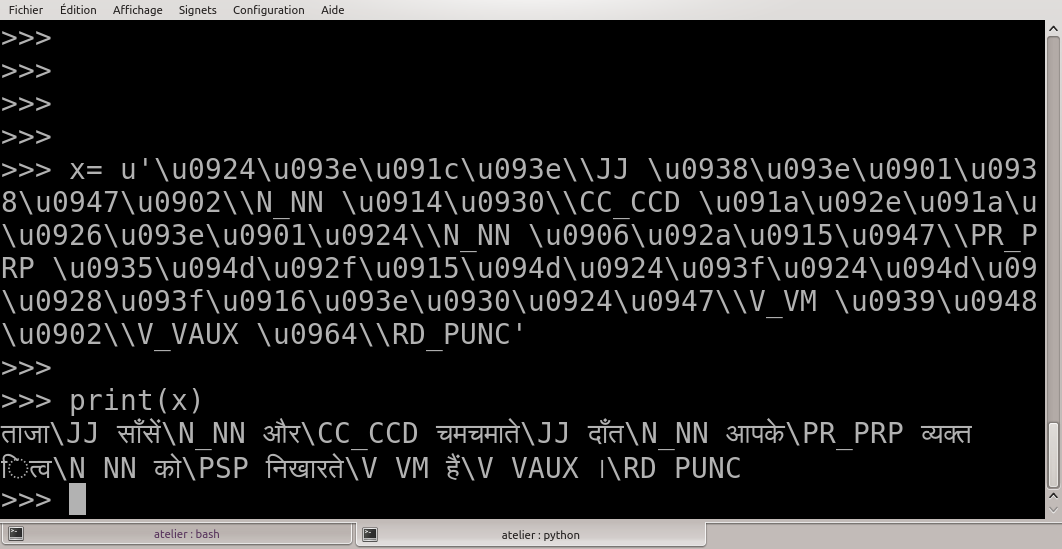
I think your data is not valid python code. For example to read the hindi part, I had to replace all the \N with \ \N (double backslash) otherwise python would not read the unicode string.
Here is what I get when I print the hindi part:
ताजा\JJ साँसें\N_NN और\CC_CCD चमचमाते\JJ दाँत\N_NN आपके\PR_PRP व्यक्तित्व\N_NN को\PSP निखारते\V_VM हैं\V_VAUX ।\R
does it have something to do with what you want ?
Your question doesn't mean much. The unicode does not have to be converted to the target language. It is already in that language. What you want is probably to display the unicode with the language's human glyphs, which is something else. For this, the print function should work, for example I don't know hindi but
>>> y = u'\u0924\u093e\u091c\u093e'
>>> print(y)
ताजा
>>>
It would be great if you could attach a small file to a post containing your exact data (for example a csv file in UTF8. You can zip the file to attach it to a post).
Edit: it's too bad, we still have this bug with the unicode characters in the forum!