In previous articles, I explained how to use natural language to interact with PDF documents and SQL databases, using the Python LangChain module and OpenAI API.
In this article, you will learn how to use LangChain and OpenAI API to create a question-answering application that allows you to retrieve information from YouTube videos. So, let's begin without ado.
Importing and Installing Required Libraries
Before diving into the code, let's set up our environment with the necessary libraries.
We will use the Langchain module to access the vector databases and execute queries on large language models to retrieve information about YouTube videos. We will also employ the YouTube Transcript API for fetching video transcripts, the Pytube library for downloading YouTube videos, and the FAISS vector index for efficient similarity search in large datasets.
The following script installs these modules and libraries.
!pip install -qU langchain
!pip install -qU langchain-community
!pip install -qU langchain-openai
!pip install -qU youtube-transcript-api
!pip install -qU pytube
!pip install -qU faiss-cpu
The script below imports the required libraries into our Python application.
from langchain_community.document_loaders import YoutubeLoader
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain_core.documents import Document
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
import os
Creating Text Documents from YouTube Videos
The first step involves converting YouTube video content into text documents. You can use the from_youtube_url() method of the LangChain YoutubeLoader class, which extracts video transcripts and additional video information. You need to pass a list of YouTube video URLs to this method.
The following script converts YouTube videos into text documents and prints the transcript of the first YouTube video in our list of YouTube videos.
urls = [
"https://www.youtube.com/watch?v=C5BkxbbLbIY",
"https://www.youtube.com/watch?v=7qbJvucsU-Y",
"https://www.youtube.com/watch?v=DNNMS7l6A-g",
"https://www.youtube.com/watch?v=1rh-P2N0DR4",
"https://www.youtube.com/watch?v=AW2kppo3rtI",
"https://www.youtube.com/watch?v=lznP52OEpQk",
"https://www.youtube.com/watch?v=ul14Qs24-s8",
"https://www.youtube.com/watch?v=sB3N0ZqjPyM",
"https://www.youtube.com/watch?v=JG1zkvwrn3E"
]
docs = []
for url in urls:
docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load())
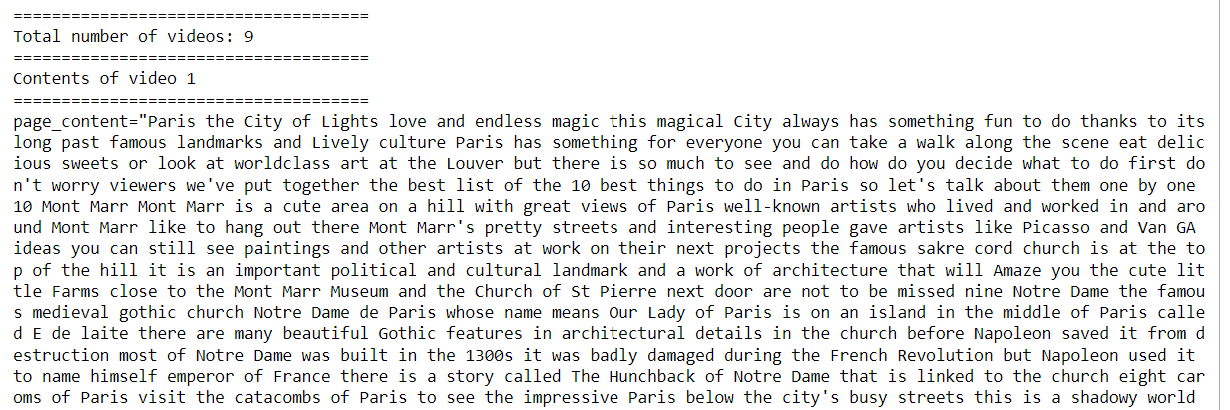
print("=====================================")
print(f"Total number of videos: {len(docs)}")
print("=====================================")
print("Contents of video 1")
print("=====================================")
print(docs[0])
Output:
<img src="images\image1.png">
The transcript of each video is stored in a LangChain document format, as you can see from the following script.
type(docs[0])
Output:
langchain_core.documents.base.Document
Once you have text in the LangChain document format, you can split it using any LangChain splitter, create text embeddings, and use it for retrieval augmented generation like any other text document. Let's see these steps.
Splitting and Embedding YouTube Video Documents
To handle large documents and prepare them for retrieval, we split them into smaller chunks using the LangChain RecursiveCharacterTextSplitter. This facilitates more efficient processing and embedding.
The embeddings are generated using OpenAIEmbeddings, which transform the text chunks into numerical vectors. These vectors are stored in a FAISS vector index, enabling fast and efficient similarity searches.
openai_key = os.environ.get('OPENAI_KEY2')
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(openai_api_key = openai_key)
vector = FAISS.from_documents(documents, embeddings)
Question Answering with YouTube Videos
The rest of the process is straightforward. We create an object of the ChatOpenAI LLM and define a retriever that will retrieve the documents that match our query from the FAISS vector index.
llm = ChatOpenAI(
openai_api_key = openai_key ,
model = 'gpt-4',
temperature = 0.5
)
retriever = vector.as_retriever()
Next, we will create two chains. The first chain, history_retriever_chain, will be responsible for maintaining memory. The input to this chain will be the chat history in the form of a list of messages and the user prompt. The output from this chain will be context relevant to the user prompt and chat history. The following script defines the history_retriever_chain.
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up in order to get information relevant to the conversation")
])
history_retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
Next, we will create a document_chain. This chain will receive the user prompt and chat history as input, as well as the output context from the history_retriever_chain.
prompt = ChatPromptTemplate.from_messages([
("system", "Answer the user's questions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}")
])
document_chain = create_stuff_documents_chain(llm, prompt)
Finally, we will create our retrieval_chain that combines the history_retriever_chain and document_chain to retrieve the final response from the LLM.
In the following script, we ask the LLM a question about the top three things to do in Paris. Notice that we did not ask the LLM to return information about the top three things to do in Paris. The LLM is intelligent enough to infer from the context containing YouTube video documents that we are asking a question about the top three things to do in Paris.
retrieval_chain = create_retrieval_chain(history_retriever_chain, document_chain)
result = retrieval_chain.invoke({
"chat_history": [],
"input": "What are the top 3 things to do?"
})
print(result['answer'])
Output:
The top three things to do based on the context are:
1. Visiting the top of the Ark (Arc de Triomphe) for a view of the city.
2. Having a picnic near the Eiffel Tower with food from a local market.
3. Renting bikes and riding around the city with no specific destination.
A Command Line YouTube Question Answering Chatbot
Now that we know how to get answers to our questions related to YouTube videos, we can create a simple command-line application for question-answering. To do so, we define an empty chat_history list and the generate_response_with_memory() method that accepts a user prompt as a parameter.
Inside the method, we generate a response for the user prompt and then append both the input prompt and response to the chat_history list. Thanks to the' chat_history' list, the command line application will be able to answer follow-up questions.
chat_history = []
def generate_response_with_memory(query):
result = retrieval_chain.invoke({
"chat_history": chat_history,
"input": query
})
response = result['answer']
chat_history.extend([HumanMessage(content = query),
AIMessage(content = response)])
return response
The following script executes a while loop. Inside the loop, the user asks a question that is passed on to the generate_response_with_memory() method. The method's response is displayed on the console. The process continues until the user types bye.
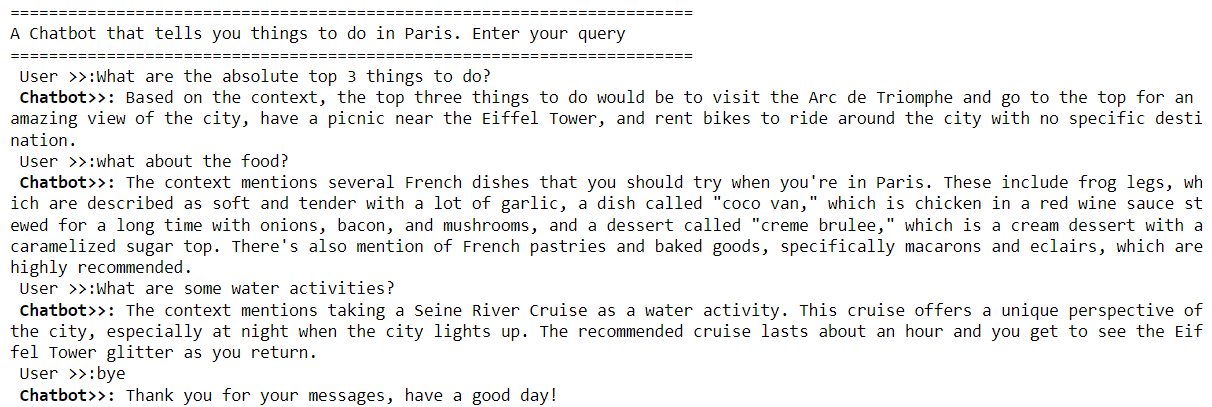
print("=======================================================================")
print("A Chatbot that tells you things to do in Paris. Enter your query")
print("=======================================================================")
query = ""
while query != "bye":
query = input("\033[1m User >>:\033[0m")
if query == "bye":
chat_history = []
print("\033[1m Chatbot>>:\033[0m Thank you for your messages, have a good day!")
break
response = generate_response_with_memory(query)
print(f"\033[1m Chatbot>>:\033[0m {response}")
Output:
Conclusion
YouTube videos are a valuable source of information. However, not everyone has time to watch complete YouTube videos. In addition, a viewer might only be interested in certain parts of videos. The YouTube question-answering chatbot allows you to chat with any YouTube videos. I encourage you to test this application and let me know your feedback.