True, that should work... theoretically. The big issue is that since they moved it, it uses dynamic positioning based on window size. So I would have to do that on every WM_RESIZE event. However I suppose that the user shouldn't be resizing their window all that frequently, so I guess your solution is sufficient.
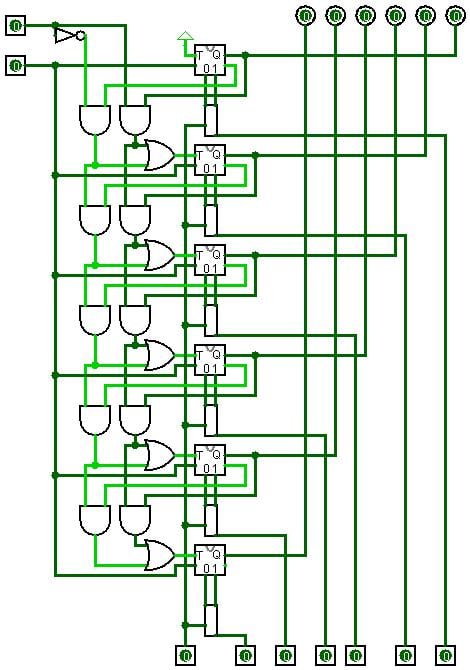
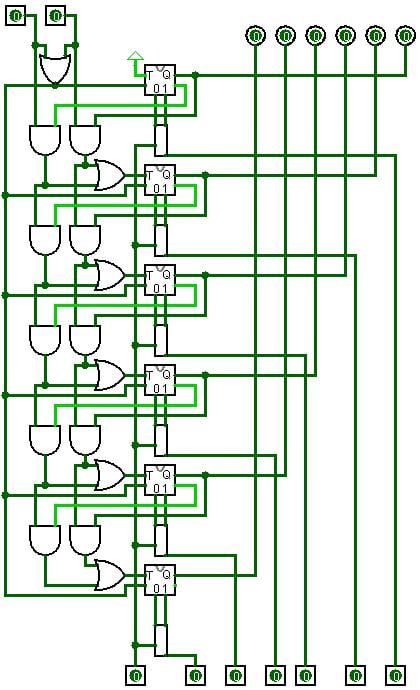
Labdabeta 182 Posting Pro in Training Featured Poster
Labdabeta 182 Posting Pro in Training Featured Poster