Tracing AI-generated content in online news articles with corpus linguistics

A query in the 'News on the Web' Corpus reveals that the use of the word 'tapestry' in online articles has more than doubled last year – from 3,085 instances in 2022 to 7,891 instances in 2023
“Today, we delve into the rich tapestry—” Stop. Don't worry. This text has not been generated by a Large Language Model (LLM). Much of what you find on the internet these days, however, is. This article will help you distinguish between the two. You’ll find out why ChatGPT is over 1,000 times more likely to use certain words than a human, what those words are, and other signs to look out for when trying to find out whether the article you are reading is AI-generated.
Tracing AI-Generated Content with Corpus Linguistics
People who work a lot with LLMs have noticed that they tend to overuse certain expressions, and may have developed an eye for spotting AI-generated content. Especially ChatGPT has been criticized for its undeniable preference for words such as ‘delve’ and ‘tapestry’. Hence, when I was trying to find out how common it is among journalists to write their articles with the help of LLMs, I looked for those words as a clue.
Over a decade after completing my master’s thesis, I decided to revisit the world of corpus linguistics. I examined the News on the Web (NOW) corpus at english-corpora.org, which currently comprises over 18.5 billion words from English-language online newspapers and magazines, from 2010 to the present. This corpus allows users to check the frequency of certain words over time, the context in which they occur, and make comparisons. For example, a search for ‘covfefe’ in the NOW corpus shows 1,241 occurrences, with none between 2010 and 2016, 792 in 2017, and considerably fewer since:

Timeline of occurrences in the corpus
The logic here is clear: as the material is comprised of news articles, the use of certain expressions may peak in years when they occur in the context of some media debate. However, the words I looked into to trace ChatGPT in the corpus are not related to any specific current issue. Although some meming has been going on about LLM’s preference for certain words, there are not many news articles dealing with this phenomenon.
Examining the context in which ‘tapestry’ appears in recent examples reveals that it is indeed a non-topical and unironic use of the expression:

The context of the 27 lastest occurences of ‘tapestry’ in the NOW corpus
Yet, the frequency of ‘tapestry’ in news articles has risen dramatically within just one year, from 3,085 instances in 2022 to 7,891 instances in 2023. And the word is in good company. ‘Multifaceted’ records a 62% increase (from 4,217 to 6,834) and ‘delve’ an increase of 92%:

The use of the word ‘delve’ also steeply increased from 2022 to 2023
One might argue that there is a general trend towards an increase in occurrences, as e.g., ‘delve’ only appeared 630 times in 2010. The obvious reason is that more online content is created today than 10 or 15 years ago, leading to a massive difference in the total size of the 2010 corpus compared to the 2023 corpus. The metric to focus on is the annual development, which in the case of ‘delve’ has increased almost every year until 2018, but has never shown anything near a 92% increase within just one year before.
So, what explains this explosion in the use of these words in online news articles? I believe it’s related to AI-generated content.
The Words ChatGPT Uses Too Much
As already mentioned, experienced users have long noticed overused terms and have practice spotting them. However, there is also an empirical basis for this. Jordan Gibbs analyzed 1 million words of GPT-4 output on a variety of topics, then compared this dataset to a database for word frequency in English. This analysis identified the words that ChatGPT is most likely to overuse.
Interestingly, some of these words were names – e.g., Elara, which is 3,504 times more likely to occur in generated text. Gibbs cleaned up the data to remove names and "other creative writing jargon" to compile a list of the most over-prevalent words in GPT-4:
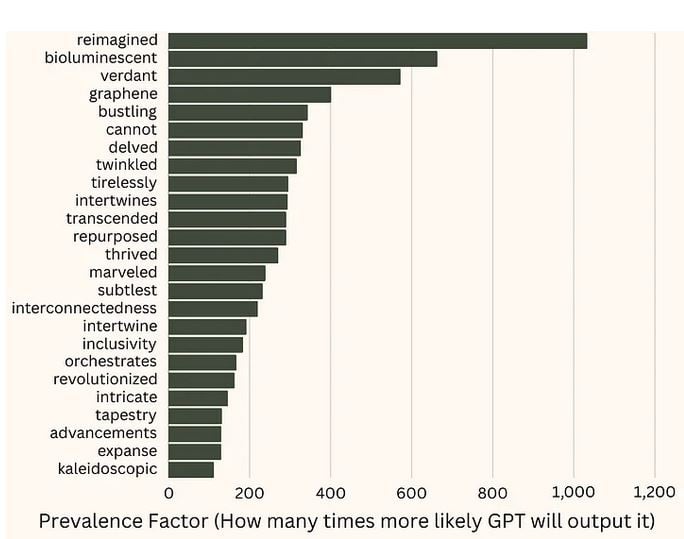
The most over-prevalent words in GPT-4 | Source: Jordan Gibbs @ Medium
As you can see, the most overused word is ‘reimagined,’ which ChatGPT is over 1,000 times more likely to use than a human. ‘Delve’ ranks in the 7th place. You can access the unfiltered top 100 expressions here.
More Givaways that Text was Written by an LLM
Other clear giveaways for AI-generated texts (that have yet to be empirically examined) are frequent occurrences of comparative structures (e.g., ‘not only …, but also…’), uniform paragraphs with similar length and phrasing, as well as a boundless enthusiasm for lists.
As our expedition into corpus linguistics has shown, AI-generated text is already big out there, not only in the form of bot-comments on social media—but also in journalism and online news. For now, the best way to avoid wasting your time on reading generative content may be to learn how to recognize it quickly.
To me personally, the most certain giveaway of an AI-generated text is eloquent vocabulary combined with soulless content. Hence, if web journalists don't want their content to be easily identified as AI copy, they will have to do more than just edit out some ‘tapestry’.