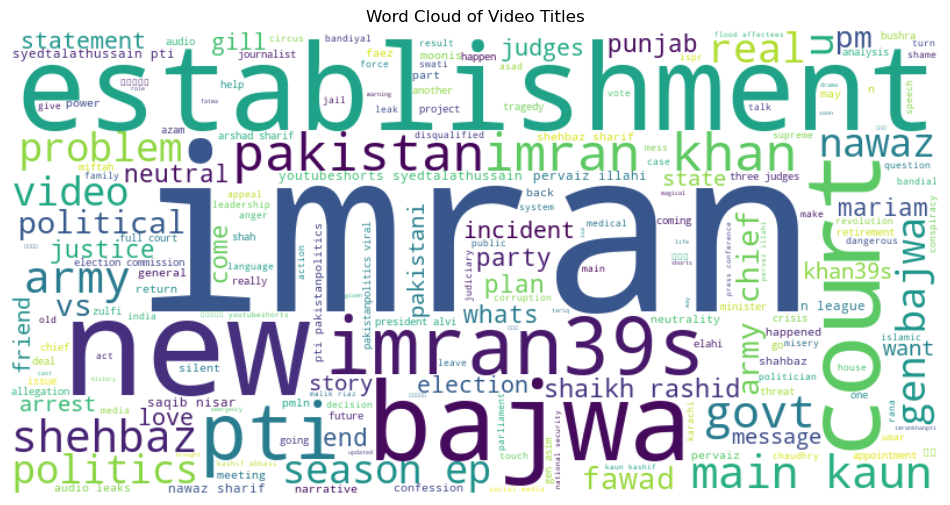
The resulting word cloud provides a visual representation of the most frequently occurring words in the video titles, allowing for quick and intuitive insights into the channel's content.
Conclusion
Analyzing YouTube video titles allows us to gain valuable insights into a channel's primary topics. Using Youtube Data API and libraries such as google-api-python-client, nltk, matplotlib, and wordcloud enables us to extract video data, process text, and visualize the most common words. This approach reveals the core themes of a YouTube channel, offering a clear understanding of its focus and audience interests. Whether for content creators or viewers, these techniques effectively uncover the essence of YouTube video discussions.