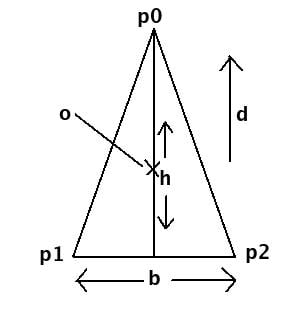
You don't need all the trig stuff, but the principle is OK. See attached diagram for a guide to what each variable in these expressions is. Assuimg your triangle is isocoles; and is defined as having a base ( scalar ), height( scalar ), origin/centerpoint ( point ) and direction ( vector ).
ASIDE: the first thing you should do when using OpenGL is to write or obtain a library for basic vector and matrix operations; it will make your life a lot, lot easier if you do so. See the dif between the vector implementation and component-wise implementation given.
VECTORS:
Given, origin = o, direction = d, base = b and height = h:
d_n = normalize( d )
pd_n = perp( d_n )
p0 = o + ( d_n * (h/2) )
p2 = o - ( d_n * (h/2) ) + ( pd_n * (b/2) )
p2 = o - ( d_n * (h/2) ) - ( pd_n * (b/2) )NOTE: the vector operations normalize and perp will be provided by any math/vector library worth mentioning, they are shown in full in the component method below, though.
COMPONENTS:
Given, origin = o, direction = d, base = b and height = h:
// this is how normalization looks component-wise
d_l = sqrt( (d[x]*d[x]) + (d[y]*d[y]) )
d_n[x] = d[x]/d_l
d_n[y] = d[y]/d_l
// this is how perp(endicular) looks component-wise
pd_n[x] = d_n[y]
pd_n[y] = -d_n[x]
p0[x] = o[x] + ( d_n[x] * (h/2) )
p0[y] …