Very good. I would have written shutil.move(files, client_folder). Another solution is to create a sequence of files to move first
def to_move(folder):
"""generate the files to move"""
wd = os.getcwd()
os.chdir(folder)
try:
for name in glob.glob('*.*'):
if 'client_name' in str(name).lower():
yield os.path.join(folder, name)
finally:
os.chdir(wd)
src_dir = r'd:\Desktop'
L = list(to_move(src_dir))
Gribouillis1,391 Programming Explorer Team Colleague
I disapprove inflammatory debates in daniweb. I had one once with a knowledgeable programmer and some time later, he ceased to connect. I think he had too strong convictions and he wanted everybody to agree.
Gribouillis1,391 Programming Explorer Team Colleague
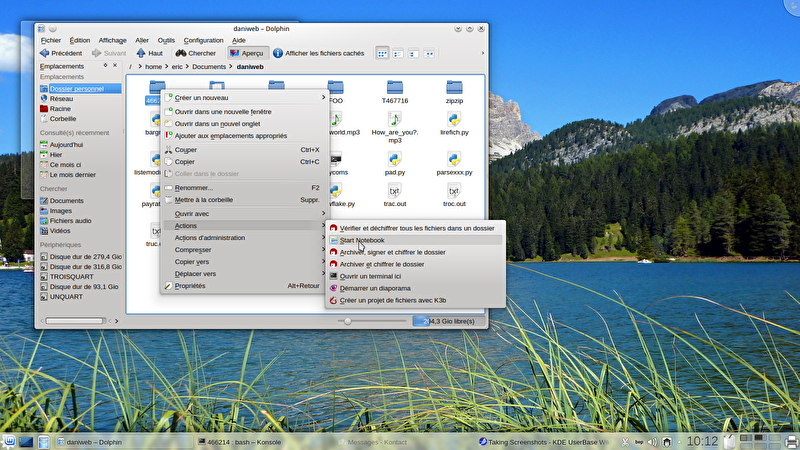
This snippet is reserved for users of the KDE linux desktop. It adds a service menu to kde applications such as dolphin and konqueror, to launch an ipython dashboard in a directory in one click.
More specifically, save the text of this snippet as a file ~/.kde/share/kde4/services/ServiceMenus/opennotebook.desktop (create the directory if necessary). Make sure ipython is installed. You may prefer an install via sudo pip install ipython over your distribution's ipython-notebook package (I experienced issues with ipython older than 1.1.0).
Then open dolphin and right-click a directory. In the Actions submenu, there should be an entry Start Notebook. Upon clicking this entry, a konsole tab opens which runs an ipython notebook. A web page appears in the default web browser which is the ipython dashboard for notebooks stored in this directory. We are ready to use python comfortably in 2 clicks !
I use this service menu every day, and it is very handy. I hope you'll enjoy it.
Gribouillis1,391 Programming Explorer Team Colleague
Dont like that there is no source code comment pointing out where to get it and that there is no info if it supports py3. Cant use it, downvote therefore.
I did not write this with python 3 in mind. For windows you can download pythonmagick binaries for python 3 in Christoph Gohlke's site.
I was not able to install pythonmagick for python 3 in linux mint (as of November 24th 2013). You can use other python wrappers around ImageMagick however. For example I tried a ctypes wrapper magickpy, installed using pip3 (package python3-pip in linux mint). Here is the code
The 4 letters words are nodes in a graph where adjacent nodes differ by one letter from the current node. Starting from the startword, you can do a depth first walk of the graph until you reach the endword. I posted a clue for depth first traversal here (replace urls with 4 letter words).
Gribouillis1,391 Programming Explorer Team Colleague
Importing a hierarchy of firefox bookmarks in konqueror can be tricky, as konqueror's bookmarks editor doesn't read firefox's sqlite databases where the bookmarks are stored.
Konqueror bookmarks are normally stored in a file ~/.kde/share/apps/konqueror/bookmarks.xml , which is actually a dialect of xml named xbel.
I found very little documentation about this transition, and my first attempt was to export firefox' bookmarks in html format, then import the html bookmarks from konqueror. Unfortunately, it failed to import the subfolders in the tree of bookmarks. It seems to me that this forum is a good place to post a working solution.
The solution is to install the Opera web browser, which can import bookmarks from firefox' places.sqlite file. Once the bookmarks are in Opera, they can be exported in an opera bookmarks format file (extension .adr). Then Konqueror's bookmarks editor is able to import those opera files. HaHa!
All my subfolders were correctly imported into Konqueror.
The best thing to do is to post your attempts to decipher your text with python in this thread. We may be able to help you but nobody will write the code for you.
Gribouillis1,391 Programming Explorer Team Colleague
One problem is that you start each year with c = 1 on the first day. Since your criterion for sundays is c%6 == 0. It means that every year starts with a tuesday.
Gribouillis1,391 Programming Explorer Team Colleague
Here is an example with 2 worker threads. It uses Condition objects to synchronize threads. It is relatively easy to understand if you remember that only one thread may own a given condition at a given time, which means for example that a worker blocks on with G.wcond if another thread is in a with G.wcond section, unless the other thread is running a G.wcond.wait() statement.
from threading import Thread, Condition
import time
class G:
wcond = Condition()
pcond = Condition()
can_work = False
can_process = True
class Worker(Thread):
def run(self):
while True:
with G.wcond:
while not G.can_work: # we wait for permission to work
G.wcond.wait()
self.do_work()
G.can_work = False
with G.pcond: # we give permission to process
G.can_process = True
G.pcond.notify()
def do_work(self):
for i in range(3):
print("working ...", self.name)
time.sleep(0.2)
class Processor(Thread):
def run(self):
while True:
with G.pcond:
while not G.can_process: # we wait for permission to process
G.pcond.wait()
self.do_process()
G.can_process = False
with G.wcond: # we give permission to work
G.can_work = True
G.wcond.notify()
def do_process(self):
for i in range(2):
print("processing ...")
time.sleep(0.2)
w, w2, p = Worker(), Worker(), Processor()
w.start()
w2.start()
p.start()
"""my output -->
processing ...
processing ...
('working ...', 'Thread-4')
('working ...', 'Thread-4')
('working ...', 'Thread-4')
processing ...
processing ...
('working ...', 'Thread-5')
('working ...', 'Thread-5')
('working ...', 'Thread-5')
processing ...
processing ...
('working ...', 'Thread-4')
('working ...', 'Thread-4')
etc
"""
With regard to your code, notice that
The Thread's run() method must contain the thread's action, instead of its __init__() method.
…
Gribouillis1,391 Programming Explorer Team Colleague
In this case, compute the GPA by hand, without your computer, and write down carefully every detail of your procedure. This should give you the algorithm.
Gribouillis1,391 Programming Explorer Team Colleague
The errors come from bad bookkeeping of the index i
def lapping(x1, x2):
x1, x2 = str(x1), str(x2) # in case integers are passed to lapping()
not_lapped= True #used to test if there was no lapping
i = -1
for sets in Big_Set[:-1]: # don't use the last set
i += 1
if x1 in sets:
y = sets.index(x1) # the first position where x1 is
if x2 == Big_Set[i+1][y]:
print("%s and %s laps in sets: " %(x1, x2))
print("set%d: %s" %(i+1,str(sets)))
print("and")
print("set%d: %s" %(i+2,str(Big_Set[i+1])))
not_lapped= False
if not_lapped:
print("%s and %s do not match the lapping criteria\n" %(x1,x2))
Gribouillis1,391 Programming Explorer Team Colleague
One drawback of this approach is that window is not automatically garbage collected, and if you want several instances, you'll have to use a container.
Gribouillis1,391 Programming Explorer Team Colleague
Congratulations, this is good python code. Its naming style however is unusual for python code. You may want to read pep 8, a style guide written for the developpers of the python language trunk. If you follow this style everybody will think you are a very experienced pythonista.
Also string.Template is seldom used. Most programmers would choose the method str.format() for this.
The 5/pi limit explains easily. The polygon perimeter is 10 in your example (n * s). This is the perimeter of a circle with radius 5/pi.
os.walk('.') means that you are traversing the current working directory with os.walk (as returned by os.getcwd()). If you run the code while in the X0.0 directory, os.walk will never see the X0.05 directory.
The current working directory does not change during the walk. To create psub in a subfolder, you must write
psub = os.path.join(root, 'psub')
with open(psub, 'a') as writer:
...
You can also unindent line 5 as the contents of 'top.txt' is stored in the string data.
Gribouillis1,391 Programming Explorer Team Colleague
Here is a complete (simplified) running example. Try it in the directory with the .out files
#!/usr/bin/env python3
#-*-coding: utf8-*-
import os
# split the code into several functions to lighten it
def main():
with open('results.txt', 'a') as writer:
for file in os.listdir('.'):
if not file.endswith('.out'):
continue
with open(file, 'r') as reader:
handle_reader(reader, writer)
def handle_reader(reader, writer):
print('reading file:', reader.name, file = writer)
opt_cnt = 0
for line in reader:
s=line.strip()
if s=='**** Optimisation achieved ****':
opt_cnt += 1 # <-- count those lines
print('optimisation line number', opt_cnt, end ='\n', file = writer)
else:
pass
if __name__ == '__main__':
main()
Gribouillis1,391 Programming Explorer Team Colleague
There are different ways. 1: declare outline global inside the function
outline = True # when the program starts
def toggle(*args): # args ignored
global outline # at the top of the function
if outline == True:
outline = False
if outline == False:
outline = True
2: use a class to hold global variables (avoid global statement)
class glo:
outline = True # when the program starts
def toggle(*args):
glo.outline = not glo.outline
3: use a module to hold global variables (especially useful is your program uses more than one file)
# in file glo.py
outline = True
# in your main program
import glo
def toggle(*args):
glo.outline = not glo.outline
3: Create a class to hold global variables and function and use a single instance
class MyApp:
def __init__(self):
self.outline = True
def toggle(self, *args):
self.outline = not self.outline
if __name__ == '__main__':
my_app = MyApp()
# ...
Button(..., command = my_app.toggle)
#...
foo.mainloop()
4: etc
Gribouillis1,391 Programming Explorer Team Colleague
Python 3.3.1 (default, Apr 17 2013, 22:32:14)
[GCC 4.7.3] on linux
>>> "Give me {0} and {2}, said the {1} man".format("bacon", "other", "eggs")
'Give me bacon and eggs, said the other man'
>>> "Give me {0} and {2} eggs, said the {1} man".format("bacon", "other", 5)
'Give me bacon and 5 eggs, said the other man'
>>> "Give me {0} and {2:.2f} eggs, said the {1} man".format("bacon", "other", 5)
'Give me bacon and 5.00 eggs, said the other man'
>>> "Give me {} and {}, said the {} man".format("bacon", "eggs", "other")
'Give me bacon and eggs, said the other man'
>>> "Give me {} and {:.2f} eggs, said the {} man".format("bacon", 5, "other")
'Give me bacon and 5.00 eggs, said the other man'
Gribouillis1,391 Programming Explorer Team Colleague
It's a very good idea to use parenthesis in your print statements as if you were using a function. It teaches you python 3 at the same time. If you add the line
from __future__ import print_function
as the first statement of your module, it will turn print into a true function. Then you can use
print('#', '-' * num, sep='')
or
print('#', end = '') # don't print a newline
print('-' * num)
Gribouillis1,391 Programming Explorer Team Colleague
This line uses the string format() method to build a regular expression. For example
>>> import re
>>> wanted = ('cat', 'dog', 'parrot')
>>> regex = '^(?:{0})'.format('|'.join(re.escape(s) for s in wanted))
>>> regex
'^(?:cat|dog|parrot)'
This regex is able to tell if a string starts with any of the words cat, dog and parrot. Read this for a tutorial on regular expressions and this for the format() method.
Gribouillis1,391 Programming Explorer Team Colleague
& is the integer bitwise and operator. When n is an integer, n & 1 is the value of its first bit in base 2. Therefore, n & 1 has value 0 if n is even and 1 if n is odd. not n & 1 has the same meaning as n is even (which is less cryptic but is not python). Another way to say it is n % 2 == 0, but vegaseat thinks he gains some speed.
Gribouillis1,391 Programming Explorer Team Colleague
Replace [user] by "user":{ and [/user] by },. In the same way, replace [name] with "name":" and [/name] with ",. Do this with all the tags, then call eval()
Gribouillis1,391 Programming Explorer Team Colleague
Not sure how to handle the comma that is used in some countries as a decimal point.
We could have a concept of "dialect" like the csv module, with fields like "thousand_sep", "decimal_pt". In the business_fr dialect, thousand_sep would be a space and decimal_pt a comma.
Gribouillis1,391 Programming Explorer Team Colleague
This can be understood mainly by examining the history of these languages. C++ was an object oriented development of C at the time where OOP was the new paradigm. Perl started as a system scripting language which was more structured than shell languages. It was then heavily used when internet was based on cgi scripts and there was no other alternative. Php succeeded because it made it possible to include dynamic code in html pages.
Python is different. It started as a general purpose language derived from a small university language called ABC. Its success comes from experience: people realized that using python led to drastic cuts in their programming effort!
#!/usr/bin/env python
import sys
def handle_args(args):
s = False
for a in args:
if a == '-s':
if s:
break
else:
s = True
else:
yield (s, a)
s = False
if s:
raise RuntimeError('missing argument for -s')
for item in handle_args(sys.argv[1:]):
print(item)
'''my output --->
(False, 'firstargument')
(False, 'secondargument')
(True, 'thirdargument')
(True, 'fourth')
(False, 'fifth')
(True, 'sixth')
'''
Gribouillis1,391 Programming Explorer Team Colleague
If the searched text is in a single line, you can read the file line by line:
import itertools as itt
def wrong_line(line):
return 'card 1:' not in line
with open('filename.txt') as ifh:
result = list(itt.islice(itt.dropwhile(wrong_line, ifh), 1, 3))
# result should be the list [' ball\n', ' red\n']