In your example, x == y == -1.0. The vector (-1.0, -1.0) makes an angle of -135.0 degrees with the horizontal axis, and not 45.0 degrees. So math.atan2() is correct.
Gribouillis1,391 Programming Explorer Team Colleague
If no line of /Users/some_user/Desktop/passwords.txt contains a colon, your program won't print any output. Add a call to print() for every line in the loop.
Edit: I just noticed the call to readline(). It reads only a single line. Use readlines().
Gribouillis1,391 Programming Explorer Team Colleague
It is already efficient (1.6 microseconds on my computer)
>>> from timeit import Timer
>>> L = [1,2,3,4,5,6,7,8,9,10]
>>> # run your statement 1 million times
>>> Timer("sum([(i) for i in L if i%2 ==0])", "from __main__ import L").timeit()
1.607414960861206
>>> # removing the inner list construction is surprisingly less efficient
>>> Timer("sum(i for i in L if i%2 ==0)", "from __main__ import L").timeit()
1.9511890411376953
>>> # gain a little by avoiding the modulo operator
>>> Timer("sum([i for i in L if not (i & 1)])", "from __main__ import L").timeit()
1.4257829189300537
Gribouillis1,391 Programming Explorer Team Colleague
You can download one here, called pydrawing, which claims to draw diagrams in a tkinter canvas.
Python and tkinter have been around for 20 years, which means many attempts to write paint programs. There is a basic example in Mark Lutz' book 'programming python'.
The first step in your project is to crawl the web ;)
Gribouillis1,391 Programming Explorer Team Colleague
class A(object): # <--- small 'c'
def __init__(self):
self.a = 4 # <--- a and b are instance variables (not class variables)
self.b = 6
class B(A):
def __init__(self): # <--- watch the number of underscores
A.__init__(self) # <--- call parent class constructor explicitely
#some code
def Action(self):
self.a = 9 # <--- update member a
Gribouillis1,391 Programming Explorer Team Colleague
Permission denied means that the user who is running your python program doesn't have the permission to list the directory, or to run Snes9x, or that Snes9x is not an executable program, etc. It is a system issue, not a python issue.
Gribouillis1,391 Programming Explorer Team Colleague
The interpreter only obeys python's grammar which says that both sides of a comparison operator must be "or_expr"s (one of python's syntactic categories). An expression like not ... can not be considered an or_expr. With parenthesis, it becomes an "atom", which can be considered as an "or_expr". Grammar is a cold mechanism, don't think python does anything clever here :)
Gribouillis1,391 Programming Explorer Team Colleague
os.getenv('PATH') is the sequence of folders where the operating system finds executable programs. sys.path is the sequence of folders where python finds importable modules.
Gribouillis1,391 Programming Explorer Team Colleague
I'm not (yet) a specialist of web frameworks in python, but yes, one of the purposes of templating systems is to mix html code and python code. The main idea is to write html files containing python expressions and blocks of code with a special markup syntax. This file is called the template. The templating system provides a render() method which evaluates the template in a certain python context, and you can output the resulting html.
If you want a powerful and simple templating system, try Mako which benefits from the experience of many other python templating engines developped in the last 15 years. Among other things, mako templates can be compiled into python modules for performance. They also implement an inheritance system between templates see here. I think this templating system can very well be used with web.py or other frameworks.
Another nice feature of mako templates is that they can be used for completely different purposes. For example I use them to produce restructured text files, post-processed by rstex and latex to write scientific papers.
Gribouillis1,391 Programming Explorer Team Colleague
If it is a csv file, it would be easier to read with the csv module. You would select the first entry of each row to get the first name. Can you post a few rows of your file (with real names and addresses replaced by similar fancy data) ?
Gribouillis1,391 Programming Explorer Team Colleague
The only thing you need to do is determine which lists you want to append to Resistance. For example if you want to append the values from a column numbered k, you can write
def column_values(rows, k):
for row in rows:
yield row[k]
rows = list(Reader) # convert to list in case Reader is a generator.
Resistance.append(list(to_float(column_values(rows, 0))))
Gribouillis1,391 Programming Explorer Team Colleague
def to_float(sequence):
"""Generate a sequence of floats by converting every item in
a given sequence to float, and ignoring failing conversions"""
for x in sequence:
try:
yield float(x)
except ValueError:
pass
Now if you want to append all the values in columns 4, 5, ... for all rows, you can write a generator
def sheet_values(reader):
"""Generate the cell values that we want to convert and append to Resistance"""
for row in reader:
for x in row[4:]:
yield x
If n is an integer, n << 8 is equivalent to n * (2**8). The << operator is called the left shift operator. It comes from the binary representation of integers, for example 6 is represented as 110 in binary form, and 6 << 3 as 110000. Other languages use the same convention (in particular the C language, the mother of so many languages).
In python there is no theoretical limit to the size of integers, so that you can write 6 << 1000 and still obtain 6 * 2 ** 1000. This wouldn't work in languages where integers are limited to 32 bits or 64 bits.
Another feature of python is that the binary operator << can be overloaded and have an arbitrary different meaning for user defined data types.
Gribouillis1,391 Programming Explorer Team Colleague
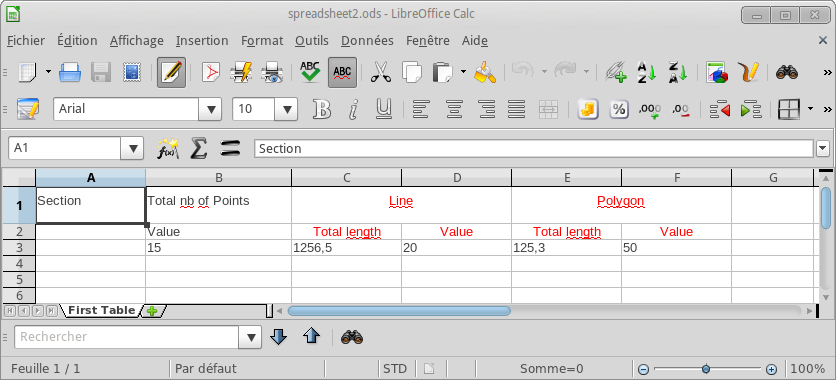
I think this is not possible in csv. Csv does not contain any cell style information. I was able to produce an open-document spreadsheet using the development version of lpod-python (the function to merge cells was added 1 month ago). Here is the code
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
from __future__ import unicode_literals, print_function, division
import os
from lpod.document import odf_new_document
from lpod.table import odf_create_table
from lpod.style import odf_create_style
if __name__=="__main__":
data = [
["Section\n", "Total nb of Points\n", "Line\n", None, "Polygon\n", None],
[None, "Value", "Total length", "Value", "Total length", "Value"],
[None, 15, 1256.5, 20, 125.3, 50],
]
cellstylenum = odf_create_style('table-cell', name='cellstylenum')
cellstylenum.set_properties(area='paragraph', align='start')
cellcenterred = odf_create_style('table-cell', name='cellcenterred')
cellcenterred.set_properties(area = 'text', color="#FF0000")
cellcenterred.set_properties(area='paragraph', align='center')
celltopred = odf_create_style('table-cell', name='celltopred')
celltopred.set_properties(area = 'text', color="#FF0000")
celltopred.set_properties(area='paragraph', align='center')
col3cm = odf_create_style('table-column', width='3cm')
col4cm = odf_create_style('table-column', width='4cm')
row1cm = odf_create_style('table-row', height='1cm')
document = odf_new_document('spreadsheet')
document.insert_style(col3cm, automatic=True)
document.insert_style(col4cm, automatic=True)
document.insert_style(row1cm, automatic=True)
document.insert_style(cellstylenum, automatic=True)
document.insert_style(cellcenterred, automatic=True)
document.insert_style(celltopred, automatic=True)
body = document.get_body()
table = odf_create_table(u"First Table", width = len(data[0]), height = len(data))
body.append(table)
for r in range(len(data)):
for c in range(len(data[r])):
if data[r][c] is None:
continue
z = table.get_cell((c, r))
z.set_value(data[r][c])
if r == 0 and c >= 2:
z.set_style(celltopred)
elif r == 1 and c >= 2:
z.set_style(cellcenterred)
elif r >= 2:
z.set_style(cellstylenum)
table.set_cell((c, r), z)
table.set_span((2,0,3,0))
table.set_span((4,0,5,0))
for column in table.get_columns():
column.set_style(col4cm if column.x == 1 else col3cm)
table.set_column(column.x, column)
pass
row = table.get_row(0)
row.set_style(row1cm)
table.set_row(row.y, row)
#print("table size:", table.get_size())
table.rstrip(aggressive=True)
print(table.to_csv())
test_output_dir = 'test_output'
if not os.path.exists(test_output_dir):
os.mkdir(test_output_dir)
output = …
Gribouillis1,391 Programming Explorer Team Colleague
loc = locals()
pf_list = [loc["p%sf" % x] + float(loc["p%s" % x]) for x in "abcdefgh"]
ps_list = ["%.2f" % val for val in pf_list]
or dicts
loc = locals()
pf_dict= dict((x, loc["p%sf" % x] + float(loc["p%s" % x])) for x in "abcdefgh")
ps_dict = dict((k, "%.2f" % v) for (k, v) in pf_dict.items()]
print(ps_dict["a"], ps_dict["b"])
Gribouillis1,391 Programming Explorer Team Colleague
The pickle serialization format is guaranteed to be backwards compatible across Python releases.
I think it means that today's python can read yesterday's pickles (see here) but not the contrary.
However, I really think you should check data integrity first. The other thing you can do is dump with the ASCII protocol 0 to see if it changes anything.
Gribouillis1,391 Programming Explorer Team Colleague
pickle.loads() works very well unless the pickle was written with a different version of python. What you can do is check the integrity of your data by sending the data together with an md5 or sha sum (see module hashlib). Your remote process must compute the checksum of the pickled data that it writes to output, and your program must compute the checksum of the received data before calling pickle.loads(). This should tell us if the error comes from pickle.loads() or not. The standard library functions are heavily tested, so the number 1 suspect is your own program.
Gribouillis1,391 Programming Explorer Team Colleague
These objects are only created once and stored in the views list, but their repaint_canvas() method is called every time we switch the views. You could change this and always create new objects if you want, but you'd need a good reason to do so. These objects only hold a pointer to the application's canvas, there is no memory leak to worry about.
Gribouillis1,391 Programming Explorer Team Colleague
Take a page containing a list of sentences, like this one (take only the first 5 sentences). Then with a calculator, compute the average number of words per sentence by hand and note carefully everything you do. This should give you a working algorithm. Write pseudo code, then python code.
Gribouillis1,391 Programming Explorer Team Colleague
from collections import namedtuple
FileInfo = namedtuple("FileInfo", "path foo bar baz")
mylist=[]
for file in glob.glob(inputpath+"\\*.txt"):
mylist.append(FileInfo(file, value1, value2, value3))
import pickle
pkl = "fileinfo.pkl"
with open(pkl, "wb") as ofh:
pickle.dump(mylist, ofh)
with open(pkl, "rb") as ifh:
print(pickle.load(ifh))
Gribouillis1,391 Programming Explorer Team Colleague
i made two python files and both python files will gives some output and i want to print that output at the same time by using third python file by the help of multithreading, how could i do that,
I found your question interesting, so I wrote a small class to do this, see if it can help you
#!/usr/bin/env python
# -*-coding: utf8-*-
# file printerthread.py
from __future__ import unicode_literals, print_function
import Queue
import sys
import threading
class PrintingThread(threading.Thread):
def __init__(self, file = sys.stdout):
threading.Thread.__init__(self)
self.queue = Queue.Queue()
self.cond = threading.Condition()
self._shutdown = 0
self.file = file
def run(self):
with self.cond:
while True:
self.cond.wait()
if self._shutdown == 2:
self._abort()
return
else:
self._print_queue()
if self._shutdown:
return
def shutdown(self, value = 1):
assert value in (1, 2)
with self.cond:
self._shutdown = value
self.cond.notify()
self.join()
def _abort(self):
try:
while True:
self.queue.get_nowait()
self.queue.task_done()
except Queue.Empty:
return
def _print_queue(self):
try:
while True:
data = self.queue.get_nowait()
self.file.write(data)
self.queue.task_done()
except Queue.Empty:
return
def print(self, *args, **kwd):
sep = kwd.get('sep', ' ')
end = kwd.get('end', '\n')
s = sep.join(str(x) for x in args) + end
self.write(s)
def write(self, s):
if len(s) == 0:
return
with self.cond:
self.queue.put(s)
self.cond.notify()
Here is a possible main program
#!/usr/bin/env python
# -*-coding: utf8-*-
from __future__ import unicode_literals, print_function
from printerthread import PrintingThread
import time
def main():
t = PrintingThread()
t.start()
for i in range(5):
time.sleep(1)
for j in range(3):
t.print(time.time())
t.shutdown()
if __name__ == "__main__":
main()
#=======================================================
""" my output -->
1354444871.71
1354444871.71
1354444871.71
1354444872.71
1354444872.71 …
Gribouillis1,391 Programming Explorer Team Colleague
In your code, num is a string, and numin is an integer. It means that the arithmetic expressions involving num won't work as expected. The best thing to do is to replace line 2 with num = int(num) and forget about numin. You can even write num = int(num) % 100.
To answer your initial question, you can write print "%dst" % 121, or print "{0}st".format(121) or print str(121) + "st". My preferred way is the format method.
The last elif... in your code could also be replaced by a single else:. It seems to me that if (num % 10 == 1) and (num != 11) would be easier for the reader that num > 20, etc. You could also have a variable r = num % 10 and write if (r == 1) and (num != 11) etc.
Finally, here is an advanced solution
num = int(num) % 100
suffix = dict(enumerate(("st", "nd", "rd"), 1))
s = "th" if num in (11, 12, 13) else suffix.get(num % 10, "th")
print "{0}{1}".format(num, s)
Gribouillis1,391 Programming Explorer Team Colleague
If you don't want to generate the page dynamically, you can generate it once a week and store an html file when you run your script. You could use a template engine like Mako for variable substitution in the html file. It is very easy to do.
Gribouillis1,391 Programming Explorer Team Colleague
People stuck with XP because it was lean and clean, and didn't want to change to Vista because it was slow and clumsy? Is that the kind of issue between Python 2x and Python 3x?
No it's not exactly that kind of issue. Python 3 is actually cleaner than python 2. Only many libraries were written for python 2 and people are slow porting them to python 3.
You can have more than one install of python on your computer. If your editor needs python 2 to run, you can still write python 3 code with it !
Gribouillis1,391 Programming Explorer Team Colleague
You can tell where the function was called from using module inspect
#!/usr/bin/env python
# -*-coding: utf8-*-
from __future__ import unicode_literals, print_function
__doc__ = """ sandbox.funccall -
show how to print where a function was called from
"""
import inspect
import os
def calling_line(level):
level = max(int(level), 0)
frame = inspect.currentframe().f_back
try:
for i in xrange(level):
frame = frame.f_back
lineno, filename = frame.f_lineno, frame.f_code.co_filename
finally:
del frame
return lineno, filename
def thefunc(*args):
lineno, filename = calling_line(1)
print("thefunc() was called from {0} at line {1}".format(
os.path.basename(filename), lineno))
return 3.14
def foo():
x = thefunc() ** 2
if __name__ == "__main__":
foo()
""" my output -->
thefunc() was called from funccall.py at line 32
"""
Otherwise, yes, nametest.__name__ = ... resets the original variable. __name__ is an ordinary global variable which is automatically inserted in the module's namespace. Another interesting variable which exists only for imported modules is__file__.
Gribouillis1,391 Programming Explorer Team Colleague
This python 2.7 snippet adds a thin layer of sugar on the itertools module's api, allowing many of its functions to be used as decorators and adding some new functions. Enjoy !