On June 20, 2024, Anthropic released the Claude 3.5 sonnet large language model. Claude claims it to be the state-of-the-art model for many natural language processing tasks, surpassing the OpenAI GPT-4o model.
My first test for comparing two large language models is their zero-shot text classification ability. In this article, I will compare the Antropic Claude 3.5 sonnet with the OpenAI GPT-4o model for zero-shot tweet sentiment classification.
So, let's begin without ado.
Importing and Installing Required Libraries
The following script installs the Anthropic and OpenAI libraries to access the corresponding APIs.
!pip install anthropic
!pip install openai
The script below imports the required libraries into your Python application.
import os
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import anthropic
from openai import OpenAI
Importing and Preprocessing the Dataset
We will use the Twitter US Airline Sentiment dataset to perform zero-shot classification. You can download the dataset from Kaggle.
The following script imports the dataset into a Pandas DataFrame.
## Dataset download link
## https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment?select=Tweets.csv
dataset = pd.read_csv(r"D:\Datasets\tweets.csv")
print(dataset.shape)
dataset.head()
Output:
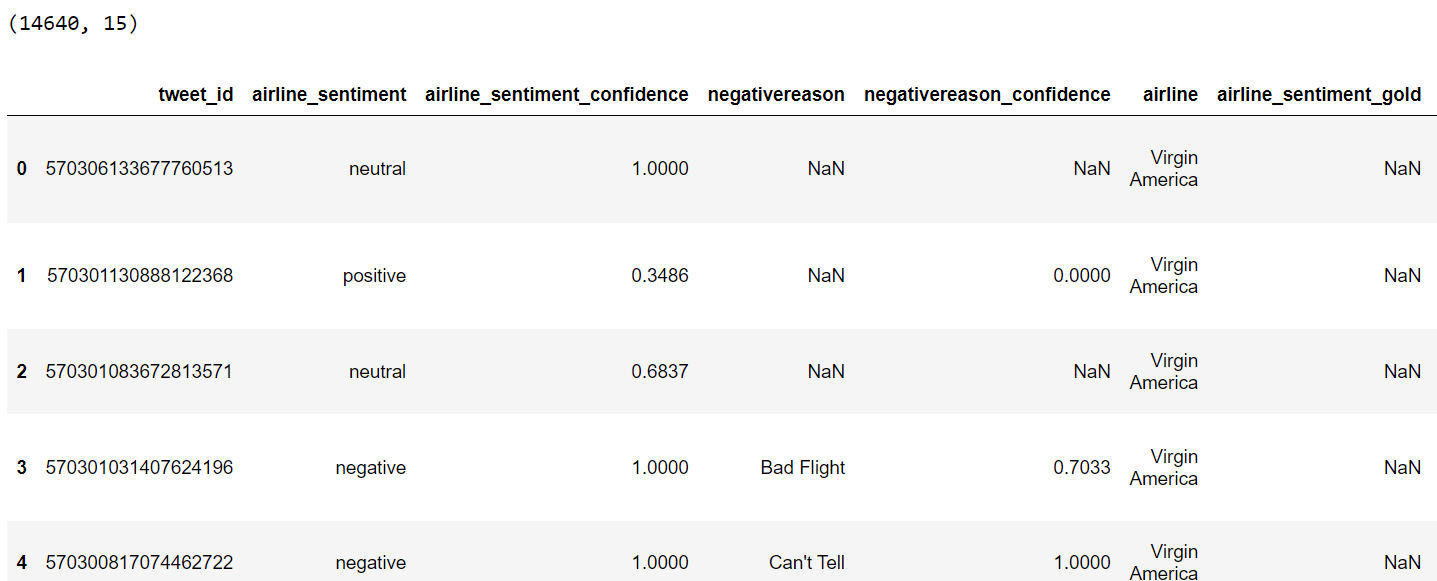
Tweet sentiment falls into three categories: neutral, positive, and negative. For comparison, we will filter 100 tweets. The neutral, positive, and negative categories will contain 34, 33, and 33 tweets, respectively.
# Remove rows where 'airline_sentiment' or 'text' are NaN
dataset = dataset.dropna(subset=['airline_sentiment', 'text'])
# Remove rows where 'airline_sentiment' or 'text' are empty strings
dataset = dataset[(dataset['airline_sentiment'].str.strip() != '') & (dataset['text'].str.strip() != '')]
# Filter the DataFrame for each sentiment
neutral_df = dataset[dataset['airline_sentiment'] == 'neutral']
positive_df = dataset[dataset['airline_sentiment'] == 'positive']
negative_df = dataset[dataset['airline_sentiment'] == 'negative']
# Randomly sample records from each sentiment
neutral_sample = neutral_df.sample(n=34)
positive_sample = positive_df.sample(n=33)
negative_sample = negative_df.sample(n=33)
# Concatenate the samples into one DataFrame
dataset = pd.concat([neutral_sample, positive_sample, negative_sample])
# Reset index if needed
dataset.reset_index(drop=True, inplace=True)
# print value counts
print(dataset["airline_sentiment"].value_counts())
Output:

Zero Shot Text Classification with GPT-4o
We will first perform zero-shot text classification with GPT-4o. Remember to get your OpenAI API key before executing the following script.
The script below defines a function find_sentiment() that accepts the client and model parameters. The client corresponds to the client, i.e., anthropic or OpenAI, while the model corresponds to Claude 3.5 Sonnet or GPT-4o.
The find_sentiment() function iterates through all the tweets from the filtered dataset and predicts sentiment for each tweet. The predicted sentiments are then compared with the actual sentiment values to determine the model's accuracy.
def find_sentiment(client, model):
tweets_list = dataset["text"].tolist()
all_sentiments = []
i = 0
exceptions = 0
while i < len(tweets_list):
try:
tweet = tweets_list[i]
content = """What is the sentiment expressed in the following tweet about an airline?
Select sentiment value from positive, negative, or neutral. Return only the sentiment value in small letters.
tweet: {}""".format(tweet)
sentiment_value = client.chat.completions.create(
model= model,
temperature = 0,
max_tokens = 10,
messages=[
{"role": "user", "content": content}
]
).choices[0].message.content
all_sentiments.append(sentiment_value)
i = i + 1
print(i, sentiment_value)
except Exception as e:
print("===================")
print("Exception occurred:", e)
exceptions += 1
print("Total exception count:", exceptions)
accuracy = accuracy_score(all_sentiments, dataset["airline_sentiment"])
print("Accuracy:", accuracy)
Next, we create an OpenAI client and pass the client object along with the gpt-4o model to predict sentiments.
%%time
client = OpenAI(
# This is the default and can be omitted
api_key = os.environ.get('OPENAI_API_KEY'),
)
model = "gpt-4o"
find_sentiment(client, model)
Output:
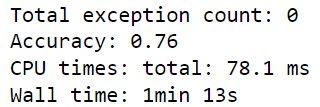
The above output shows that GPT-4o achieved an accuracy of 76%.
Zero Shot Text Classification with Claude 3.5-Sonnet
Let's now predict the sentiment for the same set of tweets using the Claude 3.5 sonnet model. We define the find_sentiment_claude() function which is similar to the find_sentiment() function, but predicts sentiments using the Claude 3.5 sonnet model.
def find_sentiment_claude(client, model):
tweets_list = dataset["text"].tolist()
all_sentiments = []
i = 0
exceptions = 0
while i < len(tweets_list):
try:
tweet = tweets_list[i]
content = """What is the sentiment expressed in the following tweet about an airline?
Select sentiment value from positive, negative, or neutral. Return only the sentiment value in small letters.
tweet: {}""".format(tweet)
sentiment_value = client.messages.create(
model= model,
max_tokens=10,
temperature=0.0,
messages=[
{"role": "user", "content": content}
]
).content[0].text
all_sentiments.append(sentiment_value)
i = i + 1
print(i, sentiment_value)
except Exception as e:
print("===================")
print("Exception occurred:", e)
exceptions += 1
print("Total exception count:", exceptions)
accuracy = accuracy_score(all_sentiments, dataset["airline_sentiment"])
print("Accuracy:", accuracy)
The script below calls the find_sentiment_claude() function using the anthropic client and the claude-3-5-sonnet-20240620 (the id for the Claude 3.5 sonnet) model.
%%time
client = anthropic.Anthropic(
# defaults to os.environ.get("ANTHROPIC_API_KEY")
api_key = os.environ.get('ANTHROPIC_API_KEY')
)
model = "claude-3-5-sonnet-20240620"
find_sentiment_claude(client, model)Output:
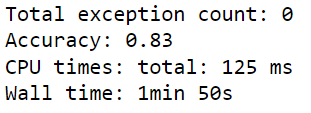
The above output shows that the Claude 3.5 Sonnet model achieved an accuracy of 83%, which is significantly better than the GPT-4o model.
Final Verdict
Here is an overall comparison between the Claude Sonnet 3.5 and the GPT-4o model.

Given the price, performance, and context window size, I prefer the Claude 3.5 Sonnet over other proprietary models such as GPT-4o.
Feel free to share your opinions. I would be very interested in any results you obtain using the two models.