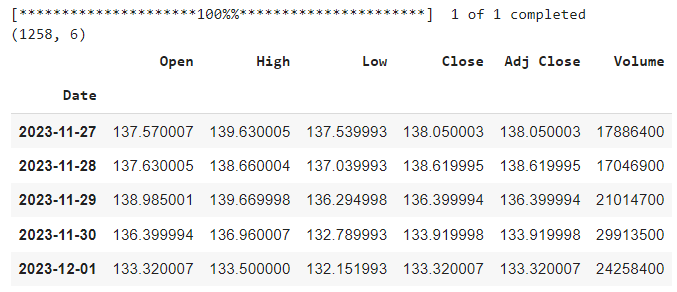
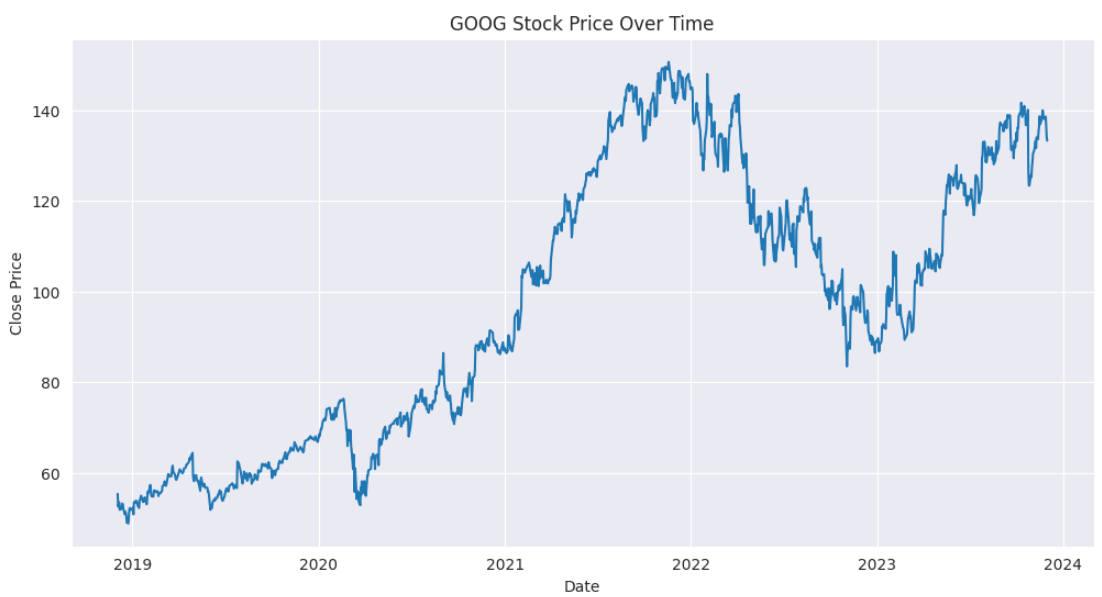
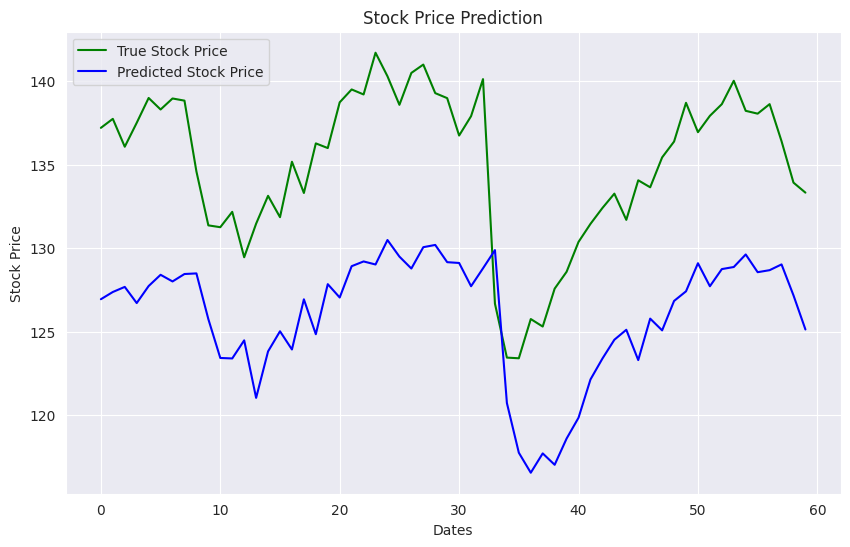
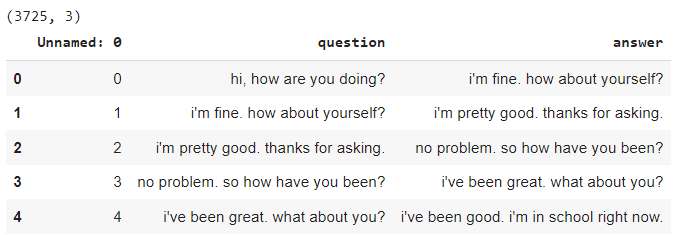
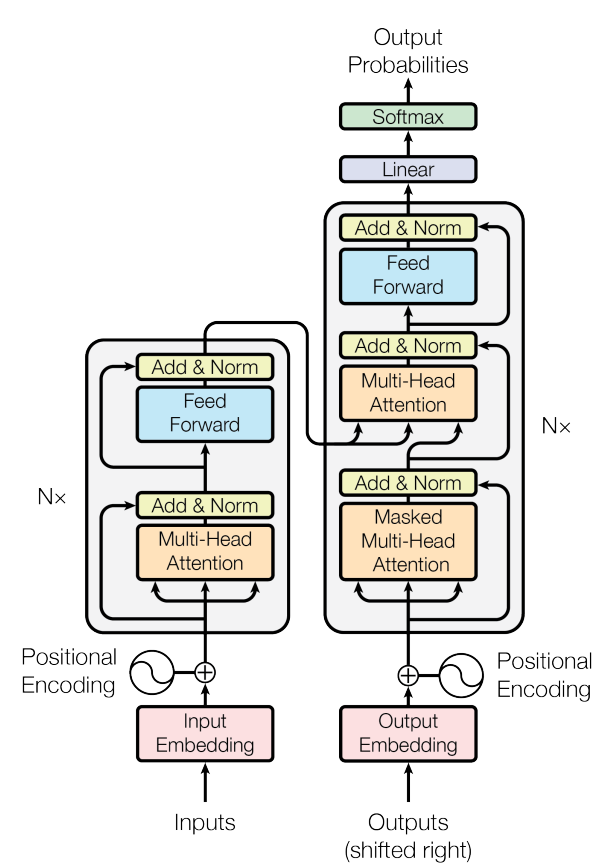
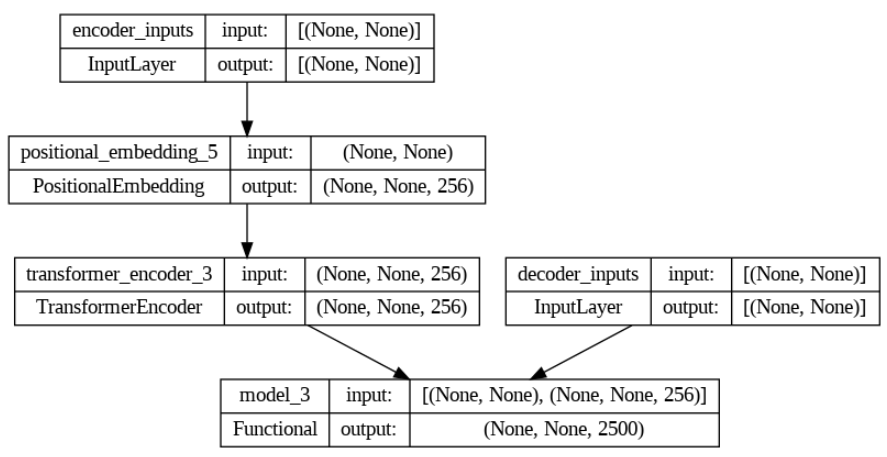
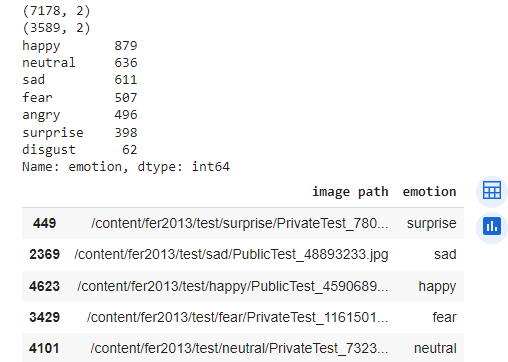
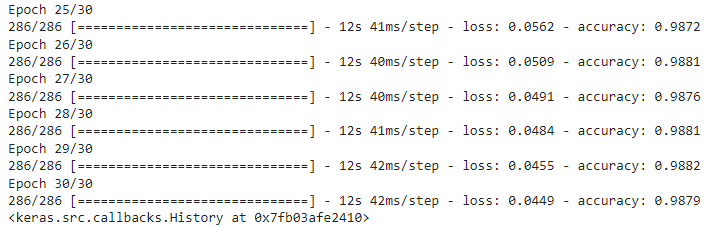
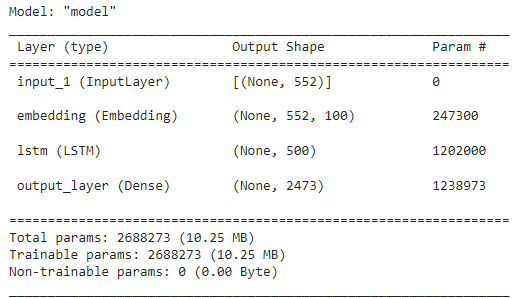
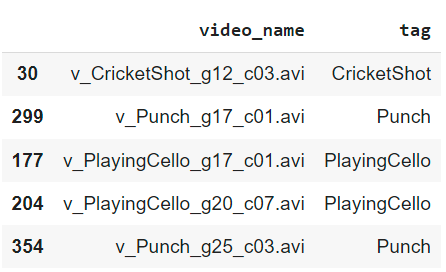
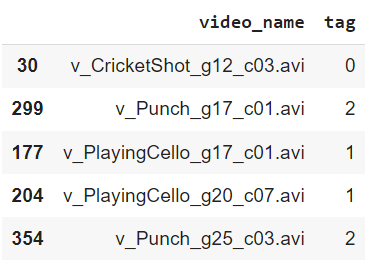
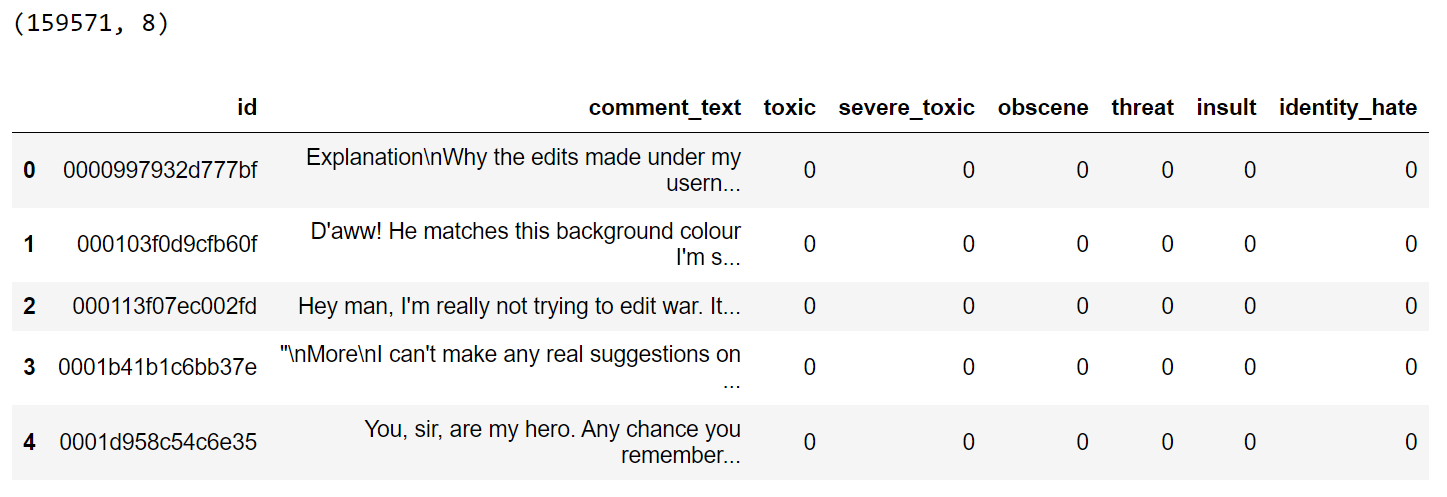
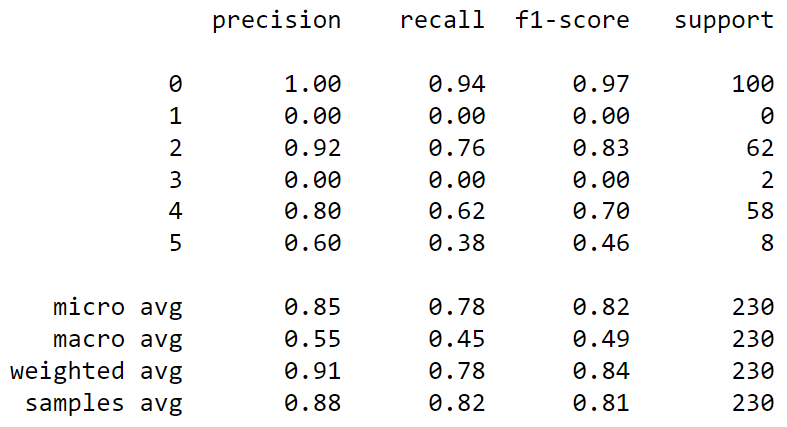
As a researcher, I have often found myself buried under a mountain of research articles, each promising insights and breakthroughs crucial for my work. The sheer volume of information is overwhelming, and the time it takes to extract the relevant data can be daunting.
However, extracting meaningful information from research papers has become increasingly easier with the advent of large language models. Nevertheless, interacting with large language models, particularly for querying custom data, can be tricky since it requires intricate code.
Fortunately, with the introduction of the Python Langchain module, you can query complex language models such as OpenAI's GPT-4 in just a few lines of code, offering a lifeline to those of us who need to sift through extensive research quickly and efficiently.
This article will explore how the Python Langchain module can be leveraged to extract information from research papers, saving precious time and allowing us to focus on innovation and analysis. You can employ the process explained in this article to extract information from any other PDF document.
Before diving into automated information extraction, we must set up our environment with the necessary tools. Langchain, OpenAI, PyPDF2, faiss-cpu, and rich are the libraries that will form the backbone of our extraction process. Each serves a unique purpose:
-
Langchain: Facilitates the access and chaining of language models and vector space models to perform complex tasks.
-
OpenAI: Provides access to OpenAI’s powerful language models.
-
PyPDF2: A library …