Hi, there,
I am also very new to Java.
For class, I have to create an structure that reflects that of a document stored in a plain txt file.
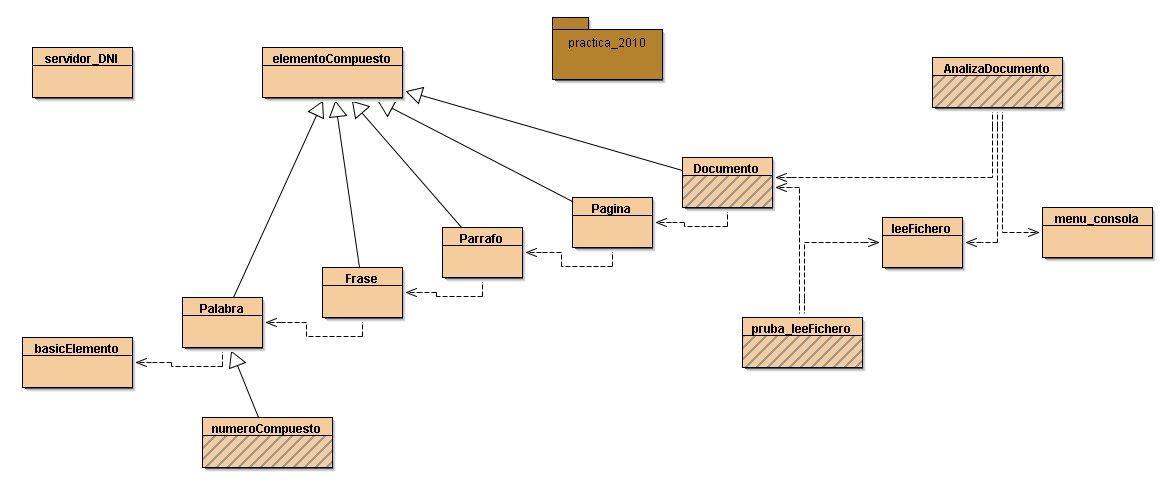
The hyerarchy of the classes is:
Class document is made of
//complex objects
class Page objects, that are made of
class PArragraph, that are made of
class Phrase objects, that are made of
class Word objects, and/or class Number objects, both made of
// elemental tyoe objects
class basicElement objects, characters read from the file.
EOdocument To tell a documents end I need a eof character (EOF)
EOpage To tell a page end, I need two consecutive carriage return OR the above
EOparragraph To tell a parragraphs end, I need one carriage return OR any of the above,
EOphrase To tell a phrase end, I need a dot OR any of the above
EOword To tell a word's end, I need a space, a comma, semicolon, colon OR any of the above
if a word is a number or a word is reflected in a field of the word class.
I have thought of reading charachter by charachter the file and begin building the structure. My approach was that I first create a Document object, whose class constructor creates an arraylist of Pages until a EOF is encountered.
The Pages constructor creates an arraylist of Parragraphs until a EOpage is encountered. The Parragraphs constructor creates an arraylist of phrases until a EOparragraph is encountered.
The Phrases constructor creates an arraylist of words & numbers until a EOphrase is encountered.
The word constructor creates an arraylist of basicElements until a EOword is encountered.
I have, though, several questions that are setting me stuck.
For now, I have coded a Textfile reader using a Scanner and, playing with regular expressions, have came to be able to extract tokens of any kind of the above. But, I only get a series of strings yielded by the delimiters, not actual objects of my classes. I would like to let every object fill himself's arraylist at the time of construction, but I find the problem of: how would each new basicElement know what has been the last read position of the text file? Should I pass a parameter through all the chain of construction back and forth? Could I create a static string that any new basicElement can ask for the Next element? Does it make any sense?
Is this efficient or would it be better to start from a big string containing all the document, create then several strings each with the text of each page, then create new strings for each parragraph and so on? I find it very complex because I would have to create hundreds or pearhaps thousands of strings that would be tokenized or scanned in a exponential growing complexity. Seems scarry
any advise?
I have some code and a scheme of my analysis, but the only thing I have came with is to be able to tokenize with regex.
In my search I have found something called an iterator, this could help me with the static string approach as I would have an independent and all-visible objects that knows the last characters read...
looking forward to hearing from you
ankilosado