Hello,
the WHY is given there
Carefully read my two postings. If you have still problems with aggregate functions and "missing" group-by clause, simply ask again.
-- tesu

Hello,
greetings from the closest hood !
Which mips assembly?
The idea you sketched out is very good! It only functions this way.
# Assuming that the 64 bits int are always in two 32 bit regs ($11, $10) and ($21, $20),
# where $11 and $21 contain the high order parts, the addition can be made by
# 1) unsigned add both low order parts $10 + $20, result in $5
addu $5, $10, $20
# Then you need an add with carry instruction,
# unfortunately mips assemblies lack of such nice instruction.
# 2) So you must make use of sltu instruction, set carry in $4:
sltu $4, $5, $20 # fast way to determine carry of $5 = $10 + $20
# 3) Now add with carry can be carried out:
addu $4, $4, $11 # carry + first high order part $11
addu $6, $4, $21 # intermediate result + second high order part $21, result in $6
# 4) Finally, did we even do a 65 bit addition?
sltu $4, $6, $21 # carry of last addu set in $4.
### Final result is:
### ($4, $6, $5), where $4 is last carry, $6 high order and $5 low order part of 64 bit result.
# Attention: Above assembly not tested! If you find any error, pls tell me.Well, that's all what I could remember of vintage mips r3000, hopefully, that some more advanced R.I.P. mips machines also function similar to this void-of-add-with-carry era, or they had even got that missing instruction, what you should really check for your current mips machine.
Happy mipsing!
-- tesu
so, so, doing excercises at LMU
Well, if you want to do suchlike string separation in query statement, you can make use of ora's string functions, such as:
select 'tag: key1, key2, key3' as st, length(st) as le, instr(st, ':') as lo, substr(st, 1, lo-1) as tag, substr(st, lo+1, le-lo) as whateverfor;
/*
st le lo tag whateverfor
---------------------------------------------------
tag: key1, key2, key3 21 4 tag key1, key2, key3
*/-- tesu
Hi Madawar,
first i have to correct the following line:
>> MOV AX, 0FFFFFFFEH ;;; correct, AX is filled with FFFFFFFEH
is wrong because length of AX is 16bits. Therefore correct is:
MOV AX, 0FFFEH ;;; correct, AX is filled with FFFEH1k is short for one's complement (in Bavaria;))
2k is two's complement
msb = h.o. bit, lsb = l.o. bit
As for sign extension: we have negative whole number FEH = 1111 1110H. If we want to extend it for some reason, extension must be done with sign bit, for example 11 1111 1110B. How to translate it back into hex? each hex figure consist of 4 bits, therefore further extension must be made: 11 11 1111 1110B = FFEH. For 80x86 all register are divisible by 4 so sign extension usually happens in portion of 4 bits that makes just a hex figure, FEH, FFFEH, FFFFFFFEH (for al, ax, eax).
Btw, for 80x86 there exists a special move instruction MOVSX for move with sign extension.
Dante's very good explanation didn't cover negative whole numbers too, so you can't hardly say there would be a contradiction.
-- tesu
Now I see you are a assembly programmer. Here the leading 0 has a special meaning.
Consider this two instructions:
MOV AL, FEH
MOV AL, 0FEHIn first instruction the value of the variable FEH (it is an offset) is moved into reg. AL. Therefore such variable must exists in data segment, for example by definition: FEH DB 1
In second instruction the 8-bit constant FEH is moved into 8bit reg. AL.
Also consider these:
;; negative FEH should be loaded:
MOV AX, 0FEH ;;; wrong, bcause AX is filled with: 000000FEH
MOV AX, 0FFFFFFFEH ;;; correct, AX is filled with FFFFFFFEH-- tesu
Hi,
Am a self teaching Newbie Assembly programmer :) Still in the theoretical Stages.
My question is....
According to the book am reading
When you convert 254(decimal) to hexadecimal you get 0FEh.
And when you convert -2(decimal) to hexadecimal using two's complement you get OFEh.
When i do it manually i get FEh.
Is the zero before FEh always necessary or is it just another way of representing your code..?
Am fully aware that 0 in hexaecimal stands for 0000(base 2)Thanks in advance......
Well, the 0 of 0FEH is wrong if it should represent -2D. The most significant bit (msb) of an integer numbers always indicates whether the number is positive or negative. msb = 0 is for positive numbers, msb=1 stands for negative numbers, where negative whole numbers usually are in two's complement.
Let's code -2D in binary 2k and then in hex 16k:
2D = 10 --> extend it by some 0 to indicate true positive number: 0000 0010
now 1K: 1111 1101, 2k = 1k + 1 = 1111 1101 + 1 = 1111 1110B
-2D = 1111 1110B = FEH
If you add a 0, you get 0FEH, binary: 00001111 1110B what is a positive number, therefore wrong! If you want to extend a negative whole number, you must extend with the sign bit, that is for example FEH = FFFEH = FFFFFFFEH.
-- tesu
Hi,
Yes, I know, MySQL indeed did this insane expansion of the mathematically well defined select-order-by clause. Now everybody will be able to use MySQL for comparing apples to oranges without cease. Now you should, no, you must carefully examine every row result whether it contains idiotic combinations of invalid column values or not.
Let me allow to cite from chapter 11.16.3 of MySQL reference manual:
"MySQL extends the use of GROUP BY so that you can use nonaggregated columns or calculations in the select list that do not appear in the GROUP BY clause."
And further on this warning:
"When using this feature, all rows in each group should have the same values for the columns that are ommitted from the GROUP BY part. The server is free to return any value from the group, so the results are indeterminate unless all values are the same."
Do you got it? Indeed, MySQL pulled off a feat to turn the complete relational algebra and set theorie topsy-turvy.
NEVER EVER use this foolish MySQL feature!
-- tesu
As pritaeas already explained trigger cannot consist of PHP code. There are only SQL and PSM (Persistent Storage Modul, yes, that's a standardized procedural programming language, not only like Oracle's pl/sql but partly derived from it) allowed within a trigger. You may consult SQL standard 2003.
Java, C, C++ or even PHP are not allowed until today. In the not-that-far future there could be triggers written in Java because Java has been designated to be the new procedural programming language for SQL. This important arrangement was made in the SQL standardization of 2003.
However, one can create a trigger fom within PHP5 using multi_query(string) as for instance:
/* Trigger example for MS SQL Server, Oracle, Sybase
Below trigger sample is based on standard 2003 PSM. Proprietary database systems, for instance MySQL, may have their own token and syntax or may plain omit some standarized PSM features.
*/
$sql="CREATE TRIGGER myTrigger AFTER INSERT, UPDATE, DELETE ON myTable
REFERENCING OLD AS oRow NEW AS nRow
FOR EACH ROW
BEGIN
IF INSERTING THEN
BEGIN
-- Do something dealing with inserted data
END
ELSEIF UPDATING THEN
BEGIN
-- Do something dealing with updated data
END
ELSEIF DELETING THEN
BEGIN
-- Do something dealing with deleted data
END
END IF;
END;"
$mysqli->multi_query($sql)-- tesu
Hi Werner,
not an easy question yet a solution can be given by WITH-clause.
/* Assuming table xyz contains these rows:
x y z
-----------------
e w 9
e w 12
e wo 8
e wo 10
e wo 11
e wo 18
i w 4
i w 6
i w 7
i w 15
i w 19
i wo 5
i wo 13
i wo 14
o w 2
o w 20
o wo 1
o wo 3
o wo 16
o wo 17
then query: */
WITH --<--- he he, this should also be purple-coloured !
eio_w (eio, w, z) as
(select x, count(y), sum(z) from xyz where y = 'w' group by x),
eio_wo (eio, wo, z) as
(select x, count(y), sum(z) from xyz where y = 'wo' group by x)
select eio_w.eio as 'eio', w, wo, eio_w.z+ eio_wo.z as 'sum(z)'
from eio_w join eio_wo on eio_w.eio = eio_wo.eio order by eio;
/* gives this result:
eio w wo sum(z)
-----------------------------
e 2 4 68
i 5 3 83
o 2 4 59
on databases Oracle, MS Sql server, and Sybase Sql Anywhere. As for sum(z) this should demonstrate that further columns can be processed (can become difficult).*/New WITH-clause (standard since sql 2003) also exists in MySQL >5. So you should be able to apply above query on MySQL too. I am sure, besides WITH-clause there exist further solutions, for example such ones based on self-joins.
-- tesu
No thanks:)
Finally you need the instruction to transfer one byte from memory location [710H:0B245H] into a 8 bit register:
MOV AL, DS:[0B245H]Usually prefix ds: is not necessary but depending on the assembly you are using, for example weak MS MASM, this prefix is still necessary for syntax reasons.
-- tesu
Hi
Thank you for this further information. Now it s easy to compute the offset. In 8086 real mode logical offset and segment addresses are both 16bits long. Physical address is 20Bits long (there are 20 Address lines). Segment address is binary left shifted by 4 places, that is multiply segement address by 10H. Then the offset is added to get the physical address. Therefore,
Phys. Adr = Seg.Adr * 10H + Offset
12345H = 0710H * 10H + Offset
12345H - 07100H = Offset
Offset = 0B245H
I hope this answer will help you for tomorrow's test
-- tesu
Well,
to state a serious answer more information is needed: Processor, assembly, mermory organisation (aka memory model), and for we can access memory portions of 1 byte, 1 word, 1 dword (32Bit) you should also know what really should be accessed from abs. address 12345H. We also need to know whether you are dealing with Little or Big Endian. You want to get a variant structure? In assembly it's also possible depending on the (macro) assembler you are working with.
Unfortunately, without this pieces of information one cannot answer seriously. (Possibly, your teacher also didn't think of all those stuff too)
-- tesu
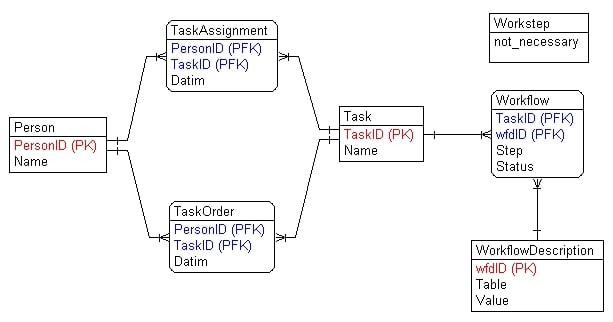
Hi durexlw,
attached is an ERM which I just finshed while watching ESP vs. POR. It is mainly focused on the problem of your tblWorkflows. I think the solution consisting of Task, Workflow and WorkflowDescription is able to manage as many as possible pairs (paramjjTable, paramjjValue), and most important there is no further need to change sql statements nor to changing a table's schema if additional pairs (table, value) come out.
Here is a query which works on that ERM (however not tested): List all Persons with assigned tasks and their associated workflows not as yet finished:
select p.name as Person, Datim as "Date", t.name as Task, Step, Table, Value
from Persno p join TaskAssignment join Task t join Workflow join WorkflowDescription
where Status = 0 order by taskID, wfdID, step;I left open the ON-clauses for they are not necessary if all primary and foreign keys are properly defined (sure, it depends on the notion of the database designer whether ON is needed. But one should taken into account that every time one needs to quote an ON this could be a signal pointing to a lack of referential integrity in his data model. On the other hand naturally developed data models usually lacks of consistent names for primary and foreign keys, therefore ON-clauses are quite usual).
btw, I am also no that certain, that your lastly posted query would always work perfectly.
-- tesu
Hi
>> I want to avoid multiple entry of a stock for the same timestamp in the database.
Then put a timestamp attribute in the primary key, for example ts:
CREATE TABLE yourtable (
ts TIMESTAMP NOT NULL,
a VARCHAR(20),
PRIMARY KEY(ts)) ENGINE = InnoDB;Resolution of ts is approximately some milliseconds. Do not forget to choose the right ENGINE and if possible, try to avoid ID INT NOT NULL AUTO_INCREMENT.
-- tesu
Hi
your select statement is formally quite correct, except for ID which is a well known system identifier of MS SQL server itself.
Because your select statement seems to be only constructed for asking your question it would really be a good idea to post the ORIGINAL erroneous statement AND the ORIGNAL error message too.
-- tesu
Hi wayn3san
I have neither MSN nor ICQ. You can easily post your questions here.
Here on daniweb you are really sure that your problems be read and may also be solved by other more adept experts.
-- tesu
Hi
I have had a little time this morning so I did some tests with your c program. I run it using long double (12bytes with gnuc++) but the results were nearly the same as for double what is 8 byts long. Also I played about with some various step widths and got same bad results too.
Provided that the math, especially the kinetics, of your c program is exactly the same as for Mathematica, what you have most certainly verified, I almost feel certain that the procedural error of RK4 could be the reason for these bad results. Do you know which algorithm is implemented in Mathematica for solving ODE systems? (I myself are using matlab).
What do you think of Runge Kutta Fehlberg RK45 or RK4 with adaptive step size? Maybe adaptive step size leads to better results in time range 71.2 to 71.5 where the Yi feature strong alternations?
I wish you the best of luck
-- tesu
I want to write an assembly program to convert Hexadecimal to Binary in 8086 assembly language. I am using Winasm as my compiler.
However i have no idea how to write this code.
Can anyone shed some light?thanks in advance!
Hello,
how is your hex value coded and stored, char, reg/data segment?
If you want to output the binary (0/1) of a register's content, for example reg bl, you only need to get its bits by left-rotating bl through the carry flag (rcl). But if you really want to convert a hexadecimal number into its binary representation you have to code the hex number like a char priorly.
This macro converts aByte into its binary, converts it to asccii 30h/31h and output the eight figures 0/1 on screen by using dos function 02h (sorry, not tested till now):
bioBin macro aByte ; binary (0/1) output of aByte to screen
local lup ; local symbol
push ax ; save our regs (flag reg should also be saved)
push cx ;
push dx ;
mov bl, aByte ; move aByte into bl reg
mov cx, 8 ; Loop counter, a byte has 8 bits
mov ah, 2h ; DOS function to output one char from dl
; the gist of the matter is the four-line lup
lup: rcl bl, 1 ; left-rotating bl through carry CF
mov dl, 30h ; make an ASCII out of it, ascii = number + '0'
adc dl, 0 ; Add …Sorry I have to apologize to you. At a first glance I thought your steps in y directions were wrong. But I was wrong. Your RK formulas are completely correct, as far as I can verify this, because of your system you need precomputing of the Ks and store them in t1..t3. Therfore the arrays are necessary. Can you post the results of Mathematica for time 70.3 and 75, like the result (t,y[0],y[1],y[2],y[3]) of printf?
Did you also consider that the results could be probably instable because 4th order RK (O(h^4)) might be insufficient?
-- tesu
we were asked to make a program that adds two digit numbers. I was ableto scan and add the input numbers but I have trouble doing the 'carry' part. i can't divide the sum of the ones place integers by ten.
what's wrong with this code? :
mov al,bl;move bl to al to make it the dividend, the sum is stored in bl sub al,30h;subtract 30h to make it number mov bl,10;move 10 to bl. div bl;divide to get the remainder/thanls in advance
Hi, you need to make use of AX and BX for your DIV needs 16 bit regs.
mov ax, 100
mov bx, 10
div bx
; result in ax:dx, quotient in ax, remainder in dx; You may also look at my assembly code, lines 20-22 . There i make division too.
-- tesu
Hi,
I think your RK steps are not correct, you may check this.
Also a RK function of my own shows other steps for y direction:
tSCALAR ruku5( tODEF f, tSCALAR x, tSCALAR y, tSCALAR h)
// Common 4th order Runge–Kutta method
{ tSCALAR k1, k2, k3, k4;
k1 = h * f ( x, y );
k2 = h * f ( x + h / 2, y + k1 / 2 );
k3 = h * f ( x + h / 2, y + k2 / 2 );
k4 = h * f ( x + h , y + k3 );
return (y + ( k1 + 2 * ( k2 + k3 ) + k4 ) / 6);
}So I think some of your loops should be changed to as commented:
for (i=0;i<N;i++) t1[i]=y[i]+0.5*(k1[i]=H*fp(x, y, i));
for (i=0;i<N;i++) t2[i]=y[i]+0.5*(k2[i]=H*fp(x+h, t1, i)); // <-- H*fp(x+h,k1[i]/2, i)
for (i=0;i<N;i++) t3[i]=y[i]+ (k3[i]=H*fp(x+h, t2, i)); // <-- H*fp(x+h, k2[i]/2,i)
for (i=0;i<N;i++) k4[i]= H*fp(x+H, t3, i); // <-- H*fp(x+H, k3[i], i)
for (i=0;i<N;i++) y[i]+=(k1[i]+2*k2[i]+2*k3[i]+k4[i])/6.0;Obviously the arrays t1, t2, t3 aren't necessary for computing y in last for-loop. Therefore scalar k1, k2, k3, k4, and array y can be computed within one loop.
-- tesu
Greetings from the hood
First, to your question how to join 5 tables:
-- To get all steps of a person which are assigned via TaskOrders:
select lastname from Persons p join taskorders o ON p.ID = o.personaidFK
join tasks t ON t.ID = o.taskidFK join workflow w ON w.taskidFK = t.ID
join steps s ON s.ID = w.stepidFK
where p.ID = your_current_personal_ID;
-- This pretty construct could be reduced to:
select lastname from Persons p join taskorders join tasks join workflow
join steps where p.ID = your_current_personal_ID;
-- if all primary and foreign keys constraints were properly set up.If you want to know which steps of a workflow are undone you must add a further attribute, say status, to table workflow (status = 0--> undone, status = 1--> finished).
-- Then your select would look like
select lastname from Persons p join taskorders o ON p.ID = o.personaidFK
join tasks t ON t.ID = o.taskidFK join workflow w ON w.taskidFK = t.ID
join steps s ON s.ID = w.stepidFK
where p.ID = your_current_personal_ID AND w.status = 0;
-- or simpler
select lastname from Persons p join taskorders join tasks join workflow w
join steps where p.ID = your_current_personal_ID AND w.status = 0;Second, obviously there are some discrepancies in your data model which can possibly be unveiled by those questions:
1. Can a certain task be assigned to various persons? (Yes), dito orders.
2. Can a certain task be assigned to various steps? …
Hi iqra123
You may have a look into gnu C library. It contains fully DES Encryption, also MD5.
If you are only interested in putting some cipher on your data, there is a nice method by using pseudo random numbers:
sender side:
for all chars of message to send do
..compute random number with given random number generator
..add random number to char
send message to receiver
receiver side:
for all chars of message received
..compute random number with given random number generator
..subtract random number from char
Important: Sender and receiver must use a random number generator which generates
same sequence of random numbers. This can be controlled by the random number's seed.
Encryption with superposed random numbers is hardly to break.
>> lionaneesh
Imperator Julius Caesar's encryption/decryption cipher is really way too weak, even for Junior Ones.
-- tesu
>> string currentChar = 0;
should be
char currentChar;
Question: how to finish this loop:
>> while (subscript < numChars) ?
so what about subscript++ ?
Greetings to Cotton State! I've often been to Huntsville :)
-- tesu
Why would you do this recursively? It will be better to do it iteratively.
For example ://assume coefficient is written from highest degree to lowest float evaluate(std::vector<float>& coeff, const float x){ int degree = coeff.size(); float result = 0.0f; for(int i = 0; i != degree; ++i){ float powResult = std::pow(x,degree - i); result += coeff[i] * powResult; } return result; }
Well, firstPerson
your code:
//assume coefficient is written from highest degree to lowest
float evaluate(std::vector<float>& coeff, const float x){
int degree = coeff.size();
float result = 0.0f;
for(int i = 0; i != degree; ++i){
float powResult = std::pow(x,degree - i);
result += coeff[i] * powResult;
}
return result;
}evaluates a polynomial in place x by explicitely computing all x to the power of k, that is: result = coeff[0]*x^degree + coeff[1]*x^(degree-1) +..+coeff[degree] where x^k is given by pow(x,k) method.
Unfortunately, this program code is anything but Horner algorithm.
But you can easily meet Rashakil's stringent requirement for Horner's algorithm by replacing the for-loop and the return statement of your above program code by:
for(int i = 0; i <= degree; i++) result = x*result + coeff[i]; return result;At this point I am far apart from dubbing persons "scrap posters" as Mr Rashakil did. With regard to the somewhat perceived compliment I can't deny myself to cite a more famous German-American guy: "Only two things are infinite, the universe and human stupidity, and I'm not sure about the former.", …
Ignore all these scrub posters and use Horner's algorithm.
Hi Rashakil,
as for Horner you are completely right!
I am already using Horner's first algorithm in this code:
void pore (int d, float a[], float x, float *r){
if (d>0)pore(d-1,a,x,r); *r=x**r+a[d];}
(I have just somewhat minimized this by dropping two curly brackets what is possible if d>=0 is also replaced by d>0.)Just consider:
*r=x**r+a[d]this is very straight Horner's first algorithm. Obviously, you might have ignore this facts accidently.
btw, this very useful scheme should be named after Ruffini because he invited it several years earlier than Horner, therefore all Spanish people call it "Regla de Ruffini".
I am not native English (certainly you have already noticed this), so I would really appreciate you if you could explain the meaning of:
"scrub posters"
to me.
Thank you very much!
-- tesu
Hi,
though your polynomial function calls itself recursively (if we believe that "polinomyal" equals to "polynomial"), yet the value of the polynomial isn't computed recursively instead it is done in for loop if n becomes 0.
You may study this code:
void pore(int d, float a[], float x, float *r){
if (d>=0){pore(d-1, a, x, r); *r = x**r+a[d];}}If pore() is called from this context:
// recursively calculated polynomial
// p(x) = 1*x^3 + 2*x^2 + 3*x^1 + 4*x^0
int d=3; float a[]={1,2,3,4}, x=2.5, r=0;
pore(d, a, x, &r);
cout << "polynomial: " << r << endl;The result is polynomial: 39.625
-- tesu
Is there any error message at all? Did you use correct server, user name, password?
explain connectDB()
-- tesu
there is a problem at assemby86 function.it returns same sequence of random number every time.how we can improve it?
No thanks at all!
assemby86 or to be more specific the random generator inlined in assemby86 has been set up to produce the same sequence of pseudo random numbers every time one is calling it. Such behaviour is really necessary if one is doing serious physical experiments to be sure that the results be reproducible. Ok, that's not that a nice behaviour if using it for creating jokes and games.
If one likes to get various sequences of pseudo random numbers one must change the seed of the related generator. In my former c function changing the seed has been controlled by the range value s. If range value s is negative its absolute value is used as to be new seed. So if one wants to get new sequence of random numbers, first call generator function with negative range value to set new seed, then second, call generator function repeatedly to compute new sequence.
You seems to clever enough to extend this small assembler code getting variable seed. Meanwhile I did some statistical test on this new 16 bit generator and I am really surprised for its chi-square result is really good. The new triple (31, 13, 59049) defines a truly robust random generator, looks like to be the little daughter of Mersenne twister :)
Btw, what do you make of ABBA? I myself …
MS SQL server also supports if and case statements within select. Your statement is syntactically incorrect (and much to complicated, too, to clarify such a problem). In principle if-else (there is no "then") on MS SQL server should look like:
if (select only_one_column from your_table where...) = 'E'
begin
/* contains 'E'
if you are interested in the 'E' of 'Espania'
you would write LIKE '%E%' instead of = 'E'
Here you can do further selects, for example: */
select a, b, c from ... where ...
end
else
begin
/* does not contain 'E' */
endI myself prefer case statement for it acts like a function what is able to return a value.
-- tesu
I have a table in my database named products with the fields id and model in it. Now, I need to get 'all' the products but with different model names and each result represent a valid product.
I have tried with:
select id, modelname, ... from products group by modelname
you can't have a list of columns so as to select and only a subset of those columns listed in the group by clause. In such case all columns to select must also be itemized in group by clause, for example:
select a, b from t group by a, b; -- correct
select a, b, c from t group by a, b; -- wrong
select a, b from t group by b; -- also wrong
select a, b, sum(c) from t group by a, b; -- but this correct-- tesu
can i have a bulk insert into specific columns ..for example just in user_name and u_id?
yes, you need a format file when inserting data in a column's subset. In format file you specify which columns are to insert and which are to overleap.
You may also read there where some aspects of bulk insert had been discussed.
-- tesu
UPDATE yourtable SET price=1 WHERE Name='Apples';It would be really easier and SAVER if you table has primary key.
Consider that
UPDATE yourtable SET price=1;changes all three rows.
-- tesu
Hi,
If you are using EMU8086, I suppose you are about to learn assembly programming and generating a sequence of random numbers seems to be kind of exercise. EMU8086 does not have random number generator. Classical method for computing pseudo random numbers is the linear congruential random number generation method by Lehmer, where a new rnz is given by z(k+1) = (a*z(k) + b) mod m. For you are restricted to 16 bit registers ax, bx etc. I show you a 16 bit Lehmer generator: z = (31*z+13)%19683. Instead of 19683 you can also use 59049 (3*19683) what utilize 16bit (max. 65535) somewhat better.
Below 80x86 code is embbeded in Visual C++ program. You can simply copy this code into EMUs editor (and put some entry and exit code around it). You can then watch the dx register where 10 rnz will be computed within loop RN.
Deep down there is also my C function which I translated into 80x86 assembly. Between assembly and C functions there is a small difference: the return value of C function is furthermore mapped on interval [0..s-1]. This is somewhat more practial when using it. I omitted this not-that-important step in assembly code.
I am sure you will be able to extend the assembly code for storing the rnz appearing in register dx in an array. (If there are problems, simply ask)
int assembly86(){
__asm
{ ; Lehmer linear congruential random number generator
; z= (a*z+b) mod m = (31*z+13)%19683 …Odbc requires that a data source (DSN) be created by means of your operating system. There you have to specify the driver for your specific database. Therfore this driver, delivered by mysql, must be installed priorly on your computer.
On my side we do developing c/c++ aps on and for linux and windows. That is the reason why we use pure odbc.
On windows only I would also prefer Mysql connector/c++ as Ancient Dragon already suggested. Indeed, mysql put the odbc interface and some more stuff into nice c++ class whereby it's really easier to do programming as against pure odbc.
Here you will find detail information on connector/c++. There are also complete examples you can just cut and past them into your c++ ide.
Because connector/c++ also works on odbc the Microsoft odbc manager is required. And that odbc manager always requires that the specific driver of your mysql database be installed. So I am afraid installing an odbc driver on every client side is also necessary, correct me if i am wrong.
-- tesu
On client side you have alreay running a c++ system (VS2008, codeblocks...). Now you need to install Connector/ODBC on your computer. the odbc32.dll is aleady installed with VS2008. Then you should create a datasource for the simplest way to connect to sql database via odbc within c++ program is to using a xp/vista/win7 datasource.
Well, I wrote the cited function SlcProductTable for the guy who was asking for it and i called it from a larger c++ program already using databases to produce the output. I can also write a small main() showing you how to connect to database if you can't proceed.
-- tesu
I am making one small application which can store data to my online mysql server. But with c++ win32 how can I do it?
Hi,
a couple of days I posted something about how to handle SQL databases within C/C++ using ODBC.
You may look here.
If there are any questions you can ask me.
-- tesu
ORG (abbr. for ORiGin) is an assembly directive (not an instruction). It defines where the machine code (translated assembly program) is to place in memory. As for ORG 100H this deals with 80x86 COM program format (COMMAND) which consist of only one segment of max. 64k bytes. 100H says that the machine code starts from address (offset) 100h in this segment, effective address is CS:100H. For com format the offset is always 100H. I suppose that addresses 0 to 100H could be used by bios, but I am not that sure. Another example is ORG 7C00H for intel exe program format.
%%% Example for small assembly program using org 100h
%%% mycom.asm
ORG 100h ; offset for com programs
mov ax, cs ; only one segment contains code+data
mov ds, ax ; data segemt address is equal to code segment adress
mov dx, hel ; Offset of hello world text
mov ah, 09h ; DOS function to output $-terminated string on screen
int 21h ; Call DOS to execute 09H
mov ax, 4C00h ; DOS function 4CH to finish this progam, return code 0
int 21h ; Call DOS
%%%
%%% here is good place for data
hel: db "Hello World$"; Text to output on screen
%%%
%%% translate this assembly program with NASM:
NASM mycom.asm -f bin -o mycom.com-- tesu
...MONTHNAME(DatePaid) as MonthPaid, YEAR(DatePaid) as YearPaid, DatePaid...
As griswolf already stated mostly it isn't a good idea to disassemble a date in year, month, day and storing these parts in a table.
You should only store DatePaid in the view. YEAR(DatePaid) gives then INT (1..12),
MONTH(DatePaid) gives then INT (28,29,30,31).
Atention: MONTHNAME(DatePaid) returns a STRING ! ('January', 'February' ...) which is not useful in ORDER BY for its alphabetical order! ----> MONTH(DatePaid) is almost better.
DatePaid is a date column type in all the related tables in the query.
so when i do AS YearPaid = NOW ( ) it seems to work.
what you think?
Sorry, but YearPaid IS NOT DatePaid !
-- tesu
I then created this query to the view to allow me to create the graph i was having trouble with implimenting the months in the right order:
SELECT MonthPaid AS XLABEL, SUM(Amount) AS YVALUE FROM monthlycommission WHERE YearPaid= NOW( ) GROUP BY MonthPaid ORDER BY DatePaidthis seems to be working but maybe it is not right?
Can hardly be correct. Carefully see my last post just above and compare your code with mine!
Very important to me: please, tell me whether this quoted code, your code, would really run on MySQL without any error messages!
another thing Tesu, what is difference with me using a veiw and querying rather than using a long complex SELECT query instead?
The only difference is that a view can be used everywhere without copying its code, also the selects working on views look somewhat more handier.
A further difference exists if we consider materialized views managing a huge amount of data.
Drawback of views: There are very restrictive rules for updating columns of a view.
I am glad if you progress ...
-- tesu
i created a view like your examples, and where i am struggling is querying it to use with a flash chart:
SELECT MonthPaid AS XLABEL, SUM(Amount) AS YVALUEFROM monthlycommissionWHERE YearPaid= NOW( )GROUP BY MonthPaidi want to order by month in the proper order but cannot find a solution.
Scanning your posts I found:
YearPaid= NOW( ) --> always false for YearPaid is int (2010, 2009 etc) and NOW() is date (2010-06-20). So above query always gives empty result set. Btw, your database should report an error because of incompatible data types.
order by month:
supposing Month and Year can be gotten from DatePaid simply add order by clause:
SELECT YEAR(DatePaid) as cyear, MONTH(DatePaid) AS XLABEL, SUM(Amount) AS YVALUE FROM monthlycommission
WHERE cyear = YEAR(NOW()) GROUP BY cyear, XLABEL ORDER BY XLABELYou can't omit cyear from GROUP BY clause. If you want to drop cyear from output list, you could do a second query on above query:
Select XLABEL, YVALUE FROM
(SELECT DatePaid, MONTH(DatePaid) AS XLABEL, SUM(Amount) AS YVALUE FROM monthlycommission
WHERE YearPaid= YEAR(NOW()) GROUP BY XLABEL) AS must_have_a_name
ORDER BY XLABEL;Don't get distract by this interjection...
-- tesu
Hi andydeans,
there seems to be a lot of problems, kind of going round in circles. I personally would suggest that we should go these problems step by step. In each step we shall handle a small and manageable problem. To each step I'll make a suggestion of sql code. Then it will be your task to get that code running on your database. If errors occur, you must post firstly the ORIGINAL sql statement which caused the error and secondly the complete error message. If and only if a current problem is solved we proceed to next problem.
Possibly we shall go back to the UNION problem, where we should start from with a very simple example. I suggest that we start from the below reduced statements, which are the original sqls posted by you some days ago:
SELECT c.ClientID, c.App1FirstName, c.App1LastName, u.FirstName, u.LastName, MONTHNAME(DatePaid) as MonthPaid, YEAR(DatePaid) as YearPaid, sum(p.amount) as sub_amt, DatePaid
FROM (clients c JOIN users u on c.ClientUserID = u.UserID) JOIN buytolet p on c.ClientID = p.clients_ClientID WHERE DatePaid IS not NULL
UNION SELECT c.ClientID, c.App1FirstName, c.App1LastName, u.FirstName, u.LastName, MONTHNAME(DatePaid) as MonthPaid, YEAR(DatePaid) as YearPaid, sum(p.amount) as sub_amt, DatePaid
FROM (clients c JOIN users u on c.ClientUserID = u.UserID) JOIN mortgage p on c.ClientID = p.clients_ClientID WHERE DatePaid IS not NULLIf this problem is already solved or become obsolete, you could suggest another small problem we can start from. In this case you should post the complete sql code.
Ok, …
Refactoring menu is visible for C# and VB only. Besides primitive search-and-replace, which is incomparable to refactoring, unfortunately, MS do not offer true refactoring for C++.
There exist several refactoring tools for C++ from other vendors which can be plug-in in Visual Studio 2008, some of them are freeware (I just found this: refactor! for C++ from devexpress.com).
In my opinion the lack of true refactoring is a big disgrace and disqualifies VS 2008 from being a convenient professional tool for C++ developers.
-- tesu
Hi,
I suggest to cop a look at open source QT4 (kju:t, really both, the software itself and the generated UI are that cute) which is portable class library for Linux, Windows, Mac. I have been using it for over ten years, and it is a perfect UI tool. QT from Quasar Technologies then Swedish Troll Tech now belongs to Nokia.
btw, KDE is based on QT.
-- tesu
Sorry, my answer should be for your older post MySQL errorno:150.
Which column 'count' you actually mean? Where is it hidden in?
Possibly you should consider what i already stated for errorno 150:
btw, it is always a good idea to declare columuns having auto_increment option unsigned int, e.g. _id unsigned not null auto_increment. On older Mysql versions using int together with auto_increment also mixing int and unsigned int when defining primary and foreign keys sometimes produced similar odd errors.
-- tesu
Hi,
there can be a discrepancy between the innodb data dictionary entry for table assets and additional information still holding separately in assets.frm file (really a mess, mysql should eventually learn not to store information about a table schema in various places! Such data must be hold in data dictionary (system catalog, system tables) soley).
You may look at the server's error log. If there is an error message saying that table assets already exists, try to DROP TABLE assets. If all else fails, instead of trying to fix this odd problem it is often easier to give the concerning table just another name.
btw, it is always a good idea to declare columuns having auto_increment option unsigned int, e.g. _id unsigned not null auto_increment. On older Mysql versions using int together with auto_increment also mixing int and unsigned int when defining primary and foreign keys sometimes produced similar odd errors.
--tesu
...Note the error at: alterInstructor.
I create the instructor table then the booking table. The instructor table has book_num FK.
After the booking table is created I run the script alterTable to alter the instructor table.Note: the alterPayee script runs fine but the book_num is a different data type. Is this a problem?
It creates the database but it says there is an error when it tries to alter the instructor table....
Well, you are showing that much sql code except the most important script which do the ALTER TABLE ....
You should consider:
1. All your table should have primary keys, at least the table where a foreign key is referencing to must have one. That is book_num must be primary key of booking table.
2. The order of ALTER statements is important: The object a reference points to must already exist. So the order should be: Alter table booking ADD primary key... ; Alter table instructor ADD foreign key ... ;
3. Whether different datatypes are significant or not depends on whether the database is able to do the converting automatically. If not possible, you need an cast() explicitly. If the datatypes are too different, also cast() won't work. You should read and understand derby manual about the compatibility and (automatical) typecasting of DTs.
4. If you have inserted some data before defining foreign keys, sometimes this is impossible depending on already existing constraints (e.g. NOT NULL etc). Also …
...For doing the mathematical operation I need to extract d data from d table and STORE it in another variable in d C program....
my doubt was how to initialise a variable in a C program wid a data from a table...thts all...
Sorry, I didn't notice those questions earlier. Here is some C code showing you how to fetch specific rows from a table. I used prepare statement, binding methods and SQLExecute this time. You might do wee changes to fit this code to your current database.
void SlcProductTable(SQLHENV hEnv, SQLHDBC hDbc, SQLINTEGER quantity )
{
SQLHSTMT hStmt;
SQLRETURN rc;
SQLINTEGER pID, pQuantity;
SQLLEN c_len=SQL_NTS;
SQLCHAR pName[80], pDate[20];
SQLREAL SalesPrice;
printf("Rows of products having quantity < %d\n", quantity);
// Statement handle
rc = SQLAllocHandle( SQL_HANDLE_STMT, hDbc, &hStmt);
// Get pID, pName, date, quantity and salesPrice from product table
SQLCHAR sqlStatement[] =
"SELECT pID, pName, convert(char(20), pDate, 104), quantity, salesprice FROM products "
"WHERE quantity < ?;";
// Prepare SQL statement
rc = SQLPrepare(hStmt, sqlStatement, SQL_NTS );
// Bind host variables on columns coresponding to sql statement
rc=SQLBindCol(hStmt, 1, SQL_C_SLONG, &pID, 0, NULL);
rc=SQLBindCol(hStmt, 2, SQL_C_CHAR, pName, sizeof(pName), &c_len);
rc=SQLBindCol(hStmt, 3, SQL_C_CHAR, pDate, sizeof(pDate), &c_len);
rc=SQLBindCol(hStmt, 4, SQL_C_SLONG, &pQuantity, 0, NULL);
rc=SQLBindCol(hStmt, 5, SQL_C_FLOAT, &SalesPrice, 0, NULL);
// Bind host variable quantity on parameter (?) of where clause
rc = SQLBindParameter( hStmt, 1, SQL_PARAM_INPUT, SQL_C_ULONG,
SQL_INTEGER, 0, 0, &quantity, 0, NULL);
// execute prepared statement
rc = SQLExecute(hStmt);
printf("PID Product Date Quantity Salesprice\n" "---------------------------------------------------------------------------\n");
// Fetch rows from …