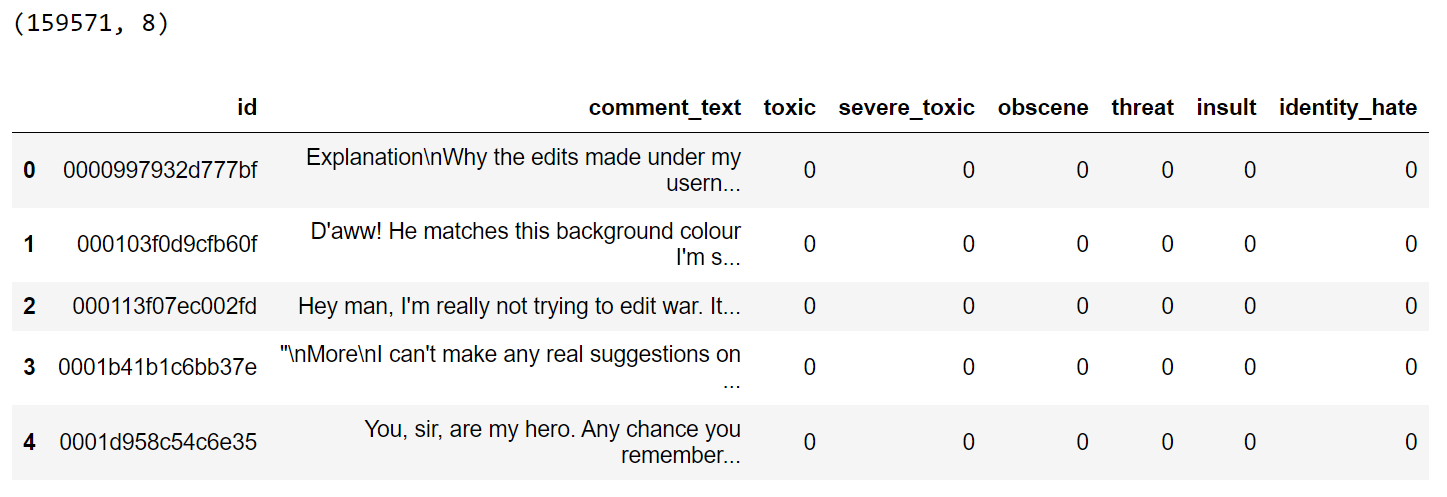
In this article, you will learn how to track faces within a video using the Python DeepFace library. Additionally, you'll discover how to include portions of the video background in face tracking by implementing custom methods that utilize the DeepFace library's extract_faces() method for face extraction.
I explained how to extract faces from videos using the Python DeepFace library in [one of my previous articles. However, I recently encountered a couple of issues when working with DeepFace's extract_faces() method:
- This method does not allow the extraction of portions of the face background. It also sometimes ignores the boundary features of a face, such as ears, hair, etc.
- Videos created by stitching together faces extracted by DeepFace are often jittery, as the extracted frames frequently miss some boundary facial features.
In this article, I provide solutions to these two problems.
It is pertinent to mention that OpenCV library provides functionalities for video tracking. However, they use very naive methods, which are less accurate than deep learning methods provided by the DeepFace library. Hence, I preferred DeepFace over OpenCV.
The following script installs the DeepFace and MoviePy libraries. The DeepFace library will be used to extract faces from videos. You will use the MoviePy library to create a modified video that contains facial regions by stitching together individual image frames.
! pip install deepface
! pip install moviepyThe script imports the Python libraries required to run the code in …