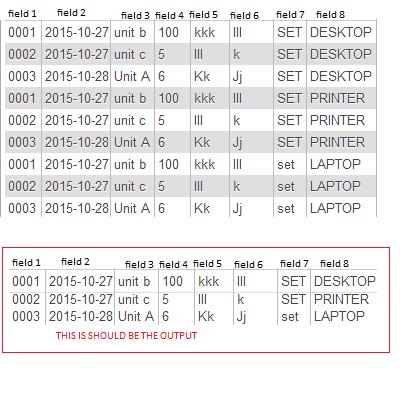
I added "DISTINCT" in my code. but seems the output is still the same, it have duplicate records. Thank u :D (note: I changed the field names and tables here)
SELECT DISTINCT b.field1, b.field2, b.field3, b.field4, c.field1, c.field2, c.field3 from tbl1 b inner join tbl2 c on b.logid = c.logid WHERE b.logid ='".$_SESSION['login_id']."'