msg=box.content(id[0]) # <-- how will i be able to copy this sms file to a string
print type(msg) #Show what datatype msg is
print msg #Try to print the message
Ok here you go,read a little more about dictionary an basic stuff;)
pairs =\
{"Jeremy": "Jerome",
"Jason": "Fred",
"Joe" : "Fred",
"Alayna" : "Tom",
"Jay" : "Jerome",
"April" : "Tom"}
def find_father():
print "\n This is your current list \n\n", pairs.keys() #We print only sons name
choice_name = raw_input("Please enter a Name: ")
if choice_name in pairs:
print 'Father of %s is %s ' % (choice_name, pairs[choice_name])
else:
print 'Name not in database'
raw_input("\nTrykk enter for meny\n")
def main():
'''Main menu and info '''
while True:
print 'Father finder'
print '(1) Find a Father'
print '(q) Quit'
choice = raw_input('Enter your choice: ')
if choice == '1':
find_father()
elif choice == 'q':
return
else:
print 'Not a correct choice:', choice
if __name__ == '__main__':
main()
CGI is run from server side,so you can say it`s a sever side like php but you write in python. So if you want to test it out use local server like xampp/wamp.
So there is possible to make a html form calulator and let python do calculations.
A more commen way is like postet over,to use a python web-framework.
Change the code with and try-except block,so it dont crash when letter is the input.
def dec():
while True:
try:
x = float(raw_input('enter number: '))
if x % 1 == 0:
print ("The number entered must be a decimal number")
else:
return x
except ValueError:
print 'Numer only'
dec()
Here you have one way off do it. This is for python 3 that i think you use. Homework?,they may spot that you havent wirte this code(some smart shortcut in this code) You may work on the for loop you startet with(now your code is not working)
def makeList():
num = input('Please enter the number of strings you want to input\n')
alist = []
for i in range(int(num)):
x = input('Enter string please: ')
alist.append(x)
return sorted(alist)
def findShortest(alist):
min_list = min(alist, key=len)
return (min_list)
def findLongest(alist):
max_list = max(alist, key=len)
return max_list
def findAlpha(alist):
alpha_list = [item for item in alist if str(item).isalpha()]
return alpha_list
def main():
alist = makeList()
print ('Sorted list is:\n{0}'.format(alist))
print ('Shortest element is:\n{0}'.format(findShortest(alist)))
print ('Longest element is:\n{0}'.format(findLongest(alist)))
print ('Only alphabetic characters is:\n{0}'.format(findAlpha(alist)))
if __name__ == "__main__":
main()
'''Out-->
Sorted list is:
['car', 'taxi', 'train5']
Shortest element is:
car
Longest element is:
train5
Only alphabetic characters is:
['car', 'taxi']
'''
Tkinter has an native an rather ugly look on windows. Use another tool kit like wxpython(my favorite) or PyQt. They look good on windows and have more lot option for creating good looking GUI.
I was wondering if there are any GUI toolkits in python that create native-looking windows in Windows 7
Wxpython-PyQt dont have the ugly and native-looking that Tkinter has on all windows version. Tkinter look better on linux,mac. I postet a wxpython picture here. http://www.daniweb.com/forums/thread252780.html Wxpython are a very good gui-toolkit and you have a lot more option than tkinter.
There is no confusion about how my function work. It will return a correct date format in yyyymmdd an nothing else.
I know regular expression is not easy to learn and can be confusing. The other way is to check every number with range function or a tuple version. Look at this post here you see how to check that numbers are correct without regular expression. http://www.daniweb.com/forums/thread265942.html
For this regular expression can be to help. This funtion will only return correct date format in | yyyy-mm-dd | or | yyyy/mm/dd |
import re
def foo():
while True:
print 'use format | yyyy-mm-dd |'
date_input = raw_input("Enter date: ")
if re.match(r"(?:(19|20)[0-9]{2}[- /.](0[1-9]|1[012])[- /.](0[1-9]|[12][0-9]|3[01]))\Z", date_input):
print 'Match'
return date_input
else:
print 'No match,try again'
print foo()
'''-->Out
use format | yyyy-mm-dd |
Enter date: 2000-13-25
No match,try again
use format | yyyy-mm-dd |
Enter date: 2000-12-25
Match
2000-12-25
'''
Yes i have to wait for 3 party libraries to be ported to python 3.x. Like wxpython very much so have to wait for that to by portet to python 3.x Have off course python 3.x installed to look at changes.
Twistet i think will not be ported to python 3.x before 2015. I think there is no problem at all to stay with python 2.x,if project that not need 3 party libaryes then man can use python 3.x
You have to see difference between python 2.x and python 3.x Most off us will use python 2.x for a copule off year til 3 party moduls is rewritten for python 3.x
Here is code for python 3.x
h2 = range (0,4)
m1 = range(0,6)
m2 = range(0,10)
mtime_range = (0,4)
def valid_mtime(mtime):
if len(mtime) not in mtime_range:
print ('Not correct lenght')
return
if (int(mtime[0]) in h1 and int(mtime[1]) in h2) and (int(mtime[2]) in m1 and int(mtime[3]) in m2):
print ('true')
else:
print ('false')
The tuple version from __qwerty__ work also good. You can rewrite as traning for python 3.x
>>> h
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]
>>> mtime = '2350'
>>> mtime
'2350'
>>> mtime[0]
'2'
>>> mtime[1]
'3'
>>> if mtime[0] in h:
print 'true'
>>> if int(mtime[0]) in h:
print 'true'
true
>>> len(mtime)
4
>>> #Here you see one problem in __qwerty__ code have to change to int.
>>> #Read about and/or(not(Boolean Operations) how it work
So a little change to get it to work.
h1 = range(0,3)
h2 = range (0,4)
m1 = range(0,6)
m2 = range(0,10)
mtime_range = (0,4)
def valid_mtime(mtime):
if len(mtime) not in mtime_range:
print 'Not correct lenght'
return
if (int(mtime[0]) in h1 and int(mtime[1]) in h2) and (int(mtime[2]) in m1 and int(mtime[3]) in m2):
print 'true'
else:
print 'false'
'''Out-->
valid_mtime('0059')
true
valid_mtime('0060')
false
valid_mtime('24')
Not correct lenght
'''
Though there are advantages to using full IDEs such as netbeans
Vega is not talking about big editors like netbean that support many languages. Pyscripter,SPE are small python editors that work out the box,just paste in code an run it. And will give a god error message and where in code if somthing goes wrong.
word1 = 'This is my car'
word2 = 'My car is fine'
diff_list = []
for item in word1:
if not item in word2:
diff_list.append(item)
print diff_list
And for index that i forget we can use vega code with a litte twist.
word1 = 'This is my car'
word2 = 'My car is fine'
diff_list = []
for item in word1:
if not item in word2:
diff_list.append(item)
print diff_list
for letter in diff_list:
index = str(diff_list).find(letter)
print( "letter %s is at index %s" % (letter, index))
'''Out-->
['T', 'h', 'm']
letter T is at index 2
letter h is at index 7
letter m is at index 12
'''
def common_letter():
#word1 = raw_input("Enter word1: ")
#word2 = raw_input("Enter word2: ")
word1 = 'This is my car'
word2 = 'My car is fine'
li1 = []
li2 = []
for letter1 in word1:
li1.append(letter1) #This is better
for letter2 in word2:
li2 += letter2
print li1 #Now you have two list with the word
print li2 #And nothing is compared
diff_list = [item for item in li1 if not item in li2]
#Can write it as a loop if this is hard to understand
print diff_list
common_letter()
>>> num = raw_input("Enter a number: ")
>>> l = []
>>> for item in range(int(num)):
... a = int(raw_input('Enter: '))
... l.append(a)
...
>>> l
[5, 6, 3, 4, 7]
>>>
Always use 4 space for indentations PEP 8 Here is a little help on how to trow more than one dice.
import random
possible = [2, 3, 4, 5, 6, 7, 8, 10, 12, 14, 16, 20, 24, 30, 34, 50, 100]
dice_number = int(raw_input('How many dice would you like to use: '))
size = int(raw_input('Please enter the size of the die you would like: '))
if size not in possible:
print
"""
Please check the Wikipedia Dice article to get possible dice sizes.
I'm going to give you a standard 6 sided die to try out.
"""
size = 6
rolltimes = int(raw_input('Please enter the number of times to roll: '))
dice = [x for x in range(1,size+1)]
rollval = []
dictionary = {}
for count in range(0,rolltimes):
for i in range(0,dice_number):
item = dice[random.randrange(len(dice))]
dictionary[item] = dictionary.get(item,0) + 1
items = dictionary.keys()
items.sort()
for item in items:
print "%-10s %d" % (item, dictionary[item])
To check for a valid email adress regular expression is a god tool.
import re
mail_input = raw_input("Enter your email: ")
if re.match(r"\b[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}\b\Z", mail_input, re.IGNORECASE):
print ("That is a valid email")
else:
print ("That email is not valid")
I'm an information security professional who's decided to teach myself python
Yes a good choice. I put together something that may in direction you describe.
import re
text = '''\
A fast and friendly dog.
email1@dot.net
myetest@online.no
My car is red.
han445@net.com
'''
find_email = re.findall(r'\b[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}\b',text,re.IGNORECASE)
print 'Text has %d email adress' % (len(find_email))
print find_email
for item in enumerate(find_email):
print 'Email #%s --> %s' % (item[0],item[1])
'''Out-->
Text has 3 email adress
['email1@dot.net', 'myetest@online.no', 'han445@net.com']
Email #0 --> email1@dot.net
Email #1 --> myetest@online.no
Email #2 --> han445@net.com
'''
#Python 3.x
find_email = re.findall(r'\b[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}\b',text,re.IGNORECASE)
print ('Text has %d email adresser' % (len(find_email)))
print (find_email)
for item in enumerate(find_email):
print ('Email #%s --> %s' % (item[0],item[1]))
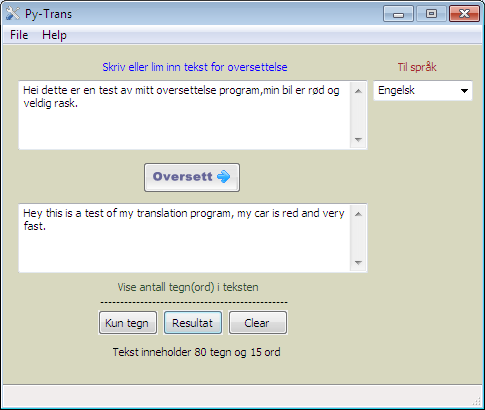
Hei fra norge. This is an almost impossible task without a good libary. I did a translation program a while ago where i use google translate API and wxpython as gui. Its work fine,still only in norwegian. Shall write gui fronend in englishs to. Did this a fun projects.you can try it out Py-trans
It just gave a message at the bottom of the gray PythonWin frame right where it says,"running the code file..." or something similar to that
Get a better editor than PythonWin. Pyscripter is good. Paste your kode inn,and you se a red line mark under line 7 for your code. It also give you and postion(25) if you try to run the code. Because at postion(25) there should be a : as Gribouillis pointet out.
IDLE 2.6.4
>>> exp = "1+2"
>>> exp
'1+2'
>>> string1 = exp.split("+")
>>> string1
['1', '2']
>>> print "Operator 1 is : " , op1
Operator 1 is :
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
print "Operator 1 is : " , op1
NameError: name 'op1' is not defined
#just to get and error message "NameError" because we have nor defiend op1.
>>> print "Operator 1 is: %s " % string1[0]
Operator 1 is: 1
So the finish script.
def start():
exp = "1+2"
string1 = exp.split("+")
print "Operator 1 is: %s" % string1[0]
print "Operator 2 is: %s" % string1[1]
start()
'''Out-->
Operator 1 is: 1
Operator 2 is: 2
'''
Post 2# my setup in gui2exe. I have done a lot with wxpython and py2exe(gui2exe + inno-setup) And it works on all windows version,no need for pepole to have python installed.
Is better that you post your script so can we test it out.
I think I should listen to your advice and also get python 2, so I'll be able to learn something at all.
Yes both Guido(python himself) and Alex Martelli say that beginner should start with python 2.x.
They have now hurry to advice pepole to use python 3.x,because is newer. In some year all will use python 3.x but no need to hurry upp,and refuse all code on net that is for python 2.x(for beginner is this code very important and books to)
The easy way is using 5min to install python 2.x. And see if you get it to work there,if it work rewrite to python 3.x.
The problem is that very few use python3.x yet. So getting help with python 3.x is much harder than for python 2.x
I have used 2to3 module to port python 2.x to python 3.x code,and it have work fine for the little i have tryed. For small script i have not much problem to rewrite to python 3.x
Most of us use python 2.x,because we need 3 party moduls like wxpython,Twisted,dangjo,py2exe...and so on.
No problem to have both python 2.x and python 3.x installed. Python 3.x is off course the right to go in the future,but for 3 party moduls future is still some years away.
By the way nowone will wirte code for you if you dont show som effort an post what you have done.