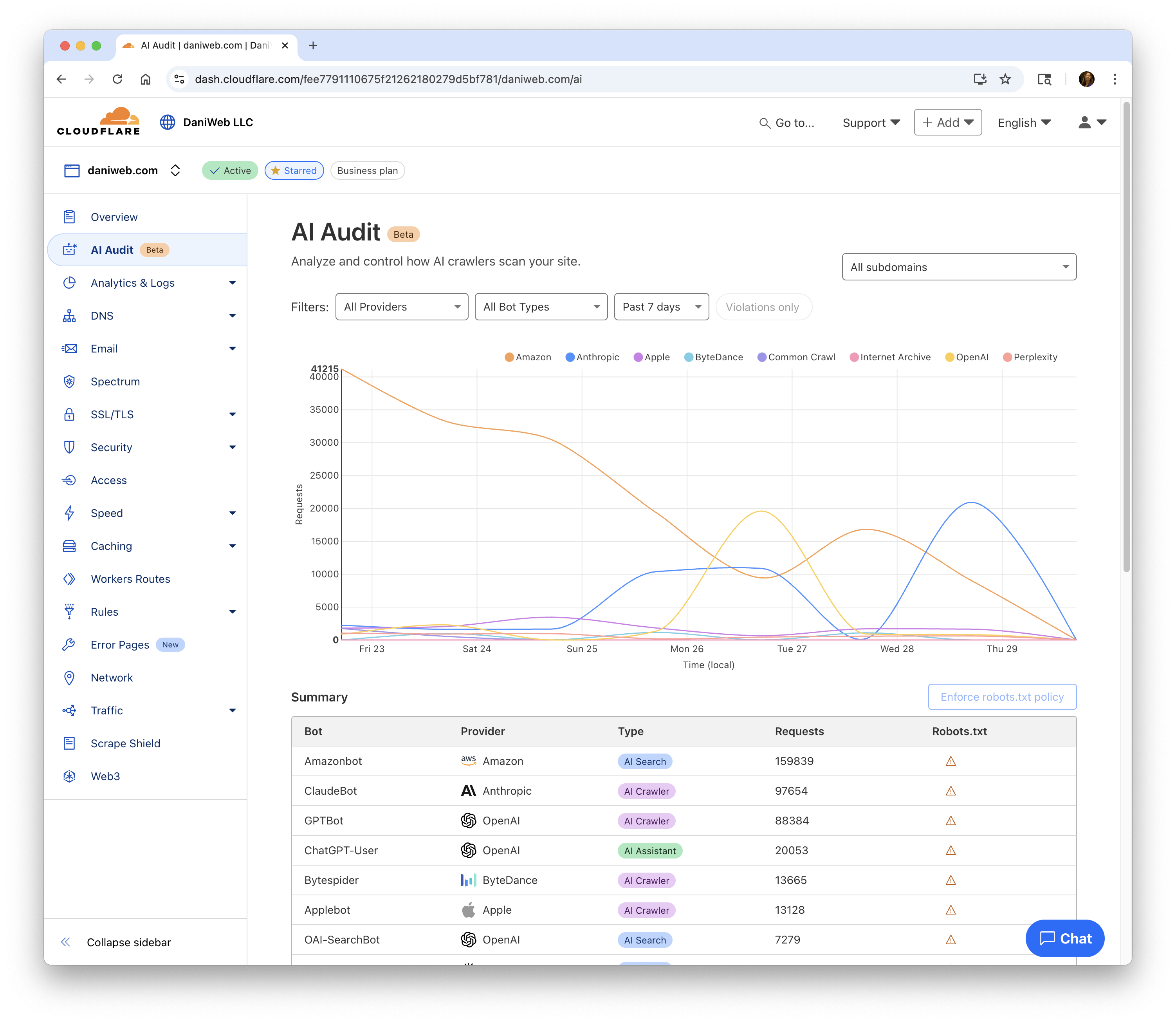
Digital Publishers:
Do you block AI bots either via robots.txt, with HTTP 403s, or both? Why or why not?
Currently on the fence about it and looking to get opinions from other publishers as to their reasoning and how it's influenced their SEO, etc.
We're a friendly, industry-focused community of developers, IT pros, digital marketers, and technology enthusiasts meeting, networking, learning, and sharing knowledge.