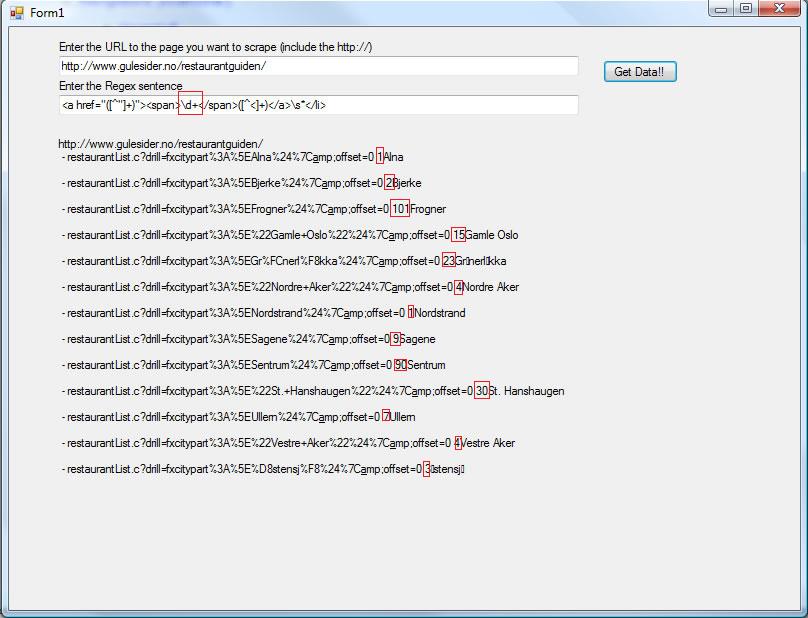
Hei...i tried to make a program to scraping html, all is worked but i have a problem in the regex senteces but im not sure,
<a href="([^"]+)"><span>\d+</span>([^<]+)</a>\s*</li>this sentences should to show me just link and text and not \d+ but when I debugging i can se that come with all sentences
[0] = {<a href="restaurantList.c?drill=fxcitypart%3A%5EAlna%24%7C&offset=0"><span>1</span>Alna</a>
</li>}im not sure if is a regex sentences fail or i need a function for take out